Objectifs d’apprentissage
- Porter des jugements sur la taille de l’erreur-type de l’estimation à partir d’un nuage de points
- Calculer l’erreur-type de l’estimation à partir d’erreurs de prédiction
- Calculer l’erreur-type à l’aide de la corrélation de Pearson
- Estimer l’erreur-type de l’estimation à partir d’un échantillon
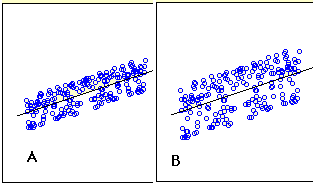
L’erreur type de l’estimation est une mesure de la précision des prédictions. Rappelons que la droite de régression est la droite qui minimise la somme des écarts au carré de la prédiction (également appelée erreur de la somme des carrés). L’erreur type de l’estimation est étroitement liée à cette quantité et est définie ci-dessous :
\
Supposons que les données de la table \(\PageIndex{1}\) sont les données d’une population de cinq paires \(X\), \(Y\).
La dernière colonne montre que la somme des erreurs de prédiction au carré est \(2,791\). Par conséquent, l’erreur-type de l’estimation est
\
Il existe une version de la formule de l’erreur-type en termes de corrélation de Pearson:
\
où \(ρ\) est la valeur de population de la corrélation de Pearson et \(SSY\) est
\
Pour les données du tableau \(\PageIndex{1}\), \(µ_Y =2,06\), \ (SSY = 4,597\) et \(ρ = 0,6268\). Par conséquent,
\
qui est la même valeur calculée précédemment.
Des formules similaires sont utilisées lorsque l’erreur type de l’estimation est calculée à partir d’un échantillon plutôt que d’une population. La seule différence est que le dénominateur est \(N-2\) plutôt que \(N\). La raison pour laquelle \(N-2\) est utilisé plutôt que \(N-1\) est que deux paramètres (la pente et l’interception) ont été estimés afin d’estimer la somme des carrés. Les formules pour un échantillon comparable à celles d’une population sont présentées ci-dessous.
\
\
\