Vzdělávací Cíle
- úsudky o velikosti standardní chyby odhadu od bodový graf
- Výpočet standardní chyby odhadu na základě chyby predikce
- Výpočet standardní chyby pomocí Pearsonova korelace
- Odhad standardní chyby odhadu na základě vzorku
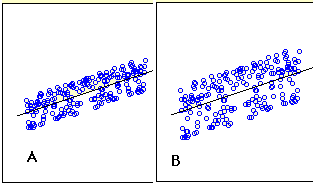
standardní chyba odhadu je měřítkem přesnosti předpovědí. Připomeňme, že regresní čára je čára, která minimalizuje součet čtvercových odchylek predikce(také nazývaná součet čtverců chyba). Standardní chyba odhadu je úzce souvisí s množství a je definována níže:
\
Předpokládat, že data v Tabulce \(\PageIndex{1}\) jsou data z populace o pět \(X\), \(Y\) párů.
poslední sloupec ukazuje, že součet čtvercových chyb predikce je \(2.791\). Proto, standardní chyba odhadu je
\
k Dispozici je verze vzorce pro standardní chyba, pokud jde o Pearsonův korelační:
\
, kde \(ρ\), je populace hodnota Pearsonova korelace a \(SSY\) je
\
Pro data v Tabulce \(\PageIndex{1}\), \(µ_Y = 2.06\), \(SSY = 4.597\) a \(ρ= 0.6268\). Proto
\
což je stejná hodnota vypočtená dříve.
podobné vzorce se používají, když je standardní chyba odhadu vypočtena spíše ze vzorku než z populace. Jediným rozdílem je, že jmenovatel je spíše \(N-2\) než \(N\). Důvod \(N-2\) se používá spíše než \(N-1\) je, že dva parametry (sklon a intercept) byly odhadnuty za účelem odhadu součtu čtverců. Vzorce pro vzorek srovnatelný s vzorci pro populaci jsou uvedeny níže.
\
\
\