학습 목표
- 판단을 내릴 수 있도의 크기에 대한 표준 오류의 추정에서 scatter plot
- 계산 표준의 오류를 기반으로 예상의 오류에 대한 예측
- 계산 표준을 사용하여 오류 Pearson’s correlation
- 예상한 표준 오류의 견적을 기반으로 샘플
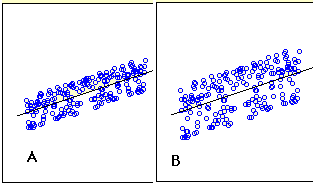
표준 오류의 견적의 측정의 정확도를 예측하고 있습니다. 회귀선은 예측의 제곱 편차(제곱 합 오차라고도 함)의 합을 최소화하는 선이라는 것을 상기하십시오. 표준 오류의 예상과 밀접한 관련이 수량과는 다음과 같이 정의됩니다:
\
정 데이터에서는 테이블\(\PageIndex{1}\)는 데이터에서 인구의 다섯\(X\),\Y(\)쌍이다.
마지막 열은 예측의 제곱 오차의 합이\(2.791\)임을 보여줍니다. 따라서,표준 오류의 견적입니다.
\
의 버전이 있는 수식에 대한 표준 오류 측면에서 피어슨 상관 관계:
\
어디\(ρ\)인구의 가치 피어슨 상관관계 및\(SSY\)
\
의 데이터에 대한 테이블\(\PageIndex{1}\),\(µ_Y=2.06\),\(SSY=4.597\)및\(ρ=0.6268\). 따라서
\
이는 이전에 계산 된 것과 동일한 값입니다.
추정치의 표준 오차가 모집단이 아닌 표본에서 계산 될 때 유사한 공식이 사용됩니다. 유일한 차이점은 분모가\(N\)보다는\(N-2\)라는 것입니다. 는 이유\(N-2\)를 사용하기보다는\(N-1\)는 두 개의 매개변수(기울기와 절편)것으로 추정되었다 추정하기 위해 합의 사각형입니다. 모집단에 대한 것과 비교할 수있는 샘플의 수식이 아래에 나와 있습니다.나는 이것을 할 수 없다.