Tanulási Célok
- ítélje meg a méret a standard hiba a becslés a scatter plot
- Kiszámolja a standard hiba, hogy a becslés alapján hibák előrejelzés
- Kiszámolja a standard hiba segítségével a Pearson-féle korrelációs
- a Becslés standard hibája a becslés minta alapján
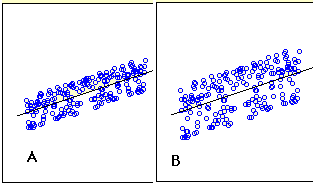
a becslés standard hibája az előrejelzések pontosságának mértéke. Emlékezzünk vissza, hogy a regressziós vonal az a vonal, amely minimalizálja a négyzetes eltérések összegét a becslés (más néven a négyzetek összege hiba). A becslés standard hibája szorosan kapcsolódik ehhez a mennyiséghez, és az alábbiakban definiáljuk:
\
feltételezzük, hogy a \(\PageIndex{1}\) táblázatban szereplő adatok öt \(X\), \(Y\) pár populációjából származnak.
az utolsó oszlop azt mutatja, hogy a predikciós négyzetes hibák összege \(2.791\). Ezért a becslés standard hibája
\
a standard hibának van egy változata a Pearson korrelációja szempontjából:
\
ahol \(ρ\) a Pearson korrelációjának populációs értéke, és \(SSY\)
\
a \(\PageIndex{1}\) táblázatban szereplő adatok esetében \(µ_Y = 2.06\), \(ssy = 4,597\) és \(ρ= 0,6268\). Ezért
\
, amely ugyanaz az érték, amelyet korábban kiszámítottak.
hasonló képleteket használnak, ha a becslés standard hibáját egy mintából, nem pedig populációból számítják ki. Az egyetlen különbség az, hogy a nevező \(N-2\) helyett \(N\). Az OK \(N-2\) helyett \(N-1\), hogy két paraméter (a lejtő és a metszés) becsülték annak érdekében, hogy megbecsülni az összeg négyzetek. Az alábbiakban egy populációhoz hasonló minta képleteit mutatjuk be.
\
\
\