læringsmål
- lav vurderinger om størrelsen på standardfejlen i estimatet fra et scatter-plot
- Beregn standardfejlen i estimatet baseret på forudsigelsesfejl
- Beregn standardfejlen ved hjælp af Pearsons korrelation
- skøn standardfejlen i estimatet baseret på en prøve af estimatet
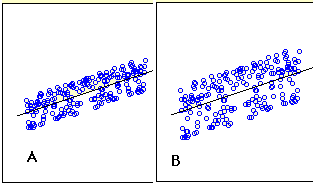
estimatets standardfejl er et mål for forudsigelsens nøjagtighed. Husk at regressionslinjen er den linje, der minimerer summen af kvadrerede afvigelser af forudsigelse (også kaldet summen af kvadrat fejl). Estimatets standardfejl er tæt knyttet til denne mængde og er defineret nedenfor:
\
Antag dataene i tabel \(\Sideindeks{1}\) er dataene fra en population på fem \(H\), \(Y\) par.
den sidste kolonne viser, at summen af de kvadratiske fejl i forudsigelsen er \(2.791\). Derfor er standardfejlen i estimatet
\
der er en version af formlen for standardfejlen med hensyn til Pearsons korrelation:
\
hvor \(prisT\) er befolkningsværdien af Pearsons korrelation og \(SSY\) er
\
for dataene i tabel \(\Sideindeks{1}\), \(pris_y = 2,06\), \(SSY = 4.597\) og \(Larv= 0.6268\). Derfor
\
som er den samme værdi beregnet tidligere.
lignende formler anvendes, når estimatets standardfejl beregnes ud fra en prøve snarere end en population. Den eneste forskel er, at nævneren er \(N-2\) snarere end \(N\). Årsagen \(N-2\) bruges snarere end \(N-1\) er, at to parametre (hældningen og skæringspunktet) blev estimeret for at estimere summen af firkanter. Formler for en prøve, der kan sammenlignes med dem for en population, er vist nedenfor.
\
\
\