Examples
Voorbeeld 1. Een klinisch diëtist wil twee verschillende diëten, A en B, vergelijken voor diabetespatiënten. Ze veronderstelt dat dieet a (Groep 1) beter zal zijn dan dieet B (groep 2), in termen van lagere bloedglucose. Ze is van plan om een willekeurige steekproef van diabetespatiënten en willekeurig toewijzen aan een van de twee diëten. Aan het einde van het experiment, dat 6 weken duurt, zal bij elke patiënt een nuchtere bloedglucosetest worden uitgevoerd. Ze verwacht ook dat het gemiddelde verschil in bloedglucosemeting tussen de twee groepen ongeveer 10 mg/dl zal zijn. Bovendien gaat zij er ook van uit dat de standaarddeviatie van de bloedglucose verdeling voor dieet a 15 is en de standaarddeviatie voor dieet B 17. De diëtist wil weten hoeveel personen er in elke groep nodig zijn, uitgaande van groepen van gelijke grootte.
Voorbeeld 2. Een audioloog wilde het effect van geslacht op de reactietijd op een bepaalde geluidsfrequentie bestuderen. Hij vermoedde dat mannen beter waren in het detecteren van dit soort geluid dan vrouwen waren. Hij nam een steekproef van 20 mannelijke en 20 vrouwelijke proefpersonen voor dit experiment. Elk onderwerp kreeg een knop om op te drukken wanneer hij/zij het geluid hoorde. De audioloog meet toen de responstijd – de tijd tussen het geluid werd uitgezonden en de tijd dat de knop werd ingedrukt. Nu wil hij weten wat de statistische kracht is gebaseerd op zijn totaal van 40 proefpersonen om het geslachtsverschil te detecteren.
Prelude op de Vermogensanalyse
Er zijn twee verschillende aspecten van de vermogensanalyse. Een daarvan is het berekenen van de benodigde steekproefgrootte voor een bepaalde macht zoals in Voorbeeld 1. Het andere aspect is om de macht te berekenen wanneer gegeven een specifieke steekproefgrootte zoals in Voorbeeld 2. Technisch gezien is macht de kans om de nulhypothese af te wijzen wanneer de specifieke alternatieve hypothese waar is.
voor de vermogensanalyses hieronder zullen we ons concentreren op Voorbeeld 1, Het berekenen van de steekproefgrootte voor een gegeven statistisch vermogen van het testen van het verschil in het effect van dieet A en dieet B. Let op de veronderstellingen die de diëtist heeft gemaakt om de vermogensanalyse uit te voeren. Hier is de informatie die we moeten weten of moeten aannemen om de energieanalyse uit te voeren:
- het verwachte verschil in de gemiddelde bloedglucose; in dit geval wordt het vastgesteld op 10.
- de standaardafwijkingen van bloedglucose voor groep 1 en groep 2; in dit geval worden ze vastgesteld op respectievelijk 15 en 17.
- het alfaniveau, of het type I-foutenpercentage, dat de kans is om de nulhypothese af te wijzen wanneer deze daadwerkelijk waar is. Een algemene praktijk is om het op de .Niveau 05.
- het vooraf gespecificeerde statistische vermogen voor het berekenen van de steekproefgrootte; dit wordt ingesteld op .8.
- het vooraf gespecificeerde aantal proefpersonen voor de berekening van de statistische macht; Dit is bijvoorbeeld de situatie 2.
merk op dat in het eerste voorbeeld de diëtist niet het gemiddelde voor elke groep specificeerde, maar alleen het verschil tussen de twee gemiddelden. Dit komt omdat ze alleen geïnteresseerd is in het verschil, en het maakt niet uit wat de middelen zijn, zolang het verschil hetzelfde is.
Vermogensanalyse
In R is het vrij eenvoudig om vermogensanalyse uit te voeren voor het vergelijken van gemiddelden. We kunnen bijvoorbeeld het PWR-pakket in R gebruiken voor onze berekening zoals hieronder weergegeven. We specificeren eerst de twee middelen, het gemiddelde voor groep 1 (dieet A) en het gemiddelde voor groep 2 (dieet B). Aangezien het verschil belangrijk is, kunnen we in plaats van de middelen voor elke groep een gemiddelde van nul invoeren voor groep 1 en 10 voor het gemiddelde van groep 2, zodat het verschil in middelen 10 is. Vervolgens moeten we de gepoolde standaardafwijking specificeren, wat de vierkantswortel is van het gemiddelde van de twee standaardafwijkingen. In dit geval is het sqrt((15^2 + 17^2)/2) = 16.03. Het standaard significantieniveau (alfaniveau) is .05. Voor dit voorbeeld zullen we de macht om te zijn op .8.
de berekeningsresultaten geven aan dat we 42 proefpersonen voor dieet A en nog eens 42 proefpersonen voor dieet B in ons monster nodig hebben om het effect te sorteren. Laten we nu een ander paar middelen gebruiken met hetzelfde verschil. Zoals we eerder hebben besproken, zouden de resultaten hetzelfde moeten zijn, en dat zijn ze ook.
nu kan de diëtist het gevoel hebben dat een totale steekproefgrootte van 84 personen haar budget te boven gaat. Een manier om de steekproefgrootte te verminderen is het type I-foutenpercentage of het alfaniveau te verhogen. Laten we zeggen in plaats van het gebruik van alfa-niveau van .05 zullen we gebruiken .07. Dan zal onze steekproefgrootte verminderen met 4 voor elke groep zoals hieronder getoond.
stel nu dat de diëtist alleen gegevens kan verzamelen over 60 proefpersonen met 30 in elke groep. Wat zal de statistische kracht voor haar t-test zijn met betrekking tot alfaniveau van .05?
zoals we eerder hebben besproken, is het verschil tussen de gemiddelden ten opzichte van de gepoolde standaardafwijking het belangrijkste bij de berekening van het vermogen of de steekproefgrootte. Dit is een maat voor de effectgrootte. Laten we nu kijken naar hoe de effectgrootte de steekproefgrootte beïnvloedt uitgaande van een gegeven steekproefvermogen. We kunnen gewoon aannemen dat het verschil in middelen en stel de standaarddeviatie op 1 en maak een tabel met effect grootte, d, variërend van .2 tot 1,2.
we kunnen deze informatie ook gemakkelijk weergeven in een plot.
plot(ptab,ptab,type="b",xlab="effect size",ylab="sample size")
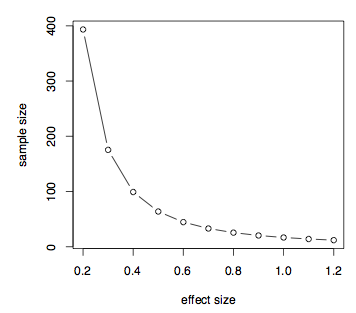
Het geeft aan dat als de effectgrootte klein is, dit zo is .2 dan hebben we een zeer grote steekproefgrootte nodig en die steekproefgrootte daalt naarmate de effectgrootte toeneemt. We kunnen ook easilyplot macht versus steekproefgrootte voor een bepaalde effectgrootte, laten we zeggen, d = 0.7
pwrt
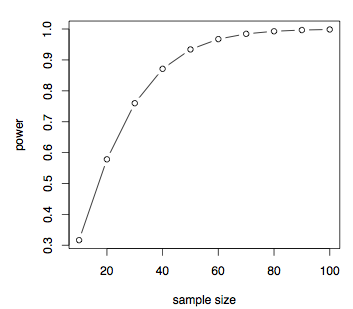
discussie
een belangrijke technische aanname is de normaliteitsaanname. Als de verdeling scheef is, kan een kleine steekproefgrootte niet de macht hebben die in de resultaten wordt getoond, omdat de waarde in de resultaten wordt berekend met behulp van de methode op basis van de normaliteitsaanname. We hebben gezien dat om de macht of de steekproefgrootte te berekenen, we een aantal veronderstellingen moeten maken. Deze veronderstellingen worden niet alleen gebruikt voor de berekening, maar worden ook gebruikt in de eigenlijke t-test zelf. Een belangrijk bijkomend voordeel van het uitvoeren van energieanalyse is om ons te helpen onze ontwerpen en hypothesen beter te begrijpen.
bij de berekening van het vermogen hebben we gezien dat het verschil in gemiddelden en standaardafwijkingen voor de twee groepen van belang is bij de T-test van de twee onafhankelijke monsters. Dit leidt tot het concept van effectgrootte. In dit geval is de effectgrootte het verschil in gemiddelden ten opzichte van de gepoolde standaardafwijking. Hoe groter de effectgrootte, hoe groter de kracht voor een bepaalde steekproefgrootte. Of, hoe groter de effectgrootte, hoe kleiner de steekproefgrootte nodig is om hetzelfde vermogen te bereiken. Een goede schatting van de effectgrootte is dus de sleutel tot een goede vermogensanalyse. Maar het is niet altijd een gemakkelijke taak om de grootte van het effect te bepalen. Goede schattingen van de omvang van het effect komen uit de bestaande literatuur of uit pilotstudies.