exempel
exempel 1. En klinisk dietist vill jämföra två olika dieter, A och B, för diabetespatienter. Hon antar att diet A (Grupp 1) kommer att vara bättre än diet B (Grupp 2), när det gäller lägre blodsocker. Hon planerar att få ett slumpmässigt urval av diabetespatienter och slumpmässigt tilldela dem till en av de två dieterna. I slutet av experimentet, som varar 6 veckor, kommer ett fastande blodsockertest att utföras på varje patient. Hon förväntar sig också att den genomsnittliga skillnaden i blodsockermått mellan de två grupperna kommer att vara cirka 10 mg/dl. Dessutom antar hon också standardavvikelsen för blodglukosfördelning för diet A att vara 15 och standardavvikelsen för diet B att vara 17. Dietisten vill veta antalet ämnen som behövs i varje grupp som antar lika stora grupper.
exempel 2. En audiolog ville studera effekten av kön på svarstiden till en viss ljudfrekvens. Han misstänkte att män var bättre på att upptäcka denna typ av ljud då var kvinnor. Han tog ett slumpmässigt urval av 20 manliga och 20 kvinnliga ämnen för detta experiment. Varje ämne fick en knapp att trycka på när han / hon hörde ljudet. Audiologen mätte sedan svarstiden-tiden mellan ljudet emitterades och tiden som knappen trycktes på. Nu vill han veta vad den statistiska kraften bygger på hans totalt 40 ämnen för att upptäcka könsskillnaden.
Prelude till effektanalysen
det finns två olika aspekter av effektanalys. En är att beräkna det nödvändigasteprovstorlek för en viss effekt som i Exempel 1. Den andra aspekten är att beräkna effekten närges en specifik provstorlek som i Exempel 2. Tekniskt sett är makt sannolikheten för att avvisa nollhypotesen när den specifika alternativa hypotesen är sant.
för effektanalyserna nedan kommer vi att fokusera på Exempel 1, Beräkna provstorleken för en given statistisk kraft för att testa skillnaden i effekten av diet A och diet B. Lägg märke till de antaganden som dietisten har gjort för att utföra effektanalysen. Här är den information vi måste veta eller måste anta för att utföra kraftanalysen:
- den förväntade skillnaden i den genomsnittliga blodglukosen; i detta fall är den inställd på 10.
- standardavvikelserna för blodglukos för Grupp 1 och Grupp 2; i detta fall är de inställda på 15 respektive 17.
- alfa-nivån, eller typ i-felfrekvensen, vilket är sannolikheten för att avvisa nollhypotesen när det faktiskt är sant. En vanlig praxis är att ställa in den på .05 nivå.
- den förutbestämda nivån för statistisk effekt för beräkning av provstorleken; detta kommer att ställas in på .8.
- det förutbestämda antalet ämnen för beräkning av statistisk effekt; Detta är situationen till exempel 2.
Observera att dietisten i det första exemplet inte specificerade medelvärdet för varje grupp, istället specificerade hon bara skillnaden mellan de två medlen. Detta beror på att hon bara är intresserad av skillnaden, och det spelar ingen roll vad medlen är så länge skillnaden är densamma.
effektanalys
i R är det ganska enkelt att utföra effektanalys för att jämföra medel. Till exempel kan vi använda PWR-paketet i R för vår beräkning som visas nedan. Vi anger först de två medlen, medelvärdet för Grupp 1 (diet A) och medelvärdet för Grupp 2 (diet B). Eftersom det som verkligen betyder något är skillnaden, istället för medel för varje grupp, kan vi ange ett medelvärde på noll för Grupp 1 och 10 för medelvärdet av Grupp 2, så att skillnaden i medel blir 10. Därefter måste vi ange den poolade standardavvikelsen, som är kvadratroten av genomsnittet av de två standardavvikelserna. I det här fallet är det sqrt((15^2 + 17^2)/2) = 16.03. Standardnivån för signifikansnivå (alfa-nivå) är .05. För detta exempel kommer vi att ställa in kraften att vara på .8.
beräkningsresultaten indikerar att vi behöver 42 ämnen för diet A och ett annat 42 ämne för diet B i vårt prov för effekten. Låt oss nu använda ett annat par medel med samma skillnad. Som vi har diskuterat tidigare bör resultaten vara desamma, och de är.nu kan dietisten känna att en total provstorlek på 84 ämnen ligger utanför hennes budget. Ett sätt att minska provstorleken är att öka typ i-felfrekvensen eller alfa-nivån. Låt oss säga istället för att använda alfa nivå av .05 vi kommer att använda .07. Då kommer vår provstorlek att minska med 4 för varje grupp som visas nedan.anta nu att dietisten bara kan samla in data om 60 personer med 30 i varje grupp. Vad kommer den statistiska kraften för hennes t-test att vara med avseende på alfa-nivå av .05?
som vi har diskuterat tidigare är det som verkligen betyder något vid beräkningen av effekt eller provstorlek skillnaden mellan medlen över den poolade standardavvikelsen. Detta är ett mått på effektstorlek. Låt oss nu titta på hur effektstorleken påverkar provstorleken förutsatt att en given provkraft. Vi kan helt enkelt anta skillnaden i medel och ställa in standardavvikelsen för att vara 1 och skapaett bord med effektstorlek, d, varierande från .2 till 1.2.
Vi kan också enkelt visa denna information i en plot.
plot(ptab,ptab,type="b",xlab="effect size",ylab="sample size")
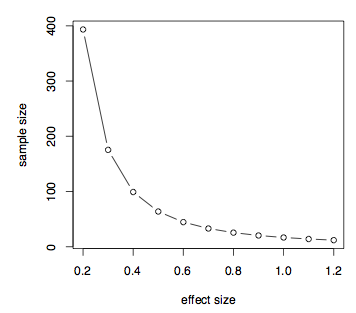
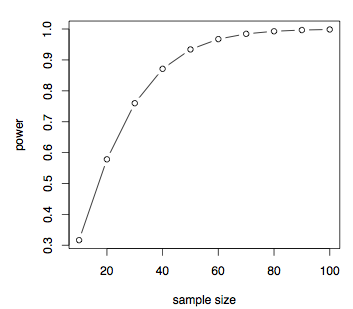
det visar att om effektstorleken är liten, sådan .2 då behöver vi en mycket stor provstorlek och den provstorleken sjunker när effektstorleken ökar. Vi kan också easilyplot power kontra provstorlek för en given effektstorlek, säg d = 0.7
pwrt
diskussion
ett viktigt tekniskt antagande är normalitetsantagandet. Om fördelningen är skev, kanske en liten provstorlek inte har den effekt som visas i resultaten, eftersom värdet i resultaten beräknas med hjälp av metoden baserat på normalitetsantagandet. Vi har sett att för att beräkna kraften eller provstorleken måste vi göra ett antal antaganden. Dessa antaganden används inte bara för beräkningsändamål utan används också i själva T-testet. Så en viktig sidofördel med att utföra kraftanalys är att hjälpa oss att bättre förstå våra mönster och våra hypoteser.
Vi har sett i kraftberäkningsprocessen att det som är viktigt i det tvåoberoende provet t-testet är skillnaden i medel och standardavvikelser för de två grupperna. Detta leder till begreppet effektstorlek. I detta fall kommer effektstorleken att vara skillnaden i medel över den poolade standardavvikelsen. Ju större effektstorlek, desto större effekt för en given provstorlek. Eller ju större effektstorlek, desto mindre provstorlek behövs för att uppnå samma effekt. Så en bra uppskattning av effektstorlek är nyckeln till en bra effektanalys. Men det är inte alltid en lätt uppgift att bestämma effektstorleken. Goda uppskattningar av effektstorlek kommer från befintlig litteratur eller från pilotstudier.