Esempi
Esempio 1. Un dietista clinico vuole confrontare due diverse diete, A e B, per i pazienti diabetici. Lei ipotizza che la dieta A (Gruppo 1) sarà migliore della dieta B (Gruppo 2), in termini di glucosio nel sangue più basso. Ha in programma di ottenere un campione casuale di pazienti diabetici e assegnarli casualmente a una delle due diete. Alla fine dell’esperimento, che dura 6 settimane, verrà condotto un test della glicemia a digiuno su ciascun paziente. Si aspetta anche che la differenza media nella misura della glicemia tra i due gruppi sarà di circa 10 mg/dl. Inoltre, assume anche la deviazione standard della distribuzione del glucosio nel sangue per la dieta A essere 15 e la deviazione standard per la dieta B essere 17. Il dietologo vuole conoscere il numero di soggetti necessari in ogni gruppo assumendo gruppi di dimensioni uguali.
Esempio 2. Un audiologo voleva studiare l’effetto del genere sul tempo di risposta a una certa frequenza sonora. Sospettava che gli uomini fossero più bravi a rilevare questo tipo di suono, quindi erano donne. Ha preso un campione casuale di 20 soggetti maschi e 20 femmine per questo esperimento. Ogni soggetto è stato dato un pulsante da premere quando lui / lei ha sentito il suono. L’audiologo ha quindi misurato il tempo di risposta: il tempo tra il suono emesso e il tempo in cui è stato premuto il pulsante. Ora, vuole sapere che cosa il potere statistico si basa sul suo totale di 40 soggetti per rilevare la differenza di genere.
Preludio all’analisi della potenza
Ci sono due diversi aspetti dell’analisi della potenza. Uno è calcolare la dimensione necessarysample per una potenza specificata come nell’esempio 1. L’altro aspetto è quello di calcolare la potenza quandodata una specifica dimensione del campione come nell’esempio 2. Tecnicamente, il potere è la probabilità di rifiutare l’ipotesi nulla quando l’ipotesi alternativa specifica è vera.
Per le analisi di potenza di seguito, ci concentreremo sull’esempio 1, calcolando la dimensione del campione per una data potenza statistica di testare la differenza nell’effetto della dieta A e della dieta B. Notare le ipotesi che il dietologo ha fatto per eseguire l’analisi di potenza. Ecco le informazioni che dobbiamo conoscere o dobbiamo assumere per eseguire l’analisi di potenza:
- La differenza attesa nella glicemia media; in questo caso è impostata su 10.
- Le deviazioni standard della glicemia per il gruppo 1 e il gruppo 2; in questo caso, sono impostati rispettivamente su 15 e 17.
- Il livello alfa, o il tasso di errore di tipo I, che è la probabilità di rifiutare l’ipotesi nulla quando è effettivamente vera. Una pratica comune è quello di impostare al .05 livello.
- Il livello pre-specificato di potenza statistica per il calcolo della dimensione del campione; questo sarà impostato su .8.
- Il numero pre-specificato di soggetti per il calcolo della potenza statistica; questa è la situazione per esempio 2.
Si noti che nel primo esempio, il dietologo non ha specificato la media per ciascun gruppo, ma ha specificato solo la differenza dei due mezzi. Questo perché lei è interessata solo alla differenza, e non importa quali siano i mezzi finché la differenza è la stessa.
Analisi della potenza
In R, è abbastanza semplice eseguire l’analisi della potenza per confrontare i mezzi. Ad esempio, possiamo utilizzare il pacchetto pwr in R per il nostro calcolo come mostrato di seguito. Per prima cosa specifichiamo i due mezzi, la media per il Gruppo 1 (dieta A) e la media per il Gruppo 2 (dieta B). Poiché ciò che conta davvero è la differenza, invece di mezzi per ogni gruppo, possiamo inserire una media di zero per il Gruppo 1 e 10 per la media del Gruppo 2, in modo che la differenza di mezzi sia 10. Successivamente, dobbiamo specificare la deviazione standard aggregata, che è la radice quadrata della media delle due deviazioni standard. In questo caso, è sqrt((15^2 + 17^2)/2) = 16.03. Il livello di significatività predefinito (livello alfa) è .05. Per questo esempio imposteremo il potere di essere a .8.
I risultati del calcolo indicano che abbiamo bisogno di 42 soggetti per la dieta A e un altro soggetto 42 per la dieta B nel nostro campione per l’effetto. Ora, usiamo un altro paio di mezzi con la stessa differenza. Come abbiamo discusso in precedenza, i risultati dovrebbero essere gli stessi, e lo sono.
Ora il dietista può sentire che una dimensione totale del campione di 84 soggetti è oltre il suo budget. Un modo per ridurre la dimensione del campione è aumentare il tasso di errore di tipo I o il livello alfa. Diciamo invece di usare il livello alfa di .05 useremo .07. Quindi la nostra dimensione del campione si ridurrà di 4 per ogni gruppo come mostrato di seguito.
Ora supponiamo che il dietologo possa raccogliere solo dati su 60 soggetti con 30 in ciascun gruppo. Quale sarà la potenza statistica per il suo t-test essere rispetto al livello alfa di .05?
Come abbiamo discusso prima, ciò che conta davvero nel calcolo della potenza o della dimensione del campione è la differenza dei mezzi rispetto alla deviazione standard aggregata. Questa è una misura della dimensione dell’effetto. Diamo ora un’occhiata a come la dimensione dell’effetto influisce sulla dimensione del campione assumendo una determinata potenza del campione. Possiamo semplicemente assumere la differenza di mezzi e impostare la deviazione standard su 1 e creare una tabella con dimensione dell’effetto, d, che varia da .da 2 a 1.2.
Possiamo anche facilmente visualizzare queste informazioni in un grafico.
plot(ptab,ptab,type="b",xlab="effect size",ylab="sample size")
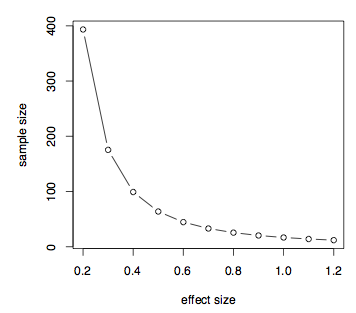
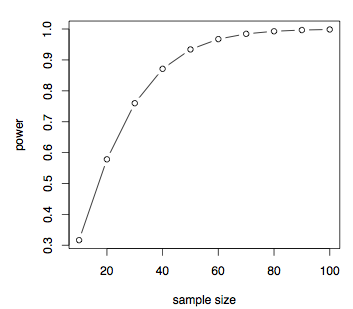
Mostra che se la dimensione dell’effetto è piccola, tale .2 quindi abbiamo bisogno di una dimensione del campione molto grande e quella dimensione del campione diminuisce all’aumentare della dimensione dell’effetto. Possiamo anche easilyplot potenza contro dimensione del campione per una data dimensione effetti, diciamo, d = 0.7
pwrt
Discussione
Un’importante ipotesi tecnica è quella della normalità. Se la distribuzione è distorta, una piccola dimensione del campione potrebbe non avere la potenza mostrata nei risultati, poiché il valore nei risultati viene calcolato utilizzando il metodo basato sull’ipotesi di normalità. Abbiamo visto che per calcolare la potenza o la dimensione del campione, dobbiamo fare una serie di ipotesi. Queste ipotesi sono utilizzate non solo ai fini del calcolo, ma sono anche utilizzate nel test t effettivo stesso. Quindi un importante vantaggio collaterale dell’analisi della potenza è quello di aiutarci a comprendere meglio i nostri progetti e le nostre ipotesi.
Abbiamo visto nel processo di calcolo della potenza che ciò che conta nel campione t-test a due indipendenti è la differenza nei mezzi e le deviazioni standard per i due gruppi. Questo porta al concetto di dimensione dell’effetto. In questo caso, la dimensione dell’effetto sarà la differenza di mezzi rispetto alla deviazione standard aggregata. Maggiore è la dimensione dell’effetto, maggiore è la potenza per una determinata dimensione del campione. Oppure, maggiore è la dimensione dell’effetto, minore è la dimensione del campione necessaria per ottenere la stessa potenza. Quindi, una buona stima della dimensione dell’effetto è la chiave per una buona analisi della potenza. Ma non è sempre un compito facile determinare la dimensione dell’effetto. Buone stime della dimensione dell’effetto provengono dalla letteratura esistente o da studi pilota.