실시예
실시예 1 에 대한 전력 분석. 임상 영양사는 당뇨병 환자를 위해 두 가지식이 요법 인 A 와 B 를 비교하려고합니다. 그녀는 더 낮은 혈당 측면에서 다이어트 A(그룹 1)가 다이어트 B(그룹 2)보다 더 좋을 것이라고 가설을 세웠다. 그녀는 당뇨병 환자의 무작위 샘플을 얻고 두 가지 다이어트 중 하나에 무작위로 배정 할 계획입니다. 6 주간 지속되는 실험이 끝나면 각 환자에게 공복 혈당 검사가 실시됩니다. 그녀는 또한 두 그룹 간의 혈당 측정의 평균 차이가 약 10mg/dl 이 될 것으로 기대합니다. 또한,그녀는 또한식이 요법 A 에 대한 혈당 분포의 표준 편차를 15 로,다이어트 B 에 대한 표준 편차를 17 로 가정합니다. 영양사는 동일한 크기의 그룹을 가정하는 각 그룹에서 필요한 과목 수를 알고 싶어합니다.
실시예 2. 청력 학자는 특정 사운드 주파수에 대한 응답 시간에 대한 성별의 영향을 연구하기를 원했습니다. 그는 그 때 남자들이이 유형의 소리를 감지하는 것이 더 낫다고 의심했다. 그는이 실험을 위해 20 명의 남성과 20 명의 여성 피험자의 무작위 샘플을 채취했습니다. 각 주제는 그/그녀가 소리를 들었을 때 누를 수있는 버튼이 주어졌다. 그런 다음 청력 학자는 소리가 방출 된 시간과 버튼을 누른 시간 사이의 응답 시간을 측정했습니다. 이제 그는 성별 차이를 감지하기 위해 총 40 명의 피험자를 기반으로 통계력이 무엇인지 알고 싶어합니다.
전력 분석의 전주곡
전력 분석의 두 가지 측면이 있습니다. 하나는 필요한 것을 계산하는 것입니다예시 1 에서와 같이 지정된 전력에 대한 샘플 크기. 다른 측면은 예제 2 에서와 같이 특정 샘플 크기를 계산하여 전력을 계산하는 것입니다. 기술적으로 권력은 특정 대체 가설이 사실 일 때 귀무 가설을 거부 할 확률입니다.
전력 분석을 아래,우리는 것에 집중하기를 들어 1,을 계산하는 샘플 크기 위해 주어진 통계 능력을 테스트하는 효과에 차이의 다이어트와 다이어트 B. 통하는 가정의 영양가를 수행하기 위해 전력 분석합니다. 다음은 전력 분석을 수행하기 위해 우리가 알아야 할 정보 또는 가정해야 할 정보입니다:
- 평균 혈당의 예상 차이;이 경우 10 으로 설정됩니다.
- 그룹 1 과 그룹 2 에 대한 혈당의 표준 편차;이 경우 각각 15 와 17 로 설정됩니다.
- 알파 수준 또는 유형 I 오류율,이는 실제로 사실 일 때 귀무 가설을 거부 할 확률입니다. 일반적인 관행은에 설정하는 것입니다.05 레벨.
- 표본 크기를 계산하기위한 통계 전력의 미리 지정된 수준;이것은로 설정됩니다.8.
- 통계력을 계산하기 위해 미리 지정된 수의 과목;이것은 예를 들어 2 의 상황입니다.
첫 번째 예에서 영양사는 각 그룹에 대한 평균을 지정하지 않고 대신 두 수단의 차이 만 지정했음을 알 수 있습니다. 왜냐하면 그녀는 그 차이에만 관심이 있기 때문입니다.
전력 분석
R,그것은 매우 간단을 수행하는 전력 분석에 대한 비교하는 것을 의미한다. 예를 들어,아래 그림과 같이 계산을 위해 R 의 pwr 패키지를 사용할 수 있습니다. 우리는 먼저 그룹 1(다이어트 A)에 대한 평균과 그룹 2(다이어트 B)에 대한 평균의 두 가지 수단을 지정합니다. 때문에 정말로 중요한 차이는 대신 즉 각 그룹에 대해,우리가 입력할 수 있습의 의미로 그룹 1 과 10 에 대한 의미의 그룹이 2 개,그래서 그 의미의 차이 될 것입니다 10. 다음으로 풀링 된 표준 편차를 지정해야합니다.이 표준 편차는 두 표준 편차의 평균의 제곱근입니다. 이 경우 sqrt 입니다((15^2 + 17^2)/2) = 16.03. 기본 중요도 수준(알파 수준)입니다.05. 이 예를 들어 우리는에있을 수있는 힘을 설정합니다.8.
계산 결과를 나타내는 우리에게 필요 42 과목에 대한 다이어트와 다른 42 주제에 대한 다이어트 B 에서 우리의 견본기 위해서는 효과가 있습니다. 자,같은 차이를 가진 또 다른 한 쌍의 수단을 사용합시다. 앞서 논의했듯이 결과는 동일해야하며,그렇습니다.
이제 영양사는 84 명의 피험자의 총 표본 크기가 그녀의 예산을 초과한다고 느낄 수 있습니다. 샘플 크기를 줄이는 한 가지 방법은 유형 I 오류율 또는 알파 수준을 높이는 것입니다. 의 알파 수준을 사용하는 대신 가정 해 봅시다.05 사용하겠습니다.07. 그런 다음 샘플 크기는 아래 그림과 같이 각 그룹에 대해 4 만큼 줄어 듭니다.
이제 영양사는 각 그룹에 30 명이있는 60 명의 피험자에 대한 데이터 만 수집 할 수 있다고 가정합니다. 그녀의 t-테스트에 대한 통계적 힘은 알파 레벨과 관련하여 무엇이 될 것인가.05?
으로 우리가 논의하기 전에 정말 무엇이 문제의 계산에 힘 또는 샘플 크기의 차이는 수단을 통해 풀 표준 편차가 있다고 가정합니다. 이것은 효과 크기의 척도입니다. 이제 효과 크기가 주어진 샘플 전력을 가정하는 샘플 크기에 미치는 영향을 살펴 보겠습니다. 우리는 단순히 수단의 차이를 가정하고 표준 편차를 1 로 설정하고 효과 크기,d,다양한 createa 테이블을 설정할 수 있습니다.2 에 1.2. 이 정보를 플롯에 쉽게 표시 할 수도 있습니다.
plot(ptab,ptab,type="b",xlab="effect size",ylab="sample size")
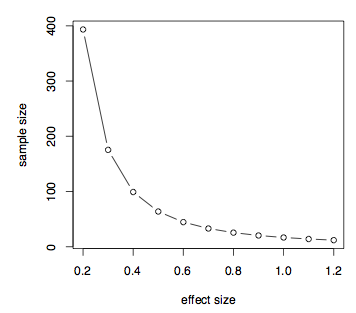
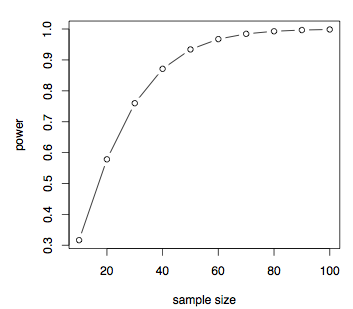
보이는 경우 효과는 크기가 작습니다.2 그런 다음 매우 큰 샘플 크기가 필요하며 효과 크기가 증가함에 따라 샘플 크기가 떨어집니다. 우리는 또한 주어진 효과 크기(예:d=0)에 대한 샘플 크기 대 전력 플롯을 쉽게 할 수 있습니다.7
pwrt
토론
중요한 기술적인 가정이 정상에 가정이다. 을 경우 배가 기울어져 있는,그 작은 샘플 크기 없을 수 있습니다 전에 표시된 결과이기 때문에,값에 결과를 사용하여 계산 방법에 따라 정상의 가정. 우리는 전력이나 표본 크기를 계산하기 위해 여러 가지 가정을해야한다는 것을 보았습니다. 이러한 가정은 계산의 목적뿐만 아니라 실제 t-테스트 자체에서도 사용됩니다. 그래서 하나의 중요한 측면 혜택을 수행하는 전력 분석을 우리에게 도움을 더 잘 이해할 우리의 디자인 및 우리의 가설을 정합니다.
우리는 우리가 볼 수 있에 힘을 계산하는 과정에서 무엇이 중요 두-독립적인 샘플 t-테스트에서 모든 수단 및 표준 편차에 대해 두 개의 그룹이 있습니다. 이것은 효과 크기의 개념으로 이어집니다. 이 경우 효과 크기는 풀링 된 표준 편차에 대한 수단의 차이가됩니다. 효과 크기가 클수록 주어진 샘플 크기에 대한 힘이 커집니다. 또는 효과 크기가 클수록 동일한 전력을 달성하는 데 필요한 샘플 크기가 작아집니다. 따라서 효과 크기의 좋은 추정치가 좋은 전력 분석의 핵심입니다. 그러나 효과 크기를 결정하는 것이 항상 쉬운 작업은 아닙니다. 효과 크기의 좋은 추정치는 기존 문헌 또는 파일럿 연구에서 나온 것입니다.