Examples
Example 1. Klinický dietolog chce porovnat dvě různé diety, A A B, u diabetických pacientů. Předpokládá, že dieta a (skupina 1) bude lepší než dieta B (Skupina 2), pokud jde o nižší hladinu glukózy v krvi. Plánuje získat náhodný vzorek diabetických pacientů a náhodně je přiřadit k jedné ze dvou diet. Na konci experimentu, který trvá 6 týdnů, bude u každého pacienta proveden test glukózy v krvi nalačno. Očekává také, že průměrný rozdíl v měření hladiny glukózy v krvi mezi oběma skupinami bude asi 10 mg / dl. Dále také předpokládá, že standardní odchylka distribuce glukózy v krvi pro dietu a je 15 a směrodatná odchylka pro dietu B je 17. Dietolog chce znát počet subjektů potřebných v každé skupině za předpokladu stejných skupin.
příklad 2. Audiolog chtěl studovat vliv pohlaví na dobu odezvy na určitou zvukovou frekvenci. Měl podezření, že muži lépe detekují tento typ zvuku, než ženy. Pro tento experiment vzal náhodný vzorek 20 mužských a 20 ženských subjektů. Každý subjekt dostal tlačítko stisknout, když on / ona slyšela zvuk. Audiolog pak změřil dobu odezvy – čas mezi vydaným zvukem a časem stisknutí tlačítka. Nyní chce vědět, jaká je statistická síla založená na jeho celkem 40 subjektech, aby zjistil rozdíl mezi pohlavími.
předehra k analýze výkonu
existují dva různé aspekty analýzy výkonu. Jedním z nich je výpočet potřebnýchvzorková velikost pro zadaný výkon jako v příkladu 1. Druhým aspektem je výpočet výkonu, kdyždát určitou velikost vzorku jako v příkladu 2. Technicky je síla pravděpodobnost odmítnutí nulové hypotézy, když je konkrétní alternativní hypotéza pravdivá.
Pro napájení analýzy níže, budeme se soustředit na Příklad 1, výpočet velikosti vzorku pro danou statistickou sílu testování rozdíl v účinku stravy a stravy B. Oznámení předpoklady, že dietologem učinil za účelem provedení power analýza. Zde jsou informace, které musíme znát nebo musíme předpokládat, abychom mohli provést analýzu výkonu:
- očekávaný rozdíl v průměrné hladině glukózy v krvi; v tomto případě je nastaven na 10.
- standardní odchylky glukózy v krvi pro skupinu 1 a skupinu 2; v tomto případě jsou nastaveny na 15 a 17.
- úroveň alfa nebo chybovost typu I, což je pravděpodobnost odmítnutí nulové hypotézy, když je skutečně pravdivá. Běžnou praxí je nastavit ji na .Úroveň 05.
- předem zadaná úroveň statistického výkonu pro výpočet velikosti vzorku; toto bude nastaveno na .8.
- předem stanovený počet subjektů pro výpočet statistické síly; to je situace například 2.
Všimněte si, že v prvním příkladu dietolog nespecifikoval průměr pro každou skupinu, místo toho specifikoval pouze rozdíl těchto dvou prostředků. Je to proto, že se zajímá pouze o rozdíl a nezáleží na tom, jaké prostředky jsou, pokud je rozdíl stejný.
Power Analysis
V R je poměrně jednoduché provádět power analysis pro porovnání prostředků. Pro náš výpočet můžeme například použít balíček pwr v R, jak je uvedeno níže. Nejprve specifikujeme dva prostředky, průměr pro skupinu 1 (Dieta A)a průměr pro skupinu 2 (Dieta B). Protože na čem opravdu záleží, je rozdíl, místo prostředků pro každou skupinu můžeme zadat průměr nuly pro skupinu 1 a 10 pro průměr skupiny 2, takže rozdíl v prostředcích bude 10. Dále musíme specifikovat sdruženou směrodatnou odchylku, což je druhá odmocnina průměru dvou směrodatných odchylek. V tomto případě je to sqrt((15^2 + 17^2)/2) = 16.03. Výchozí úroveň významnosti (alfa úroveň) je .05. V tomto příkladu nastavíme sílu, která má být .8.
výsledky výpočtu ukazují, že v našem vzorku potřebujeme 42 subjektů pro dietu a a dalších 42 subjektů pro dietu B, aby byl účinek. Nyní použijeme další pár prostředků se stejným rozdílem. Jak jsme již dříve diskutovali, výsledky by měly být stejné a jsou.
nyní může mít dietolog pocit, že celková velikost vzorku 84 subjektů je nad její rozpočet. Jedním ze způsobů, jak snížit velikost vzorku, je zvýšit chybovost typu I nebo úroveň alfa. Řekněme, že místo použití alfa úrovně .05 budeme používat .07. Pak se naše velikost vzorku sníží o 4 pro každou skupinu, jak je uvedeno níže.
nyní předpokládejme, že dietolog může shromažďovat pouze údaje o 60 subjektech s 30 v každé skupině. Jaká bude statistická síla pro její t-test s ohledem na úroveň alfa .05?
jak jsme již dříve diskutovali, ve výpočtu výkonu nebo velikosti vzorku je skutečně důležitý rozdíl prostředků oproti sdružené směrodatné odchylce. Toto je míra velikosti efektu. Podívejme se nyní na to, jak velikost efektu ovlivňuje velikost vzorku za předpokladu daného výkonu vzorku. Můžeme jednoduše předpokládat rozdíl v prostředcích a nastavit směrodatnou odchylku na 1 a vytvořit tabulku s velikostí efektu, d, od .2 až 1.2.
tyto informace můžeme také snadno zobrazit v grafu.
plot(ptab,ptab,type="b",xlab="effect size",ylab="sample size")
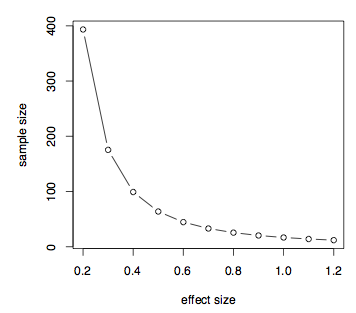
ukazuje se, že pokud efekt velikost je malá, tak .2 pak potřebujeme velmi velkou velikost vzorku a velikost vzorku klesá se zvyšující se velikostí efektu. Můžeme také snadno získat sílu versus velikost vzorku pro danou velikost efektů, řekněme, d = 0.7.
pwrt
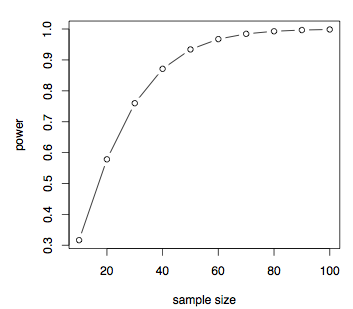
Diskuse
důležitým technickým předpokladem je předpoklad normality. Pokud je distribuce zkosená, pak malá velikost vzorku nemusí mít výkon uvedený ve výsledcích, protože hodnota ve výsledcích se vypočítá metodou založenou na předpokladu normality. Viděli jsme, že pro výpočet výkonu nebo velikosti vzorku musíme provést řadu předpokladů. Tyto předpoklady se používají nejen pro účely výpočtu,ale používají se také v samotném t-testu. Jednou z důležitých vedlejších výhod provádění analýzy výkonu je tedy pomoci nám lépe porozumět našim návrhům a hypotézám.
viděli Jsme v power výpočet proces, který záleží ve dvou nezávislých vzorků t-testu je rozdíl v prostředcích a směrodatné odchylky pro obě skupiny. To vede k pojetí velikosti efektu. V tomto případě bude velikost efektu rozdíl v prostředcích oproti sdružené směrodatné odchylce. Čím větší je velikost efektu, tím větší je výkon pro danou velikost vzorku. Nebo čím větší je velikost efektu, tím menší je velikost vzorku potřebná k dosažení stejného výkonu. Dobrý odhad velikosti efektu je tedy klíčem k dobré analýze výkonu. Není však vždy snadné určit velikost efektu. Dobré odhady velikosti účinku pocházejí ze stávající literatury nebo z pilotních studií.