Edge computing is een gedistribueerde IT-architectuur, waarin clientgegevens worden verwerkt aan de rand van het netwerk, zo dicht mogelijk bij de bron die de gegevens afkomstig heeft.
Data is de levensader van het moderne bedrijfsleven, biedt waardevol zakelijk inzicht en ondersteunt real-time controle over kritieke bedrijfsprocessen en-operaties. Bedrijven van vandaag zijn overspoeld in een oceaan van gegevens, en enorme hoeveelheden gegevens kunnen routinematig worden verzameld van sensoren en IoT-apparaten die in realtime werken vanaf afgelegen locaties en onherbergzame operationele omgevingen bijna overal in de wereld.
maar deze virtuele stroom van gegevens verandert ook de manier waarop bedrijven omgaan met computing. Het traditionele computerparadigma dat is gebouwd op een gecentraliseerd datacenter en het dagelijkse internet is niet goed geschikt voor het verplaatsen van eindeloos groeiende rivieren van real-world data. Bandbreedtebeperkingen, latency-problemen en onvoorspelbare netwerkverstoringen kunnen allemaal samenzweren om dergelijke inspanningen te belemmeren. Bedrijven reageren op deze data-uitdagingen door het gebruik van edge computing-architectuur.
in eenvoudige termen verplaatst edge computing een deel van de opslag-en rekenbronnen uit het centrale datacenter en dichter bij de bron van de gegevens zelf. In plaats van ruwe gegevens door te sturen naar een centraal datacenter voor verwerking en analyse, wordt dat werk uitgevoerd waar de gegevens daadwerkelijk worden gegenereerd — of dat nu een winkel is, een fabrieksvloer, een uitgestrekt utility of in een slimme stad. Alleen het resultaat van dat computerwerk aan de rand, zoals real-time bedrijfsinzichten, voorspellingen voor onderhoud van apparatuur of andere bruikbare antwoorden, wordt teruggestuurd naar het belangrijkste datacenter voor beoordeling en andere menselijke interacties.
edge computing verandert dus IT en business computing. Neem een uitgebreide blik op wat edge computing is, hoe het werkt, de invloed van de cloud, edge use cases, afwegingen en implementatie overwegingen.
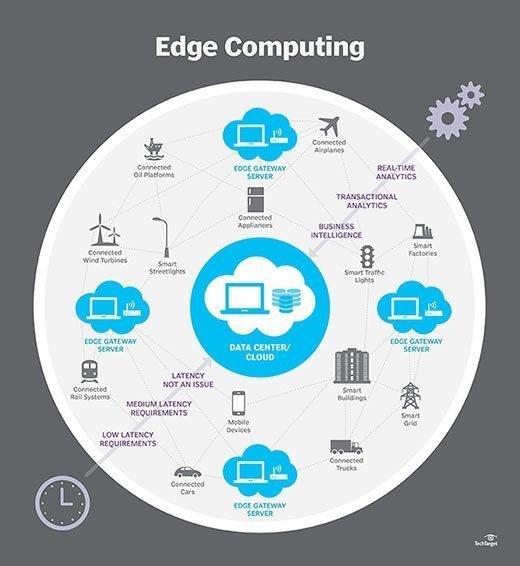
Hoe werkt edge computing?
Edge computing is een kwestie van locatie. In de traditionele enterprise computing worden gegevens geproduceerd op een clienteindpunt, zoals de computer van een gebruiker. Die gegevens worden verplaatst via een WAN zoals het internet, via het corporate LAN, waar de gegevens worden opgeslagen en bewerkt door een enterprise-applicatie. De resultaten van dat werk worden vervolgens teruggestuurd naar het eindpunt van de cliënt. Dit blijft een bewezen en beproefde benadering van client-server computing voor de meeste typische zakelijke toepassingen.
maar het aantal apparaten dat op het internet is aangesloten, en de hoeveelheid gegevens die door deze apparaten worden geproduceerd en door bedrijven worden gebruikt, groeit veel te snel voor traditionele datacenterinfrastructuren. Gartner voorspelde dat in 2025, 75% van de enterprise-gegenereerde data zal worden gemaakt buiten de gecentraliseerde datacenters. Het vooruitzicht om zoveel gegevens te verplaatsen in situaties die vaak tijd – of disruptiegevoelig kunnen zijn, zet een ongelooflijke druk op het wereldwijde internet, dat zelf vaak onderhevig is aan congestie en disruptie.
IT-architecten hebben de focus verlegd van het centrale datacenter naar de logische rand van de infrastructuur-ze nemen opslag-en computerbronnen van het datacenter en verplaatsen die bronnen naar het punt waar de gegevens worden gegenereerd. Het principe is eenvoudig: als je de gegevens niet dichter bij het datacenter kunt krijgen, krijg je het datacenter dichter bij de gegevens. Het concept van edge computing is niet nieuw, en het is geworteld in tientallen jaren oude ideeën van remote computing – zoals remote kantoren en filialen-waar het betrouwbaarder en efficiënter was om computerbronnen op de gewenste locatie te plaatsen in plaats van op één centrale locatie te vertrouwen.

Edge computing plaatst opslag en servers waar de gegevens zich bevinden, waarbij vaak weinig meer dan een gedeeltelijk tandwiel nodig is om op het externe LAN te werken om de gegevens lokaal te verzamelen en te verwerken. In veel gevallen wordt de computerapparatuur ingezet in afgeschermde of geharde behuizingen om de apparatuur te beschermen tegen extreme temperaturen, vocht en andere omgevingsomstandigheden. De verwerking impliceert vaak het normaliseren en analyseren van de gegevensstroom om bedrijfsintelligentie te zoeken, en slechts de resultaten van de analyse worden teruggestuurd naar het belangrijkste datacenter.
het idee van business intelligence kan sterk variëren. Enkele voorbeelden zijn retailomgevingen waar videobewaking van de showroomvloer kan worden gecombineerd met feitelijke verkoopgegevens om de meest wenselijke productconfiguratie of vraag van de consument te bepalen. Andere voorbeelden zijn predictive analytics die het onderhoud en de reparatie van apparatuur kunnen begeleiden voordat werkelijke defecten of storingen optreden. Nog andere voorbeelden worden vaak afgestemd op nutsbedrijven, zoals waterzuivering of elektriciteitsopwekking, om ervoor te zorgen dat de apparatuur naar behoren functioneert en de kwaliteit van de output te handhaven.
Edge vs. cloud vs. fog computing
Edge computing is nauw verbonden met de concepten cloud computing en fog computing. Hoewel er enige overlap tussen deze concepten, ze zijn niet hetzelfde, en over het algemeen niet door elkaar gebruikt moeten worden. Het is handig om de concepten te vergelijken en hun verschillen te begrijpen.
een van de makkelijkste manieren om de verschillen tussen edge, cloud en fog computing te begrijpen is om hun gemeenschappelijke thema te markeren: Alle drie concepten hebben betrekking op gedistribueerde computing en richten zich op de fysieke inzet van reken-en opslagbronnen in relatie tot de data die wordt geproduceerd. Het verschil is een kwestie van waar die middelen zich bevinden.
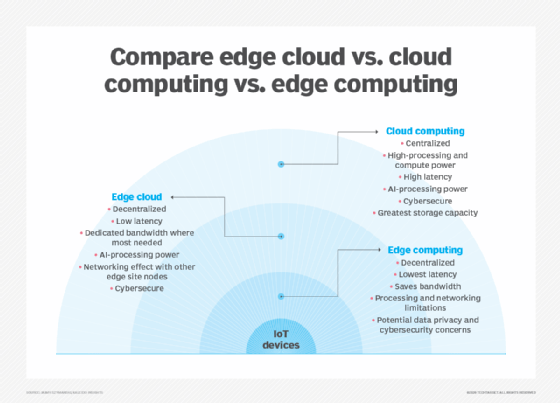
Edge. Edge computing is de inzet van computer-en opslagbronnen op de locatie waar gegevens worden geproduceerd. Dit zet de berekening en opslag idealiter op hetzelfde punt als de gegevensbron aan de netwerkrand. Bijvoorbeeld, een kleine behuizing met meerdere servers en enige opslag kan worden geïnstalleerd op de top van een windturbine voor het verzamelen en verwerken van gegevens geproduceerd door sensoren binnen de turbine zelf. Een ander voorbeeld is dat een station een bescheiden hoeveelheid reken-en opslagruimte in het station kan plaatsen om ontelbare track-en rail traffic sensorgegevens te verzamelen en te verwerken. De resultaten van een dergelijke verwerking kunnen vervolgens worden teruggestuurd naar een ander datacenter voor menselijke beoordeling, archivering en worden samengevoegd met andere gegevensresultaten voor bredere analyse.
Cloud. Cloud computing is een enorme, zeer schaalbare inzet van reken-en opslagbronnen op een van de verschillende gedistribueerde wereldwijde locaties (regio ‘ s). Cloudproviders hebben ook een assortiment van voorverpakte services voor IoT-operaties, waardoor de cloud een voorkeurscentrale platform is voor IoT-implementaties. Maar hoewel cloud computing veel meer dan genoeg middelen en diensten biedt om complexe analytics aan te pakken, kan de dichtstbijzijnde regionale cloudfaciliteit nog steeds honderden kilometers verwijderd zijn van het punt waar gegevens worden verzameld, en zijn verbindingen afhankelijk van dezelfde temperamentvolle internetconnectiviteit die traditionele datacenters ondersteunt. In de praktijk is cloud computing een alternatief — of soms een aanvulling — voor traditionele datacenters. De cloud kan centralized computing veel dichter bij een gegevensbron krijgen, maar niet aan de rand van het netwerk.
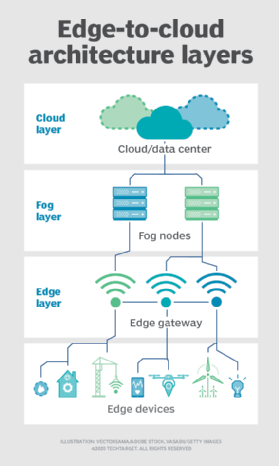
mist. Maar de keuze van compute en storage implementatie is niet beperkt tot de cloud of de edge. Een cloud datacenter kan te ver weg zijn, maar de edge-implementatie kan simpelweg te beperkt zijn, of fysiek verspreid of verspreid, om strikte edge computing praktisch te maken. In dit geval kan de notie van fog computing helpen. Fog computing neemt meestal een stap terug en zet berekenen en opslag middelen ” binnen “de gegevens, maar niet noodzakelijkerwijs” op ” de gegevens.
Fog computing-omgevingen kunnen verbijsterende hoeveelheden sensor-of IoT-gegevens produceren die worden gegenereerd over uitgestrekte fysieke gebieden die gewoon te groot zijn om een rand te definiëren. Voorbeelden hiervan zijn slimme gebouwen, slimme steden of zelfs slimme energienetten. Denk aan een slimme stad waar gegevens kunnen worden gebruikt voor het volgen, analyseren en optimaliseren van het openbaar vervoer, gemeentelijke nutsbedrijven, stadsdiensten en het begeleiden van de lange termijn stedenbouw. Een single edge implementatie is simpelweg niet genoeg om een dergelijke belasting aan te kunnen, dus fog computing kan een reeks van mist node implementaties binnen het bereik van de omgeving bedienen om gegevens te verzamelen, verwerken en analyseren.
Opmerking: Het is belangrijk te herhalen dat fog computing en edge computing een bijna identieke definitie en architectuur delen, en de termen worden soms door elkaar gebruikt, zelfs onder technologie-experts.
Waarom is edge computing belangrijk?
computertaken vereisen geschikte architecturen, en de architectuur die past bij één type computertaak past niet per se bij alle typen computertaken. Edge computing is naar voren gekomen als een levensvatbare en belangrijke architectuur die gedistribueerde computing ondersteunt om reken-en opslagbronnen dichter bij — idealiter op dezelfde fysieke locatie als — de gegevensbron in te zetten. Over het algemeen zijn gedistribueerde computermodellen nauwelijks nieuw, en de concepten van remote offices, filialen, datacenter colocatie en cloud computing hebben een lange en bewezen track record.
maar decentralisatie kan een uitdaging zijn, waarbij hoge niveaus van monitoring en controle vereist zijn die gemakkelijk over het hoofd worden gezien wanneer men afstapt van een traditioneel gecentraliseerd rekenmodel. Edge computing is relevant geworden omdat het een effectieve oplossing biedt voor opkomende netwerkproblemen in verband met het verplaatsen van enorme hoeveelheden gegevens die de hedendaagse organisaties produceren en consumeren. Het is niet alleen een probleem van de hoeveelheid. Het is ook een kwestie van tijd; applicaties zijn afhankelijk van verwerking en reacties die steeds meer tijdgevoelig zijn.
overweeg de opkomst van zelfrijdende auto ‘ s. Ze zijn afhankelijk van intelligente verkeersleidingssignalen. Auto ‘ s en verkeerscontroles MOETEN in realtime gegevens produceren, analyseren en uitwisselen. Vermenigvuldig deze eis met enorme aantallen autonome voertuigen, en de omvang van de potentiële problemen wordt duidelijker. Dit vraagt om een snel en responsief netwerk. Edge-en fog-computing pakt drie belangrijke netwerkbeperkingen aan: bandbreedte, latency en congestie of betrouwbaarheid.
- bandbreedte. Bandbreedte is de hoeveelheid gegevens die een netwerk over de tijd kan dragen, meestal uitgedrukt in bits per seconde. Alle netwerken hebben een beperkte bandbreedte en de limieten zijn strenger voor draadloze communicatie. Dit betekent dat er een eindige limiet is aan de hoeveelheid gegevens — of het aantal apparaten — die gegevens over het netwerk kunnen communiceren. Hoewel het mogelijk is om de bandbreedte van het netwerk te verhogen om meer apparaten en gegevens aan te passen, kunnen de kosten aanzienlijk zijn, zijn er nog steeds (hogere) eindige limieten en het lost andere problemen niet op.
- latentie. Latency is de tijd die nodig is om gegevens te verzenden tussen twee punten op een netwerk. Hoewel communicatie idealiter plaatsvindt met de snelheid van het licht, kunnen grote fysieke afstanden in combinatie met netwerkcongestie of uitval de gegevensbeweging over het netwerk vertragen. Dit vertraagt alle analytics en besluitvorming processen, en vermindert de mogelijkheid voor een systeem om te reageren in real time. Het kostte zelfs levens in het autonome voertuig voorbeeld.
- congestie. Het internet is eigenlijk een wereldwijd ” netwerk van netwerken.”Hoewel het is geëvolueerd om goede algemene gegevensuitwisseling te bieden voor de meeste dagelijkse computertaken-zoals bestandsuitwisselingen of basisstreaming-kan het volume van de gegevens die betrokken zijn bij tientallen miljarden apparaten het internet overweldigen, waardoor hoge niveaus van congestie en het forceren van tijdrovende datatransmissies. In andere gevallen kunnen netwerkuitval congestie verergeren en zelfs de communicatie met sommige internetgebruikers volledig verbreken – waardoor het internet van dingen nutteloos is tijdens uitval.
door servers en opslag te implementeren waar de gegevens worden gegenereerd, kan edge computing veel apparaten bedienen via een veel kleiner en efficiënter LAN waar voldoende bandbreedte uitsluitend wordt gebruikt door lokale gegevensgenererende apparaten, waardoor latency en congestie vrijwel onbestaande zijn. Lokale opslag verzamelt en beschermt de ruwe gegevens, terwijl lokale servers essentiële edge analytics kunnen uitvoeren – of op zijn minst vooraf verwerken en verminderen van de gegevens-om beslissingen te nemen in real time voordat u Resultaten, of gewoon essentiële gegevens, naar de cloud of het centrale datacenter.
use cases and examples
in principe worden edge computing technieken gebruikt voor het verzamelen, filteren, verwerken en analyseren van gegevens “in-place” op of nabij de netwerkrand. Het is een krachtig middel om gegevens te gebruiken die niet eerst naar een centrale locatie kunnen worden verplaatst — meestal omdat de enorme hoeveelheid gegevens zulke bewegingen onbetaalbaar maakt, technologisch onpraktisch of anderszins complianceverplichtingen schendt, zoals datasoevereiniteit. Deze definitie heeft ontelbare voorbeelden en use cases opgeleverd:
- productie. Een industriële fabrikant heeft edge computing ingezet om de productie te monitoren, waardoor real-time analytics en machine learning aan de edge mogelijk zijn om productiefouten te vinden en de kwaliteit van de productie te verbeteren. Edge computing ondersteunde de toevoeging van milieusensoren in de hele fabriek, waardoor inzicht werd verkregen in hoe elk productonderdeel wordt geassembleerd en opgeslagen — en hoe lang de componenten op voorraad blijven. De fabrikant kan nu snellere en nauwkeurigere zakelijke beslissingen nemen met betrekking tot de fabriek en productieactiviteiten.
- landbouw. Denk aan een bedrijf dat gewassen binnenshuis verbouwt zonder zonlicht, grond of pesticiden. Het proces verkort de kweektijden met meer dan 60%. Met behulp van sensoren kan het bedrijf het watergebruik, de nutriëntendichtheid volgen en een optimale oogst bepalen. Gegevens worden verzameld en geanalyseerd om de effecten van omgevingsfactoren te vinden en de algoritmen voor gewasgroei voortdurend te verbeteren en ervoor te zorgen dat gewassen in piekconditie worden geoogst.
- netwerkoptimalisatie. Edge computing kan helpen bij het optimaliseren van netwerkprestaties door de prestaties van gebruikers op het internet te meten en vervolgens analytics te gebruiken om het meest betrouwbare netwerkpad met lage latency te bepalen voor het verkeer van elke gebruiker. In feite wordt edge computing gebruikt om verkeer over het netwerk te” sturen ” voor optimale tijdgevoelige verkeersprestaties.
- veiligheid op het werk. Edge computing kan gegevens van on-site camera ‘ s, veiligheidsvoorzieningen voor werknemers en diverse andere sensoren combineren en analyseren om bedrijven te helpen toezicht te houden op de werkomstandigheden of ervoor te zorgen dat werknemers vastgestelde veiligheidsprotocollen volgen-vooral wanneer de werkplek afgelegen of ongewoon gevaarlijk is, zoals bouwplaatsen of booreilanden.
- verbeterde gezondheidszorg. De gezondheidszorgindustrie heeft de hoeveelheid patiëntgegevens die van apparaten, sensoren en andere medische apparatuur worden verzameld, drastisch uitgebreid. Dat enorme datavolume vereist edge computing om automatisering en machine learning toe te passen om toegang te krijgen tot de gegevens, “normale” gegevens te negeren en probleemgegevens te identificeren, zodat artsen onmiddellijk actie kunnen ondernemen om patiënten te helpen gezondheidsincidenten in real-time te voorkomen.
- vervoer. Autonome voertuigen vereisen en produceren overal van 5 TB tot 20 TB per dag, het verzamelen van informatie over locatie, snelheid, voertuigconditie, wegomstandigheden, verkeersomstandigheden en andere voertuigen. En de gegevens moeten worden geaggregeerd en geanalyseerd in real time, terwijl het voertuig in beweging is. Dit vereist aanzienlijke onboard computing-elk autonoom voertuig wordt een ” rand.”Bovendien kunnen de gegevens overheden en bedrijven helpen om wagenparken te beheren op basis van de feitelijke omstandigheden op de grond.
- Retail. Retailbedrijven kunnen ook enorme datavolumes produceren van bewaking, voorraadbeheer, verkoopgegevens en andere realtime bedrijfsgegevens. Edge computing kan helpen bij het analyseren van deze diverse gegevens en het identificeren van zakelijke kansen, zoals een effectieve endcap of campagne, het voorspellen van de verkoop en het optimaliseren van vendor order, enzovoort. Omdat retailbedrijven sterk kunnen variëren in lokale omgevingen, kan edge computing een effectieve oplossing zijn voor lokale verwerking in elke winkel.
voordelen van edge computing
Edge computing pakt vitale infrastructuuruitdagingen aan — zoals bandbreedtebeperkingen, overmatige latentie en netwerkcongestie — maar er zijn verschillende potentiële extra voordelen aan edge computing die de aanpak aantrekkelijk kunnen maken in andere situaties.
autonomie. Edge computing is nuttig wanneer de connectiviteit onbetrouwbaar is of de bandbreedte beperkt is vanwege de omgevingskenmerken van de site. Voorbeelden zijn booreilanden, schepen op zee, afgelegen boerderijen of andere afgelegen locaties, zoals een regenwoud of woestijn. Edge computing doet het rekenwerk op locatie-soms op het edge-apparaat zelf-zoals waterkwaliteitssensoren op waterzuiveraars in afgelegen dorpen, en kan gegevens opslaan om alleen naar een centraal punt te verzenden wanneer connectiviteit beschikbaar is. Door gegevens lokaal te verwerken, kan de hoeveelheid gegevens die moet worden verzonden aanzienlijk worden verminderd, waardoor veel minder bandbreedte of connectiviteitstijd nodig is dan anders nodig zou zijn.
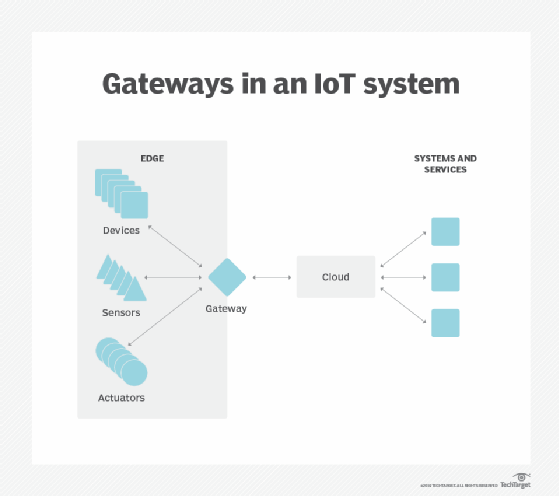
gegevenssoevereiniteit. Het verplaatsen van enorme hoeveelheden data is niet alleen een technisch probleem. De reis van gegevens over nationale en regionale grenzen heen kan extra problemen opleveren voor gegevensbeveiliging, privacy en andere juridische kwesties. Edge computing kan worden gebruikt om gegevens dicht bij de bron te houden en binnen de grenzen van de geldende wetgeving inzake gegevenssoevereiniteit, zoals de AVG van de Europese Unie, die bepaalt hoe gegevens moeten worden opgeslagen, verwerkt en blootgesteld. Hierdoor kunnen ruwe gegevens lokaal worden verwerkt, waardoor gevoelige gegevens worden verduisterd of beveiligd voordat ze naar de cloud of het primaire datacenter worden verzonden, wat in andere rechtsgebieden kan gebeuren.
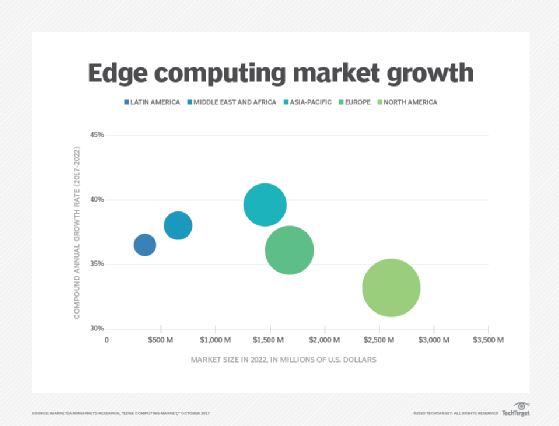
Edge security. Tot slot biedt edge computing een extra mogelijkheid om gegevensbeveiliging te implementeren en te garanderen. Hoewel cloudproviders IoT-diensten hebben en gespecialiseerd zijn in complexe analyse, blijven bedrijven bezorgd over de veiligheid en beveiliging van gegevens zodra deze de rand verlaten en terug naar de cloud of datacenter reizen. Door computing aan de edge te implementeren, kunnen alle gegevens die het netwerk terug naar de cloud of datacenter doorkruisen worden beveiligd door encryptie, en kan de edge-implementatie zelf worden gehard tegen hackers en andere kwaadaardige activiteiten-zelfs als de beveiliging op IoT-apparaten beperkt blijft.
uitdagingen van edge computing
hoewel edge computing het potentieel heeft om overtuigende voordelen te bieden in een groot aantal use cases, is de technologie verre van onfeilbaar. Naast de traditionele problemen van netwerkbeperkingen, zijn er verschillende belangrijke overwegingen die de invoering van edge computing kunnen beïnvloeden:
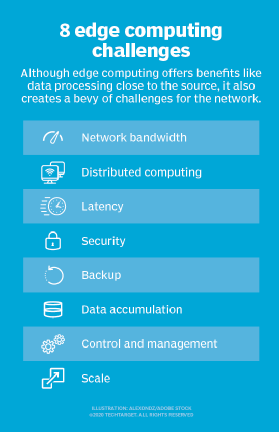
- beperkte mogelijkheden. Een deel van de allure die cloud computing aan edge-of fog-computing brengt, is de verscheidenheid en schaal van de middelen en diensten. Het implementeren van een infrastructuur aan de edge kan effectief zijn, maar de reikwijdte en het doel van de edge-implementatie moet duidelijk worden gedefinieerd — zelfs een uitgebreide edge computing-implementatie dient een specifiek doel op een vooraf bepaalde schaal met beperkte middelen en weinig diensten.
- connectiviteit. Edge computing overwint typische netwerkbeperkingen, maar zelfs de meest vergevingsgezinde Edge-implementatie vereist een minimum aan connectiviteit. Het is van cruciaal belang om een edge-implementatie te ontwerpen die een slechte of grillige connectiviteit mogelijk maakt en na te denken over wat er aan de edge gebeurt als de connectiviteit verloren gaat. Autonomie, AI en sierlijke foutplanning in het kielzog van verbindingsproblemen zijn essentieel voor succesvolle edge computing.
- beveiliging. IoT-apparaten zijn notoir onveilig, dus het is van vitaal belang om een edge computing-implementatie te ontwerpen die de nadruk legt op goed Apparaatbeheer, zoals beleidsgestuurde configuratie-handhaving, evenals beveiliging in de computer-en opslagbronnen-inclusief factoren zoals softwarepatching en updates-met speciale aandacht voor encryptie in de gegevens in rust en in de vlucht. IoT-diensten van grote cloudproviders omvatten beveiligde communicatie, maar dit is niet automatisch bij het bouwen van een edge-site vanaf nul.
- Gegevenslevenscycli. Het vaste probleem met de huidige data glut is dat zoveel van die data onnodig is. Overweeg een medisch monitoringsapparaat — het zijn alleen de probleemgegevens die cruciaal zijn, en het heeft weinig zin om dagen normale patiëntgegevens bij te houden. De meeste gegevens die betrokken zijn bij real-time analytics zijn kortetermijngegevens die niet op de lange termijn worden bewaard. Een bedrijf moet beslissen welke gegevens te bewaren en wat te verwijderen zodra analyses worden uitgevoerd. En de gegevens die worden bewaard, moeten worden beschermd in overeenstemming met het zakelijke en regelgevende beleid.
implementatie van Edge computing
implementatie van Edge computing is een eenvoudig idee dat op papier gemakkelijk lijkt, maar het ontwikkelen van een samenhangende strategie en het implementeren van een goede implementatie aan de edge kan een uitdagende oefening zijn.
het eerste essentiële element van een succesvolle toepassing van technologie is het creëren van een zinvolle zakelijke en technische randstrategie. Een dergelijke strategie gaat niet over het kiezen van Leveranciers of apparatuur. In plaats daarvan houdt een edge-strategie rekening met de noodzaak van edge computing. Het begrijpen van het” waarom ” vraagt om een duidelijk begrip van de technische en zakelijke problemen die de organisatie probeert op te lossen, zoals het overwinnen van netwerkbeperkingen en het observeren van data soevereiniteit.

dergelijke strategieën kunnen beginnen met een discussie over wat de edge betekent, waar het bestaat voor het bedrijf en hoe het de organisatie ten goede moet komen. Edge-strategieën moeten ook aansluiten bij bestaande bedrijfsplannen en stappenplannen voor technologie. Als het bedrijf bijvoorbeeld de voetafdruk van het gecentraliseerde datacenter wil verkleinen, kunnen edge en andere gedistribueerde computingtechnologieën goed op elkaar aansluiten.
naarmate het project dichter bij de implementatie komt, is het belangrijk om de hardware-en softwareopties zorgvuldig te evalueren. Er zijn veel leveranciers in de edge computing-ruimte, waaronder Adlink-technologie, Cisco, Amazon, Dell EMC en HPE. Elk productaanbod moet worden beoordeeld op kosten, prestaties, kenmerken, interoperabiliteit en ondersteuning. Vanuit softwareperspectief moeten tools uitgebreide zichtbaarheid en controle bieden over de externe randomgeving.
de daadwerkelijke implementatie van een edge computing-initiatief kan sterk variëren in omvang en schaal, variërend van een aantal lokale computerapparatuur in een geharde behuizing bovenop een hulpprogramma tot een breed scala aan sensoren die een netwerkverbinding met hoge bandbreedte en lage latentie met de openbare cloud voeden. Geen twee randimplementaties zijn hetzelfde. Het zijn deze variaties die edge strategie en planning zo cruciaal maken voor edge project succes.
een edge-implementatie vereist uitgebreide monitoring. Vergeet niet dat het moeilijk-of zelfs onmogelijk-kan zijn om IT-personeel naar de fysieke edge-site te krijgen, dus edge-implementaties moeten worden ontworpen om veerkracht, fouttolerantie en zelfherstellende mogelijkheden te bieden. Monitoringinstrumenten moeten een duidelijk overzicht bieden van de implementatie op afstand, eenvoudige provisioning en configuratie mogelijk maken, uitgebreide alarmering en rapportage bieden en de beveiliging van de installatie en de gegevens ervan handhaven. Randmonitoring omvat vaak een reeks metrics en KPI ‘ s, zoals beschikbaarheid of uptime van de site, netwerkprestaties, opslagcapaciteit en-gebruik en rekenbronnen.
en geen edge-implementatie zou compleet zijn zonder een zorgvuldige overweging van edge-onderhoud:
- beveiliging. Fysieke en logische veiligheidsmaatregelen zijn van vitaal belang en moeten hulpmiddelen omvatten die de nadruk leggen op kwetsbaarheidsbeheer en inbraakdetectie en-preventie. De beveiliging moet zich uitstrekken tot sensor-en IoT-apparaten, omdat elk apparaat een netwerkelement is dat toegankelijk is of gehackt — dat een verbijsterend aantal mogelijke aanvalsoppervlakken presenteert.
- connectiviteit. Connectiviteit is een ander probleem, en er moeten voorzieningen worden getroffen voor toegang tot controle en rapportage, zelfs wanneer de connectiviteit voor de feitelijke gegevens niet beschikbaar is. Sommige edge-implementaties maken gebruik van een secundaire verbinding voor back-upconnectiviteit en controle.
- Beheer. De afgelegen en vaak onherbergzame locaties van edge-implementaties maken provisioning en beheer op afstand essentieel. IT-managers moeten in staat zijn om te zien wat er aan de rand gebeurt en in staat zijn om de implementatie te controleren wanneer dat nodig is.
- fysiek onderhoud. Fysieke onderhoudsvereisten kunnen niet over het hoofd worden gezien. IoT-apparaten hebben vaak een beperkte levensduur met routinematige batterij-en apparaatvervangingen. Het toestel valt uit en vereist uiteindelijk onderhoud en vervanging. Praktische locatie logistiek moet worden opgenomen met het onderhoud.
Edge computing, IoT en 5G mogelijkheden
Edge computing blijft zich ontwikkelen, met behulp van nieuwe technologieën en praktijken om zijn mogelijkheden en prestaties te verbeteren. Misschien wel de meest opmerkelijke trend is de beschikbaarheid van edge, en edge-diensten zullen naar verwachting wereldwijd beschikbaar zijn tegen 2028. Waar edge computing tegenwoordig vaak situatiespecifiek is, wordt verwacht dat de technologie alomtegenwoordig wordt en de manier waarop het internet wordt gebruikt zal veranderen, waardoor meer abstractie en potentiële use cases voor edge-technologie zullen ontstaan.
dit kan worden gezien in de proliferatie van Computer -, opslag-en netwerkapparatuur producten die speciaal zijn ontworpen voor edge computing. Meer multivendor-partnerschappen zullen een betere productinteroperabiliteit en-flexibiliteit aan de rand mogelijk maken. Een voorbeeld is een partnerschap tussen AWS en Verizon om betere connectiviteit aan de rand te brengen.
draadloze communicatietechnologieën, zoals 5G en Wi-Fi 6, zullen de komende jaren ook van invloed zijn op edge-implementaties en-gebruik, waardoor virtualisatie-en automatiseringsmogelijkheden mogelijk worden die nog moeten worden onderzocht, zoals betere voertuigautonomie en werkbelastingmigraties naar de edge, terwijl draadloze netwerken flexibeler en kosteneffectiever worden.
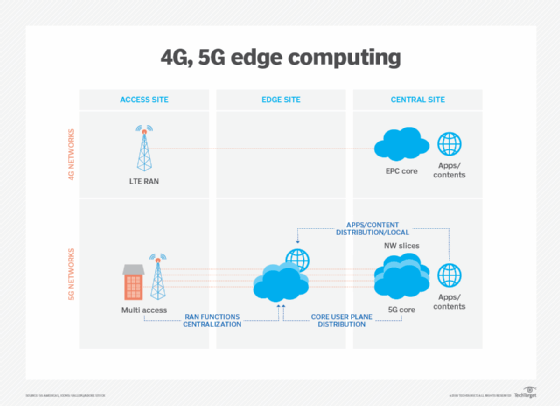
Edge computing kreeg bericht met de opkomst van IoT en de plotselinge overvloed aan gegevens die dergelijke apparaten produceren. Maar met IoT-technologieën nog in de kinderschoenen, zal de evolutie van IoT-apparaten ook een impact hebben op de toekomstige ontwikkeling van edge computing. Een voorbeeld van dergelijke toekomstige alternatieven is de ontwikkeling van micro modulaire datacenters (MMDC ‘ s). De MMDC is in feite een datacenter in een doos, dat een compleet datacenter plaatst in een klein mobiel systeem dat dichter bij data kan worden ingezet — zoals in een stad of regio — om computers veel dichter bij data te krijgen zonder de juiste gegevens te benaderen.