Edge computing Er en distribuert it-arkitektur der klientdata behandles i periferien av nettverket, så nær den opprinnelige kilden som mulig.Data er selve livsnerven i moderne virksomhet, og gir verdifull forretningsinnsikt og støtter sanntidskontroll over kritiske forretningsprosesser og operasjoner. Dagens bedrifter er oversvømt i et hav av data, og store mengder data kan rutinemessig samles inn fra sensorer og iot-enheter som opererer i sanntid fra eksterne steder og ugjestmilde driftsmiljøer nesten hvor som helst i verden.Men denne virtuelle flommen av data endrer også måten bedrifter håndterer databehandling på. Det tradisjonelle databehandlingsparadigmet bygget på et sentralisert datasenter og daglig internett er ikke godt egnet til å flytte uendelige voksende elver av virkelige data. Båndbreddebegrensninger, ventetidsproblemer og uforutsigbare nettverksforstyrrelser kan alle konspirere for å svekke slik innsats. Bedrifter reagerer på disse datautfordringene gjennom bruk av edge computing architecture.i enkleste termer flytter edge computing en del av lagring og beregne ressurser ut av det sentrale datasenteret og nærmere kilden til selve dataene. I stedet for å overføre rådata til et sentralt datasenter for behandling og analyse, utføres dette arbeidet i stedet der dataene faktisk genereres-enten det er en butikk, et fabrikkgulv, et viltvoksende verktøy eller over en smart by. Bare resultatet av dette databehandlingsarbeidet på kanten, for eksempel forretningsinnsikt i sanntid, forutsigelser for utstyrsvedlikehold eller andre handlingsbare svar, sendes tilbake til hoveddatasenteret for gjennomgang og andre menneskelige interaksjoner.dermed omformer edge computing IT og business computing. Ta en omfattende titt på hva edge computing er, hvordan det fungerer, påvirkning av skyen, edge bruk saker, avveininger og implementering hensyn.
hvordan fungerer edge computing?
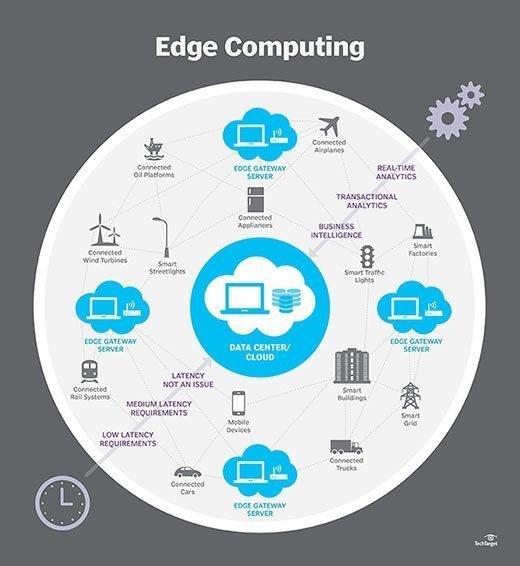
Edge computing er alt et spørsmål om plassering. I tradisjonell enterprise computing produseres data på et klientendepunkt, for eksempel en brukers datamaskin. Disse dataene flyttes over ET WAN som internett, via bedriftens LAN, hvor dataene lagres og bearbeides av en bedriftsapplikasjon. Resultatene av dette arbeidet blir deretter overført tilbake til klientendepunktet. Dette er fortsatt en velprøvd og velprøvd tilnærming til klient-server databehandling for de fleste typiske forretningsapplikasjoner.Men antall enheter som er koblet til internett, og volumet av data som produseres av disse enhetene og brukes av bedrifter, vokser altfor raskt for tradisjonelle datasenterinfrastrukturer å imøtekomme. Gartner spådde at innen 2025 vil 75% av bedriftsgenererte data bli opprettet utenfor sentraliserte datasentre. Utsiktene til å flytte så mye data i situasjoner som ofte kan være tids – eller forstyrrelsessensitive, setter utrolig belastning på det globale internett, som i seg selv ofte er utsatt for overbelastning og forstyrrelse.SÅ IT-arkitekter har skiftet fokus fra det sentrale datasenteret til den logiske kanten av infrastrukturen-tar lagrings-og databehandlingsressurser fra datasenteret og flytter disse ressursene til det punktet der dataene genereres. Prinsippet er enkelt: hvis du ikke kan få dataene nærmere datasenteret, kan du få datasenteret nærmere dataene. Konseptet med edge computing er ikke nytt, og det er forankret i flere tiår gamle ideer om ekstern databehandling-for eksempel eksterne kontorer og avdelingskontorer-hvor det var mer pålitelig og effektivt å plassere databehandlingsressurser på ønsket sted i stedet for å stole på en enkelt sentral plassering.

Edge computing setter lagring og servere der dataene er, og krever ofte lite mer enn en delvis rack av utstyr for å operere på det eksterne LAN for å samle inn og behandle dataene lokalt. I mange tilfeller er datautstyret utplassert i skjermede eller herdede innkapslinger for å beskytte utstyret mot ekstreme temperaturer, fuktighet og andre miljøforhold. Behandling innebærer ofte normalisering og analyse av datastrømmen for å lete etter business intelligence, og bare resultatene av analysen sendes tilbake til hoveddatasenteret.
ideen om business intelligence kan variere dramatisk. Noen eksempler er butikkmiljøer der videoovervåkning av utstillingslokalet kan kombineres med faktiske salgsdata for å bestemme den mest ønskelige produktkonfigurasjonen eller forbrukernes etterspørsel. Andre eksempler omfatter prediktiv analyse som kan veilede vedlikehold og reparasjon av utstyr før faktiske feil eller feil oppstår. Fortsatt andre eksempler er ofte justert med verktøy, for eksempel vannbehandling eller elektrisitetsproduksjon, for å sikre at utstyret fungerer som det skal og for å opprettholde kvaliteten på produksjonen.
Kant vs. sky vs. fog computing
Edge computing er nært knyttet til begrepene cloud computing og fog computing. Selv om det er noen overlapping mellom disse begrepene, de er ikke det samme, og generelt bør ikke brukes om hverandre. Det er nyttig å sammenligne konseptene og forstå forskjellene deres.En av de enkleste måtene å forstå forskjellene mellom edge, cloud og fog computing er å markere deres felles tema: Alle tre konseptene relaterer seg til distribuert databehandling og fokuserer på fysisk distribusjon av beregne-og lagringsressurser i forhold til dataene som blir produsert. Forskjellen er hvor disse ressursene ligger.
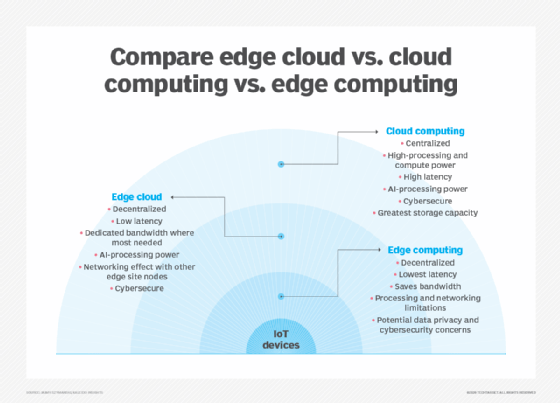
Kant. Edge computing er distribusjon av databehandling og lagringsressurser på stedet der data produseres. Dette setter ideelt beregne og lagring på samme punkt som datakilden på nettverkskanten. For eksempel kan et lite kabinett med flere servere og noe lagring installeres på toppen av en vindturbin for å samle inn og behandle data produsert av sensorer i selve turbinen. Som et annet eksempel kan en jernbanestasjon plassere en beskjeden mengde databehandling og lagring i stasjonen for å samle inn og behandle utallige spor-og jernbanetrafikksensordata. Resultatene av slik behandling kan deretter sendes tilbake til et annet datasenter for menneskelig gjennomgang, arkivering og slås sammen med andre dataresultater for bredere analyse.
Sky. Cloud computing er en stor, svært skalerbar distribusjon av beregne-og lagringsressurser på en av flere distribuerte globale steder (regioner). Skyleverandører inkluderer også et utvalg av ferdigpakkede tjenester for iot-operasjoner, noe som gjør skyen til en foretrukket sentralisert plattform for iot-distribusjoner. Men selv om cloud computing tilbyr langt mer enn nok ressurser og tjenester til å takle komplekse analyser, kan det nærmeste regionale skyanlegget fortsatt være hundrevis av miles fra det punktet hvor data samles inn, og tilkoblinger stole på den samme temperamentelle internett-tilkoblingen som støtter tradisjonelle datasentre. I praksis er cloud computing et alternativ – eller noen ganger et supplement – til tradisjonelle datasentre. Skyen kan få sentralisert databehandling mye nærmere en datakilde, men ikke på nettverkskanten.
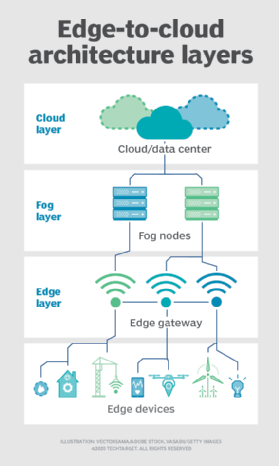
Tåke. Men valget av databehandling og lagring distribusjon er ikke begrenset til skyen eller kanten. Et skydatasenter kan være for langt unna, men edge-distribusjonen kan ganske enkelt være for ressursbegrenset, eller fysisk spredt eller distribuert, for å gjøre streng edge computing praktisk. I dette tilfellet kan begrepet tåkeberegning hjelpe. Fog computing tar vanligvis et skritt tilbake og setter beregne og lagringsressurser «innenfor» dataene, men ikke nødvendigvis » på » dataene.Tåkedatamiljøer kan produsere forvirrende mengder sensor-eller IoT-data generert på tvers av ekspansive fysiske områder som bare er for store til å definere en kant. Eksempler er smarte bygninger, smarte byer eller til og med smarte verktøynett. Tenk på en smart by hvor data kan brukes til å spore, analysere og optimalisere kollektivtransportsystemet, kommunale tjenester, bytjenester og veilede langsiktig byplanlegging. En enkeltkantdistribusjon er ganske enkelt ikke nok til å håndtere en slik belastning, så fog computing kan betjene en rekke tåkenodeutplasseringer innenfor miljøets omfang for å samle, behandle og analysere data.
Merk: det er viktig å gjenta at fog computing og edge computing deler en nesten identisk definisjon og arkitektur, og begrepene brukes noen ganger om hverandre selv blant teknologieksperter.
Hvorfor er edge computing viktig?
Databehandlingsoppgaver krever egnede arkitekturer, og arkitekturen som passer til en type databehandlingsoppgave passer ikke nødvendigvis til alle typer databehandlingsoppgaver. Edge computing har dukket opp som en levedyktig og viktig arkitektur som støtter distribuert databehandling for å distribuere databehandlings-og lagringsressurser nærmere-ideelt sett på samme fysiske sted som-datakilden. Generelt er distribuerte databehandlingsmodeller neppe nye, og konseptene for eksterne kontorer, avdelingskontorer, datasenter colocation og cloud computing har en lang og bevist track record.men desentralisering kan være utfordrende, og krever høye nivåer av overvåking og kontroll som lett overses når man beveger seg bort fra en tradisjonell sentralisert databehandlingsmodell. Edge computing har blitt relevant fordi den gir en effektiv løsning på nye nettverksproblemer knyttet til å flytte enorme datamengder som dagens organisasjoner produserer og forbruker. Det er ikke bare et problem med mengden. Det er også et spørsmål om tid; søknader avhenger av behandling og svar som blir stadig mer tidsfølsomme.
Tenk på økningen av selvkjørende biler. De vil avhenge av intelligente trafikkontrollsignaler. Biler og trafikkontroller må produsere, analysere og utveksle data i sanntid. Multipliser dette kravet med et stort antall autonome kjøretøy, og omfanget av de potensielle problemene blir tydeligere. Dette krever et raskt og responsivt nettverk. Edge-og fog-computing adresserer tre hovednettverksbegrensninger: båndbredde, ventetid og overbelastning eller pålitelighet.
- Båndbredde. Båndbredde er mengden data som et nettverk kan bære over tid, vanligvis uttrykt i biter per sekund. Alle nettverk har begrenset båndbredde, og grensene er strengere for trådløs kommunikasjon. Dette betyr at det er en begrenset grense for mengden data-eller antall enheter – som kan kommunisere data over nettverket. Selv om det er mulig å øke nettverksbåndbredden for å imøtekomme flere enheter og data, kan kostnadene være betydelige, det er fortsatt (høyere) begrensede grenser, og det løser ikke andre problemer.
- Latens. Latency er tiden som trengs for å sende data mellom to punkter på et nettverk. Selv om kommunikasjon ideelt sett foregår med lysets hastighet, kan store fysiske avstander kombinert med nettverksbelastning eller strømbrudd forsinke databevegelsen over nettverket. Dette forsinker analyse – og beslutningsprosesser, og reduserer muligheten for et system til å reagere i sanntid. Det kostet selv liv i det autonome kjøretøyeksemplet.
- Overbelastning. Internett er i utgangspunktet et globalt » nettverk av nettverk.»Selv om det har utviklet seg til å tilby gode generelle datautvekslinger for de fleste daglige databehandlingsoppgaver-for eksempel filutveksling eller grunnleggende streaming-kan volumet av data involvert med titalls milliarder enheter overvelde internett, noe som forårsaker høye nivåer av overbelastning og tvinger tidkrevende dataoverføringer. I andre tilfeller kan nettverksbrudd forverre overbelastning og til og med kutte kommunikasjon til noen internett-brukere helt og holdent-noe som gjør tingenes internett ubrukelig under strømbrudd.ved å distribuere servere og lagring der dataene genereres, kan edge computing betjene mange enheter over et mye mindre OG mer effektivt LAN hvor rikelig båndbredde brukes utelukkende av lokale datagenererende enheter, noe som gjør latens og overbelastning nesten ikke-eksisterende. Lokal lagring samler inn og beskytter rådata, mens lokale servere kan utføre viktige kantanalyser – eller i det minste pre-prosessere og redusere dataene – for å ta beslutninger i sanntid før du sender resultater, eller bare viktige data, til skyen eller sentralt datasenter.
Edge computing brukstilfeller og eksempler
i prinsippet brukes edge computing teknikker til å samle inn, filtrere, behandle og analysere data «på plass» på eller nær nettverkskanten. Det er et kraftig middel til å bruke data som ikke først kan flyttes til et sentralisert sted-vanligvis fordi det store volumet av data gjør slike trekk kostnads uoverkommelige, teknologisk upraktiske eller ellers kan krenke samsvarsforpliktelser, for eksempel datasuverenitet. Denne definisjonen har gytt utallige reelle eksempler og brukstilfeller:
- Produksjon. En industriell produsent distribuerte edge computing for å overvåke produksjonen, noe som muliggjør sanntidsanalyse og maskinlæring på kanten for å finne produksjonsfeil og forbedre produktproduksjonskvaliteten. Edge computing støttet tillegg av miljøsensorer i hele produksjonsanlegget, noe som gir innsikt i hvordan hver produktkomponent er montert og lagret-og hvor lenge komponentene forblir på lager. Produsenten kan nå ta raskere og mer nøyaktige forretningsbeslutninger angående fabrikkanlegg og produksjonsoperasjoner.
- Oppdrett. Vurder en bedrift som vokser avlinger innendørs uten sollys, jord eller plantevernmidler. Prosessen reduserer veksttider med mer enn 60%. Ved hjelp av sensorer kan virksomheten spore vannbruk, næringsstofftetthet og bestemme optimal innhøsting. Data samles inn og analyseres for å finne effekten av miljøfaktorer og kontinuerlig forbedre avlingenes voksende algoritmer og sikre at avlinger høstes i toppform.
- nettverksoptimalisering. Edge computing kan bidra til å optimalisere nettverksytelsen ved å måle ytelsen for brukere over internett og deretter bruke analyser for å bestemme den mest pålitelige nettverksbanen med lav latens for hver brukers trafikk. I virkeligheten brukes edge computing til å «styre» trafikk over nettverket for optimal tidssensitiv trafikkytelse.
- Sikkerhet På Arbeidsplassen. Edge computing kan kombinere og analysere data fra kameraer på stedet, ansattes sikkerhetsinnretninger og forskjellige andre sensorer for å hjelpe bedrifter med å overvåke arbeidsplassforhold eller sikre at ansatte følger etablerte sikkerhetsprotokoller-spesielt når arbeidsplassen er ekstern eller uvanlig farlig, for eksempel byggeplasser eller oljerigger.
- Forbedret helsetjenester. Helsesektoren har dramatisk utvidet mengden pasientdata samlet inn fra enheter, sensorer og annet medisinsk utstyr. Det enorme datamengden krever at edge computing bruker automatisering og maskinlæring for å få tilgang til dataene, ignorerer «normale» data og identifiserer problemdata slik at klinikere kan iverksette umiddelbare tiltak for å hjelpe pasienter med å unngå helsehendelser i sanntid.
- Transport. Autonome kjøretøy krever og produserer alt fra 5 TB til 20 TB per dag, og samler informasjon om plassering, hastighet, kjøretøystilstand, veiforhold, trafikkforhold og andre kjøretøy. Og dataene må aggregeres og analyseres i sanntid, mens kjøretøyet er i bevegelse. Dette krever betydelig innebygd databehandling-hvert autonomt kjøretøy blir en «kant».»I tillegg kan dataene hjelpe myndigheter og bedrifter med å administrere kjøretøyflåter basert på faktiske forhold på bakken.
- Detaljhandel. Detaljhandelsvirksomheter kan også produsere enorme datamengder fra overvåking, lagersporing, salgsdata og andre forretningsdetaljer i sanntid. Edge computing kan bidra til å analysere denne mangfoldige data og identifisere forretningsmuligheter, for eksempel en effektiv endcap eller kampanje, forutsi salg og optimalisere leverandør bestilling, og så videre. Siden detaljhandelsvirksomheter kan variere dramatisk i lokale miljøer, kan edge computing være en effektiv løsning for lokal behandling i hver butikk.
Fordeler med edge computing
Edge computing løser viktige infrastrukturutfordringer-som båndbreddebegrensninger, overflødig ventetid og nettverksbelastning – men det er flere potensielle tilleggsfordeler for edge computing som kan gjøre tilnærmingen tiltalende i andre situasjoner.
Autonomi. Edge computing er nyttig der tilkobling er upålitelig eller båndbredde er begrenset på grunn av områdets miljøegenskaper. Eksempler er oljerigger, skip til sjøs, fjerntliggende gårder eller andre avsidesliggende steder, for eksempel en regnskog eller ørken. Edge computing gjør databehandlingen på stedet-noen ganger på edge-enheten selv – for eksempel vannkvalitetssensorer på vannrensere i fjerntliggende landsbyer, og kan lagre data for å overføre til et sentralt punkt bare når tilkobling er tilgjengelig. Ved å behandle data lokalt, kan mengden data som skal sendes, reduseres betydelig, noe som krever langt mindre båndbredde eller tilkoblingstid enn det som ellers ville være nødvendig.
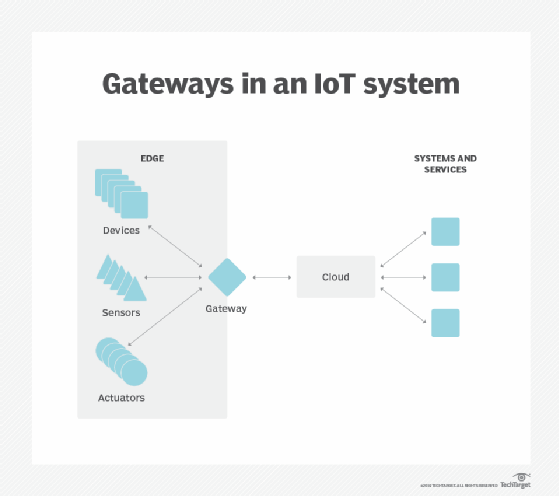
Kantenheter omfatter et bredt spekter av enhetstyper, inkludert sensorer, aktuatorer og andre endepunkter, samt IoT gateways. datasuverenitet. Å flytte store mengder data er ikke bare et teknisk problem. Datas reise over nasjonale og regionale grenser kan utgjøre ytterligere problemer for datasikkerhet, personvern og andre juridiske problemer. Edge computing kan brukes til å holde data nær kilden og innenfor rammene av gjeldende lover om datasuverenitet, for Eksempel Eus GDPR, som definerer hvordan data skal lagres, behandles og eksponeres. Dette kan tillate at rådata behandles lokalt, skjuler eller sikrer sensitive data før de sendes noe til skyen eller primærdatasenteret, som kan være i andre jurisdiksjoner.
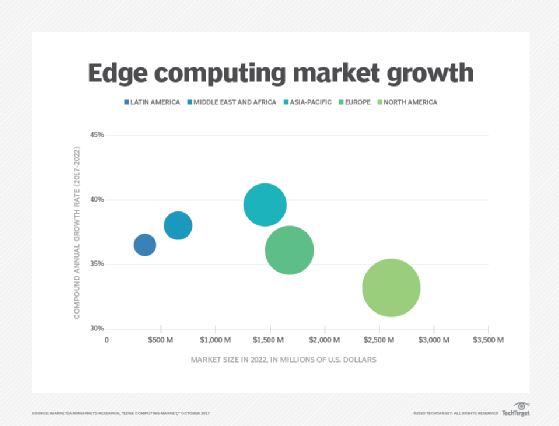
Forskning viser At bevegelsen mot edge computing bare vil øke de neste par årene. Kantsikkerhet. Endelig tilbyr edge computing en ekstra mulighet til å implementere og sikre datasikkerhet. Selv om skyleverandører har iot-tjenester og spesialiserer seg på kompleks analyse, forblir bedrifter bekymret for sikkerheten til data når den forlater kanten og reiser tilbake til skyen eller datasenteret. Ved å implementere databehandling på kanten, kan alle data som går gjennom nettverket tilbake til skyen eller datasenteret sikres gjennom kryptering, og selve edge-distribusjonen kan herdes mot hackere og andre ondsinnede aktiviteter-selv når sikkerheten på iot-enheter forblir begrenset.
Utfordringer med edge computing
selv om edge computing har potensial til å gi overbevisende fordeler på tvers av en rekke brukstilfeller, er teknologien langt fra idiotsikker. Utover de tradisjonelle problemene med nettverksbegrensninger, er det flere viktige hensyn som kan påvirke innføringen av edge computing:
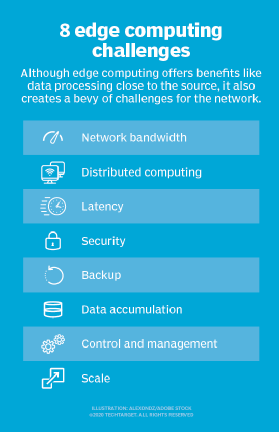
- Begrenset kapasitet. En del av allure som cloud computing bringer til edge-eller fog-databehandling er variasjonen og omfanget av ressursene og tjenestene. Distribusjon av en infrastruktur ved kanten kan være effektiv, men omfanget og formålet med edge-distribusjonen må være klart definert-selv en omfattende edge computing-distribusjon tjener et bestemt formål i en forhåndsbestemt skala ved hjelp av begrensede ressurser og få tjenester.
- Tilkobling. Edge computing overvinner typiske nettverksbegrensninger, men selv den mest tilgivende edge-distribusjonen vil kreve noe minimumsnivå av tilkobling. Det er viktig å designe en edge-distribusjon som imøtekommer dårlig eller uregelmessig tilkobling, og vurdere hva som skjer ved kanten når tilkoblingen går tapt. Autonomi, AI og grasiøs feilplanlegging i kjølvannet av tilkoblingsproblemer er avgjørende for vellykket edge computing.
- Sikkerhet. IoT-enheter er notorisk usikre, så det er viktig å designe en edge computing-distribusjon som vil understreke riktig enhetsadministrasjon, for eksempel policydrevet konfigurasjonshåndhevelse, samt sikkerhet i databehandlings-og lagringsressursene-inkludert faktorer som programvarepatching og oppdateringer-med spesiell oppmerksomhet til kryptering i dataene i ro og i flukt. Iot-tjenester fra store skyleverandører inkluderer sikker kommunikasjon, men dette er ikke automatisk når du bygger et edge-nettsted fra bunnen av.
- data livssykluser. Det staude problemet med dagens data glut er at sa mye av disse dataene er unodvendig. Vurder en medisinsk overvåkingsenhet – det er bare problemdataene som er kritiske, og det er lite poeng i å holde dager med normale pasientdata. De fleste dataene som er involvert i sanntidsanalyse, er kortsiktige data som ikke holdes på lang sikt. En bedrift må bestemme hvilke data som skal beholdes og hva som skal kastes når analyser er utført. Og dataene som beholdes, må beskyttes i samsvar med forretnings-og forskriftspolicyer.
Edge computing implementering
Edge computing er en grei ide som kan se lett ut på papir, men å utvikle en sammenhengende strategi og implementere en lyddistribusjon ved kanten kan være en utfordrende øvelse.det første viktige elementet i enhver vellykket teknologiutrulling er etableringen av en meningsfylt forretnings-og teknisk kantstrategi. En slik strategi handler ikke om å plukke leverandører eller utstyr. I stedet vurderer en edge-strategi behovet for edge computing. Å forstå «hvorfor» krever en klar forståelse av de tekniske og forretningsmessige problemene som organisasjonen prøver å løse, for eksempel å overvinne nettverksbegrensninger og observere datasuverenitet.

et kantdatasenter krever nøye planlegging og migreringsstrategier på forhånd. slike strategier kan starte med en diskusjon om akkurat hva kanten betyr, hvor den eksisterer for virksomheten og hvordan den skal være til nytte for organisasjonen. Edge strategier bør også justere med eksisterende forretningsplaner og teknologi veikart. For eksempel, hvis virksomheten søker å redusere sitt sentraliserte datasenterfotavtrykk, kan edge og andre distribuerte datateknologier justere seg godt.
når prosjektet nærmer seg implementering, er det viktig å vurdere maskinvare-og programvarealternativer nøye. Det er mange leverandører i edge computing plass, inkludert Adlink Technology, Cisco, Amazon, Dell EMC og HPE. Hvert produkttilbud må evalueres for kostnader, ytelse, funksjoner, interoperabilitet og støtte. Fra et programvareperspektiv bør verktøyene gi omfattende synlighet og kontroll over det eksterne kantmiljøet.den faktiske distribusjonen av et edge computing-initiativ kan variere dramatisk i omfang og skala, alt fra noe lokalt datautstyr i et kampherdet kabinett på toppen av et verktøy til et stort utvalg av sensorer som mater en nettverksforbindelse med høy båndbredde og lav latens til den offentlige skyen. Ingen to edge-distribusjoner er de samme. Det er disse variasjonene som gjør edge strategi og planlegging så avgjørende for edge prosjekt suksess.
en kantdistribusjon krever omfattende overvåking. Husk at DET kan være vanskelig-eller umulig-å få IT-ansatte til det fysiske edge-området, så edge-distribusjoner bør utformes for å gi motstandskraft, feiltoleranse og selvhelbredende evner. Overvåkingsverktøy må gi en klar oversikt over den eksterne distribusjonen, muliggjøre enkel klargjøring og konfigurasjon, tilby omfattende varsling og rapportering og opprettholde sikkerheten til installasjonen og dens data. Kantovervåking innebærer ofte en rekke beregninger og Kpier, for eksempel tilgjengelighet eller oppetid på nettstedet, nettverksytelse, lagringskapasitet og-utnyttelse og databehandlingsressurser.
og ingen edge implementering ville være komplett uten en nøye vurdering av edge vedlikehold:
- Sikkerhet. Fysiske og logiske sikkerhetsforanstaltninger er avgjørende og bør innebære verktøy som legger vekt på sårbarhetsstyring og inntrengningsdeteksjon og forebygging. Sikkerhet må utvides til sensor-og iot-enheter, da hver enhet er et nettverkselement som kan nås eller hackes-og presenterer et forvirrende antall mulige angrepsflater.
- Tilkobling. Tilkobling er et annet problem, og det må gjøres bestemmelser for tilgang til kontroll og rapportering selv når tilkobling for de faktiske dataene ikke er tilgjengelig. Noen edge-distribusjoner bruker en sekundær tilkobling for backup-tilkobling og kontroll.
- Ledelse. De eksterne og ofte ugjestmilde plasseringene til edge-distribusjoner gjør ekstern klargjøring og administrasjon avgjørende. IT-ledere må kunne se hva som skjer på kanten og kunne kontrollere distribusjonen når det er nødvendig.
- Fysisk vedlikehold. Fysiske vedlikeholdskrav kan ikke overses. IoT-enheter har ofte begrenset levetid med rutinemessige batteri-og enhetsutskiftninger. Utstyret svikter og krever til slutt vedlikehold og utskifting. Praktisk stedlogistikk må inkluderes ved vedlikehold.
Edge computing, Iot og 5g muligheter
Edge computing fortsetter å utvikle seg, ved hjelp av ny teknologi og praksis for å forbedre sine evner og ytelse. Kanskje den mest bemerkelsesverdige trenden er edge-tilgjengelighet, og edge-tjenester forventes å bli tilgjengelige over hele verden innen 2028. Der edge computing ofte er situasjonsspesifikk i dag, forventes teknologien å bli mer allestedsnærværende og skifte måten internett brukes på, noe som gir mer abstraksjon og potensielle brukssaker for kantteknologi.
dette kan sees i spredning av compute, lagring og nettverk apparatet produkter spesielt utviklet for edge computing. Flere partnerskap med flere leverandører vil muliggjøre bedre interoperabilitet og fleksibilitet i forkant. Et eksempel inkluderer et partnerskap MELLOM AWS og Verizon for å gi bedre tilkobling til kanten.Trådløse kommunikasjonsteknologier, SOM 5G og Wi-Fi 6, vil også påvirke edge-distribusjoner og-utnyttelse i de kommende årene, noe som muliggjør virtualiserings-og automatiseringsfunksjoner som ennå ikke er utforsket, for eksempel bedre kjøretøyautonomi og arbeidsmigrasjoner til kanten, samtidig som trådløse nettverk blir mer fleksible og kostnadseffektive.
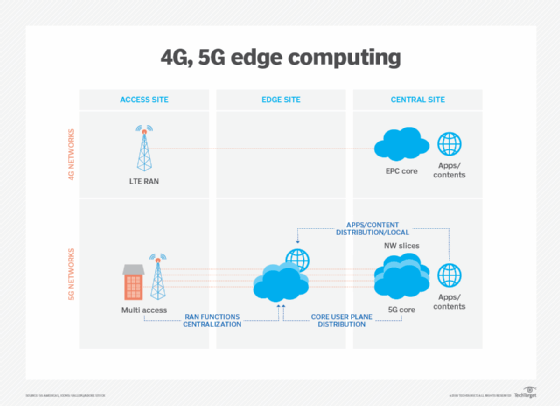
dette diagrammet viser i detalj hvordan 5G gir betydelige fremskritt for edge computing og kjernenettverk over 4g og LTE evner. Edge computing fikk varsel med økningen av IoT og den plutselige mengden data slike enheter produserer. Men med IoT-teknologier fortsatt i relativ barndom, vil utviklingen av iot-enheter også ha innvirkning på den fremtidige utviklingen av edge computing. Et eksempel på slike fremtidige alternativer er utviklingen av mikromodulære datasentre (MMDCs). MMDC er i utgangspunktet et datasenter i en boks, og legger et komplett datasenter i et lite mobilsystem som kan distribueres nærmere data-for eksempel over en by eller en region – for å få databehandling mye nærmere data uten å sette kanten på dataene riktig.