L’edge computing è un’architettura IT (Distributed Information Technology) in cui i dati del client vengono elaborati alla periferia della rete, il più vicino possibile alla fonte di origine.
I dati sono la linfa vitale del business moderno, fornendo preziose informazioni aziendali e supportando il controllo in tempo reale su processi e operazioni aziendali critici. Le aziende di oggi sono inondate da un oceano di dati e enormi quantità di dati possono essere raccolti regolarmente da sensori e dispositivi IoT che operano in tempo reale da postazioni remote e ambienti operativi inospitali quasi ovunque nel mondo.
Ma questa marea virtuale di dati sta anche cambiando il modo in cui le aziende gestiscono l’informatica. Il paradigma di calcolo tradizionale costruito su un data center centralizzato e su Internet di tutti i giorni non è adatto a spostare fiumi di dati reali in continua crescita. Limitazioni della larghezza di banda, problemi di latenza e interruzioni di rete imprevedibili possono tutti cospirare per compromettere tali sforzi. Le aziende stanno rispondendo a queste sfide di dati attraverso l’uso di architettura edge computing.
In termini più semplici, l’edge computing sposta parte delle risorse di archiviazione e di elaborazione dal data center centrale e più vicino all’origine dei dati stessi. Piuttosto che trasmettere dati grezzi a un data center centrale per l’elaborazione e l’analisi, quel lavoro viene invece eseguito dove i dati vengono effettivamente generati-che si tratti di un negozio al dettaglio, di un impianto di fabbrica, di un’utilità tentacolare o in una città intelligente. Solo il risultato di tale lavoro di elaborazione all’edge, come informazioni aziendali in tempo reale, previsioni di manutenzione delle apparecchiature o altre risposte attuabili, viene inviato al data center principale per la revisione e altre interazioni umane.
Così, edge computing sta rimodellando IT e business computing. Dai un’occhiata completa a cos’è l’edge computing, come funziona, l’influenza del cloud, i casi d’uso edge, i compromessi e le considerazioni sull’implementazione.
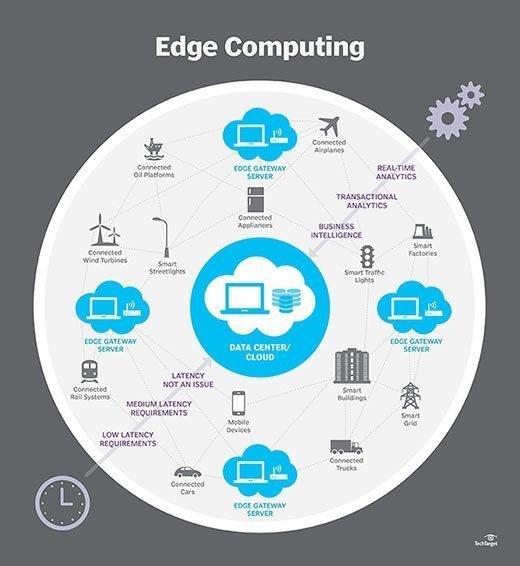
Come funziona l’edge computing?
Edge computing è tutta una questione di posizione. Nell’elaborazione aziendale tradizionale, i dati vengono prodotti su un endpoint client, ad esempio sul computer di un utente. Tali dati vengono spostati attraverso una WAN come Internet, attraverso la LAN aziendale, dove i dati vengono memorizzati e elaborati da un’applicazione aziendale. I risultati di tale lavoro vengono quindi riportati all’endpoint del client. Questo rimane un approccio collaudato e collaudato nel tempo per il calcolo client-server per la maggior parte delle applicazioni aziendali tipiche.
Ma il numero di dispositivi connessi a Internet e il volume di dati prodotti da tali dispositivi e utilizzati dalle aziende, sta crescendo troppo rapidamente per consentire alle infrastrutture dei data center tradizionali di adattarsi. Gartner ha previsto che entro il 2025, il 75% dei dati generati dalle aziende verrà creato al di fuori dei data center centralizzati. La prospettiva di spostare così tanti dati in situazioni che spesso possono essere sensibili al tempo o all’interruzione mette a dura prova l’Internet globale, che a sua volta è spesso soggetta a congestione e interruzioni.
Così gli architetti IT hanno spostato l’attenzione dal data center centrale al bordo logico dell’infrastruttura-prendendo le risorse di storage e di calcolo dal data center e spostando tali risorse al punto in cui i dati vengono generati. Il principio è semplice: se non è possibile ottenere i dati più vicino al data center, ottenere il data center più vicino ai dati. Il concetto di edge computing non è nuovo, ed è radicato in idee decennali di calcolo remoto-come uffici remoti e filiali-dove era più affidabile ed efficiente posizionare le risorse di calcolo nella posizione desiderata piuttosto che fare affidamento su un’unica posizione centrale.

Edge computing mette storage e server dove si trovano i dati, spesso richiedendo poco più di un rack parziale di attrezzi per operare sulla LAN remota per raccogliere ed elaborare i dati localmente. In molti casi, l’ingranaggio di calcolo viene distribuito in involucri schermati o induriti per proteggere l’ingranaggio da temperature estreme, umidità e altre condizioni ambientali. L’elaborazione spesso comporta la normalizzazione e l’analisi del flusso di dati per cercare la business intelligence e solo i risultati dell’analisi vengono inviati al data center principale.
L’idea di business intelligence può variare notevolmente. Alcuni esempi includono ambienti di vendita al dettaglio in cui la videosorveglianza del pavimento dello showroom potrebbe essere combinata con dati di vendita effettivi per determinare la configurazione del prodotto più desiderabile o la domanda dei consumatori. Altri esempi riguardano l’analisi predittiva che può guidare la manutenzione e la riparazione delle apparecchiature prima che si verifichino difetti o guasti effettivi. Ancora altri esempi sono spesso allineati con le utility, come il trattamento delle acque o la generazione di elettricità, per garantire che le apparecchiature funzionino correttamente e per mantenere la qualità della produzione.
Bordo vs. cloud vs. fog computing
L’edge computing è strettamente associato ai concetti di cloud computing e fog computing. Sebbene ci sia una certa sovrapposizione tra questi concetti, non sono la stessa cosa e generalmente non dovrebbero essere usati in modo intercambiabile. È utile confrontare i concetti e capire le loro differenze.
Uno dei modi più semplici per capire le differenze tra edge, cloud e fog computing è quello di evidenziare il loro tema comune: Tutti e tre i concetti si riferiscono al calcolo distribuito e si concentrano sulla distribuzione fisica delle risorse di elaborazione e archiviazione in relazione ai dati che vengono prodotti. La differenza è una questione di dove si trovano tali risorse.
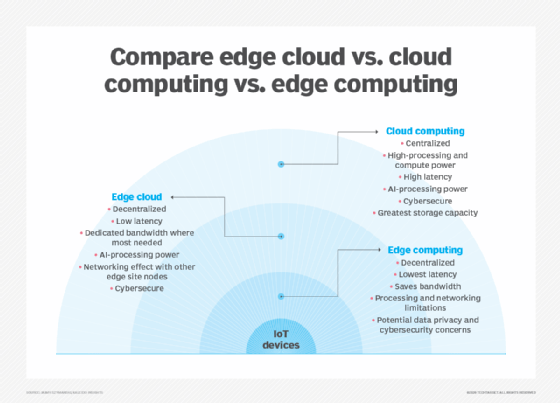
Bordo. L’edge computing è la distribuzione di risorse di elaborazione e archiviazione nella posizione in cui vengono prodotti i dati. Questo pone idealmente l’elaborazione e l’archiviazione nello stesso punto dell’origine dati sul bordo della rete. Ad esempio, un piccolo contenitore con diversi server e alcuni storage potrebbe essere installato in cima a una turbina eolica per raccogliere ed elaborare i dati prodotti dai sensori all’interno della turbina stessa. Come altro esempio, una stazione ferroviaria potrebbe inserire una modesta quantità di elaborazione e archiviazione all’interno della stazione per raccogliere ed elaborare una miriade di dati sui sensori del traffico ferroviario e ferroviario. I risultati di tale elaborazione possono quindi essere inviati a un altro data center per la revisione umana, l’archiviazione e per essere uniti ad altri risultati di dati per analisi più ampie.
Nuvola. Il cloud computing è una distribuzione enorme e altamente scalabile di risorse di elaborazione e storage in una delle numerose sedi globali distribuite (regioni). I cloud provider incorporano anche un assortimento di servizi preconfezionati per le operazioni IoT, rendendo il cloud una piattaforma centralizzata preferita per le distribuzioni IoT. Ma anche se il cloud computing offre risorse e servizi molto più che sufficienti per affrontare analisi complesse, la struttura cloud regionale più vicina può ancora essere a centinaia di miglia dal punto in cui vengono raccolti i dati e le connessioni si basano sulla stessa connettività Internet temperamentale che supporta i data center tradizionali. In pratica, il cloud computing è un’alternativa-o talvolta un complemento-ai data center tradizionali. Il cloud può ottenere un’elaborazione centralizzata molto più vicina a un’origine dati, ma non ai margini della rete.
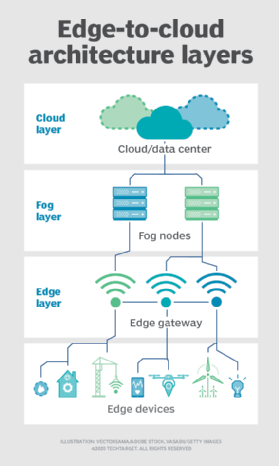
Nebbia. Ma la scelta della distribuzione di elaborazione e storage non è limitata al cloud o all’edge. Un data center cloud potrebbe essere troppo lontano, ma la distribuzione edge potrebbe semplicemente essere troppo limitata dalle risorse, o fisicamente dispersa o distribuita, per rendere pratico il calcolo edge rigoroso. In questo caso, la nozione di fog computing può aiutare. Fog computing in genere fa un passo indietro e mette le risorse di calcolo e archiviazione “all’interno” dei dati, ma non necessariamente “a” i dati.
Gli ambienti di Fog computing possono produrre quantità sconcertanti di dati di sensori o IoT generati in aree fisiche estese che sono troppo grandi per definire un edge. Gli esempi includono edifici intelligenti, città intelligenti o anche reti di utilità intelligenti. Considera una città intelligente in cui i dati possono essere utilizzati per tracciare, analizzare e ottimizzare il sistema di trasporto pubblico, le utenze municipali, i servizi urbani e guidare la pianificazione urbana a lungo termine. Una singola distribuzione edge semplicemente non è sufficiente per gestire tale carico, quindi fog computing può gestire una serie di distribuzioni di nodi fog nell’ambito dell’ambiente per raccogliere, elaborare e analizzare i dati.
Nota: È importante ripetere che fog computing e edge computing condividono una definizione e un’architettura quasi identiche, e i termini sono talvolta usati in modo intercambiabile anche tra gli esperti di tecnologia.
Perché l’edge computing è importante?
Le attività di calcolo richiedono architetture adeguate e l’architettura adatta a un tipo di attività di calcolo non si adatta necessariamente a tutti i tipi di attività di calcolo. L’edge computing è emerso come un’architettura valida e importante che supporta il calcolo distribuito per distribuire risorse di elaborazione e archiviazione più vicine-idealmente nella stessa posizione fisica-all’origine dati. In generale, i modelli di calcolo distribuito non sono affatto nuovi e i concetti di uffici remoti, filiali, colocation di data center e cloud computing hanno una lunga e comprovata esperienza.
Ma il decentramento può essere impegnativo, richiedendo alti livelli di monitoraggio e controllo che sono facilmente trascurati quando ci si allontana da un modello di calcolo centralizzato tradizionale. L’edge computing è diventato rilevante perché offre una soluzione efficace ai problemi di rete emergenti associati allo spostamento di enormi volumi di dati che le organizzazioni odierne producono e consumano. Non è solo un problema di quantità. È anche una questione di tempo; le applicazioni dipendono dall’elaborazione e dalle risposte che sono sempre più sensibili al tempo.
Considera l’ascesa delle auto a guida autonoma. Dipenderanno da segnali di controllo del traffico intelligenti. Le auto e i controlli del traffico dovranno produrre, analizzare e scambiare dati in tempo reale. Moltiplicare questo requisito per un numero enorme di veicoli autonomi e la portata dei potenziali problemi diventa più chiara. Ciò richiede una rete veloce e reattiva. Edge computing e fog computing computing risolve tre principali limitazioni di rete: larghezza di banda, latenza e congestione o affidabilità.
- Larghezza di banda. La larghezza di banda è la quantità di dati che una rete può trasportare nel tempo, solitamente espressa in bit al secondo. Tutte le reti hanno una larghezza di banda limitata e i limiti sono più severi per la comunicazione wireless. Ciò significa che esiste un limite finito alla quantità di dati-o al numero di dispositivi-che possono comunicare dati attraverso la rete. Sebbene sia possibile aumentare la larghezza di banda della rete per ospitare più dispositivi e dati, il costo può essere significativo, ci sono ancora limiti finiti (più alti) e non risolve altri problemi.
- Latenza. La latenza è il tempo necessario per inviare dati tra due punti di una rete. Sebbene la comunicazione avvenga idealmente alla velocità della luce, grandi distanze fisiche associate a congestione o interruzioni della rete possono ritardare il movimento dei dati attraverso la rete. Ciò ritarda qualsiasi analisi e processo decisionale e riduce la capacità di un sistema di rispondere in tempo reale. E ‘ anche costato vite nell’esempio veicolo autonomo.
- Congestione. Internet è fondamentalmente una “rete globale di reti”.”Sebbene si sia evoluto per offrire buoni scambi di dati generici per la maggior parte delle attività di calcolo quotidiane-come scambi di file o streaming di base-il volume di dati coinvolti con decine di miliardi di dispositivi può sopraffare Internet, causando alti livelli di congestione e costringendo a lunghe ritrasmissioni di dati. In altri casi, le interruzioni di rete possono esacerbare la congestione e persino interrompere completamente la comunicazione con alcuni utenti di Internet, rendendo l’Internet delle cose inutile durante le interruzioni.
Implementando server e storage in cui vengono generati i dati, l’edge computing può far funzionare molti dispositivi su una LAN molto più piccola ed efficiente in cui un’ampia larghezza di banda viene utilizzata esclusivamente da dispositivi locali che generano dati, rendendo latenza e congestione praticamente inesistenti. Lo storage locale raccoglie e protegge i dati grezzi, mentre i server locali possono eseguire analisi edge essenziali-o almeno pre-elaborare e ridurre i dati-per prendere decisioni in tempo reale prima di inviare risultati, o solo dati essenziali, al cloud o al data center centrale.
Casi d’uso ed esempi di edge computing
In linea di principio, le tecniche di edge computing sono utilizzate per raccogliere, filtrare, elaborare e analizzare i dati “sul posto” presso o vicino al bordo della rete. È un potente mezzo per utilizzare i dati che non possono essere prima spostati in una posizione centralizzata-di solito perché l’enorme volume di dati rende tali mosse proibitive, tecnologicamente impraticabili o potrebbero altrimenti violare gli obblighi di conformità, come la sovranità dei dati. Questa definizione ha generato una miriade di esempi e casi d’uso reali:
- Manufacturing. Un produttore industriale ha implementato l’edge computing per monitorare la produzione, consentendo analisi in tempo reale e apprendimento automatico all’edge per trovare errori di produzione e migliorare la qualità di produzione del prodotto. L’edge computing ha supportato l’aggiunta di sensori ambientali in tutto lo stabilimento di produzione, fornendo informazioni su come ogni componente del prodotto viene assemblato e immagazzinato — e per quanto tempo i componenti rimangono in magazzino. Il produttore può ora prendere decisioni aziendali più rapide e accurate per quanto riguarda l’impianto di fabbrica e le operazioni di produzione.
- Agricoltura. Considera un’azienda che coltiva colture in ambienti chiusi senza luce solare, suolo o pesticidi. Il processo riduce i tempi di crescita di oltre il 60%. L’utilizzo di sensori consente all’azienda di monitorare l’uso di acqua, la densità dei nutrienti e determinare il raccolto ottimale. I dati vengono raccolti e analizzati per trovare gli effetti dei fattori ambientali e migliorare continuamente gli algoritmi di coltivazione delle colture e garantire che le colture siano raccolte in condizioni ottimali.
- Ottimizzazione della rete. L’edge computing può aiutare a ottimizzare le prestazioni della rete misurando le prestazioni per gli utenti su Internet e quindi impiegando analisi per determinare il percorso di rete più affidabile e a bassa latenza per il traffico di ciascun utente. In effetti, l’edge computing viene utilizzato per” indirizzare ” il traffico attraverso la rete per prestazioni ottimali del traffico sensibili al tempo.
- Sicurezza sul lavoro. Edge computing può combinare e analizzare i dati provenienti da telecamere in loco, dispositivi di sicurezza dei dipendenti e vari altri sensori per aiutare le aziende a sorvegliare le condizioni di lavoro o garantire che i dipendenti seguano i protocolli di sicurezza stabiliti, specialmente quando il posto di lavoro è remoto o insolitamente pericoloso, come i cantieri o le piattaforme petrolifere.
- Assistenza sanitaria migliorata. Il settore sanitario ha notevolmente ampliato la quantità di dati dei pazienti raccolti da dispositivi, sensori e altre apparecchiature mediche. Questo enorme volume di dati richiede l’edge computing per applicare l’automazione e l’apprendimento automatico per accedere ai dati, ignorare i dati “normali” e identificare i dati problematici in modo che i medici possano agire immediatamente per aiutare i pazienti a evitare incidenti di salute in tempo reale.
- Trasporti. I veicoli autonomi richiedono e producono ovunque da 5 TB a 20 TB al giorno, raccogliendo informazioni su posizione, velocità, condizioni del veicolo, condizioni della strada, condizioni del traffico e altri veicoli. E i dati devono essere aggregati e analizzati in tempo reale, mentre il veicolo è in movimento. Ciò richiede un significativo calcolo a bordo each ogni veicolo autonomo diventa un ” bordo.”Inoltre, i dati possono aiutare le autorità e le aziende a gestire le flotte di veicoli in base alle condizioni reali sul terreno.
- Vendita al dettaglio. Le aziende al dettaglio possono anche produrre enormi volumi di dati da sorveglianza, monitoraggio delle scorte, dati di vendita e altri dettagli aziendali in tempo reale. L’edge computing può aiutare ad analizzare questi diversi dati e identificare le opportunità di business, come un endcap o una campagna efficace, prevedere le vendite e ottimizzare gli ordini dei fornitori e così via. Poiché le attività di vendita al dettaglio possono variare notevolmente negli ambienti locali, l’edge computing può essere una soluzione efficace per l’elaborazione locale in ogni negozio.
Vantaggi dell’edge computing
L’edge computing affronta sfide infrastrutturali vitali, come limitazioni della larghezza di banda, latenza eccessiva e congestione della rete, ma ci sono diversi potenziali vantaggi aggiuntivi per l’edge computing che possono rendere l’approccio attraente in altre situazioni.
Autonomia. L’edge computing è utile quando la connettività è inaffidabile o la larghezza di banda è limitata a causa delle caratteristiche ambientali del sito. Gli esempi includono piattaforme petrolifere, navi in mare, fattorie remote o altre località remote, come una foresta pluviale o un deserto. Edge computing fa il lavoro di calcolo in loco-a volte sul dispositivo bordo stesso-come sensori di qualità dell’acqua su depuratori d’acqua in villaggi remoti, e può salvare i dati per trasmettere a un punto centrale solo quando la connettività è disponibile. Elaborando i dati localmente, la quantità di dati da inviare può essere notevolmente ridotta, richiedendo molto meno larghezza di banda o tempo di connettività di quanto potrebbe essere altrimenti necessario.
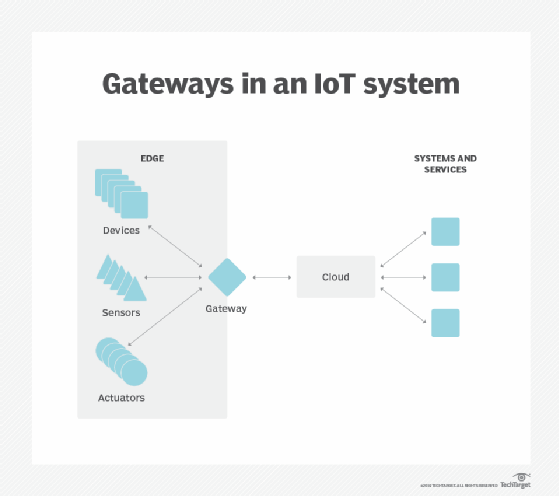
Sovranità dei dati. Spostare enormi quantità di dati non è solo un problema tecnico. Il viaggio dei dati attraverso i confini nazionali e regionali può porre ulteriori problemi per la sicurezza dei dati, la privacy e altre questioni legali. L’edge computing può essere utilizzato per mantenere i dati vicini alla fonte e entro i limiti delle leggi prevalenti sulla sovranità dei dati, come il GDPR dell’Unione europea, che definisce come i dati devono essere archiviati, elaborati ed esposti. Ciò può consentire l’elaborazione locale dei dati grezzi, oscurando o proteggendo i dati sensibili prima di inviare qualsiasi cosa al cloud o al data center primario, che può essere in altre giurisdizioni.
Sicurezza dei bordi. Infine, l’edge computing offre un’ulteriore opportunità per implementare e garantire la sicurezza dei dati. Sebbene i fornitori di cloud dispongano di servizi IoT e siano specializzati in analisi complesse, le aziende rimangono preoccupate per la sicurezza e la sicurezza dei dati una volta che lasciano il bordo e tornano al cloud o al data center. Implementando l’elaborazione all’edge, tutti i dati che attraversano la rete verso il cloud o il data center possono essere protetti tramite crittografia e la distribuzione edge stessa può essere rafforzata contro hacker e altre attività dannose, anche quando la sicurezza sui dispositivi IoT rimane limitata.
Sfide dell’edge computing
Sebbene l’edge computing abbia il potenziale per fornire vantaggi convincenti in una moltitudine di casi d’uso, la tecnologia è tutt’altro che infallibile. Al di là dei problemi tradizionali di limitazioni di rete, ci sono diverse considerazioni chiave che possono influenzare l’adozione di edge computing:
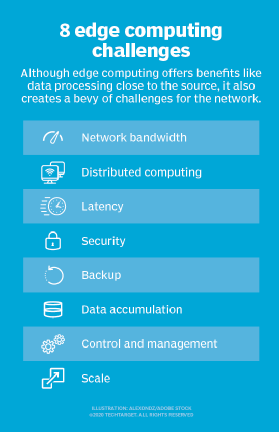
- Capacità limitata. Parte del fascino che il cloud computing porta a edge-o fog-computing è la varietà e la scala delle risorse e dei servizi. La distribuzione di un’infrastruttura all’edge può essere efficace, ma l’ambito e lo scopo della distribuzione edge devono essere chiaramente definiti: anche una distribuzione estesa di edge computing serve a uno scopo specifico a una scala predeterminata utilizzando risorse limitate e pochi servizi.
- Connettività. L’edge computing supera le tipiche limitazioni di rete, ma anche la distribuzione edge più tollerante richiederà un livello minimo di connettività. È fondamentale progettare una distribuzione edge che soddisfi una connettività scarsa o irregolare e considerare cosa succede all’edge quando la connettività viene persa. L’autonomia, l’IA e la pianificazione dei guasti aggraziata sulla scia dei problemi di connettività sono essenziali per il successo dell’edge computing.
- Sicurezza. I dispositivi IoT sono notoriamente insicuri, quindi è fondamentale progettare una distribuzione di edge computing che enfatizzi la corretta gestione dei dispositivi, come l’applicazione della configurazione basata su policy, nonché la sicurezza delle risorse di elaborazione e archiviazione, inclusi fattori quali patch e aggiornamenti del software, con particolare attenzione alla crittografia dei dati a riposo e in volo. I servizi IoT dei principali fornitori di cloud includono comunicazioni sicure, ma questo non è automatico quando si crea un sito edge da zero.
- Cicli di vita dei dati. Il problema perenne con l’eccesso di dati di oggi è che così tanto di quei dati non è necessario. Considera un dispositivo di monitoraggio medico – sono solo i dati del problema che sono critici, e non ha molto senso mantenere giorni di dati normali dei pazienti. La maggior parte dei dati coinvolti nell’analisi in tempo reale sono dati a breve termine che non vengono conservati a lungo termine. Un’azienda deve decidere quali dati conservare e cosa scartare una volta eseguite le analisi. E i dati che vengono conservati devono essere protetti in conformità con le politiche aziendali e normative.
Implementazione dell’edge computing
L’edge computing è un’idea semplice che potrebbe sembrare facile sulla carta, ma sviluppare una strategia coesa e implementare una distribuzione solida all’edge può essere un esercizio impegnativo.
Il primo elemento vitale di qualsiasi implementazione tecnologica di successo è la creazione di una strategia aziendale e tecnica significativa. Una tale strategia non riguarda la scelta di venditori o attrezzi. Invece, una strategia edge considera la necessità di edge computing. Comprendere il “perché” richiede una chiara comprensione dei problemi tecnici e aziendali che l’organizzazione sta cercando di risolvere, come il superamento dei vincoli di rete e l’osservazione della sovranità dei dati.

Tali strategie potrebbero iniziare con una discussione su cosa significa edge, dove esiste per il business e come dovrebbe avvantaggiare l’organizzazione. Le strategie Edge dovrebbero anche allinearsi con i piani aziendali esistenti e le roadmap tecnologiche. Ad esempio, se l’azienda cerca di ridurre l’impronta centralizzata del data center, edge e altre tecnologie di calcolo distribuito potrebbero allinearsi bene.
Man mano che il progetto si avvicina all’implementazione, è importante valutare attentamente le opzioni hardware e software. Ci sono molti fornitori nello spazio edge computing, tra cui Adlink Technology, Cisco, Amazon, Dell EMC e HPE. Ogni offerta di prodotti deve essere valutata per costi, prestazioni, caratteristiche, interoperabilità e supporto. Dal punto di vista del software, gli strumenti dovrebbero fornire visibilità e controllo completi sull’ambiente edge remoto.
L’implementazione effettiva di un’iniziativa di edge computing può variare notevolmente in termini di portata e scala, da alcuni dispositivi di calcolo locali in un recinto temprato in cima a un’utilità a una vasta gamma di sensori che alimentano una connessione di rete ad alta larghezza di banda e bassa latenza al cloud pubblico. Non esistono due distribuzioni edge uguali. Sono queste variazioni che rendono la strategia e la pianificazione edge così fondamentali per il successo del progetto edge.
Una distribuzione edge richiede un monitoraggio completo. Ricorda che potrebbe essere difficile-o addirittura impossibile-portare il personale IT al sito edge fisico, quindi le distribuzioni edge dovrebbero essere progettate per fornire resilienza, tolleranza ai guasti e capacità di auto-guarigione. Gli strumenti di monitoraggio devono offrire una chiara panoramica della distribuzione remota, consentire un facile provisioning e configurazione, offrire avvisi e report completi e mantenere la sicurezza dell’installazione e dei suoi dati. Il monitoraggio dell’edge spesso comporta una serie di metriche e KPI, come disponibilità o uptime del sito, prestazioni di rete, capacità e utilizzo dello storage e risorse di elaborazione.
E nessuna implementazione edge sarebbe completa senza un’attenta considerazione della manutenzione edge:
- Sicurezza. Le precauzioni di sicurezza fisiche e logiche sono vitali e dovrebbero coinvolgere strumenti che enfatizzano la gestione delle vulnerabilità e il rilevamento e la prevenzione delle intrusioni. La sicurezza deve estendersi ai sensori e ai dispositivi IoT, poiché ogni dispositivo è un elemento di rete a cui è possibile accedere o hackerare presenting presentando un numero sconcertante di possibili superfici di attacco.
- Connettività. La connettività è un altro problema e devono essere prese disposizioni per l’accesso al controllo e alla segnalazione anche quando la connettività per i dati effettivi non è disponibile. Alcune distribuzioni edge utilizzano una connessione secondaria per la connettività e il controllo del backup.
- Gestione. Le posizioni remote e spesso inospitali delle distribuzioni edge rendono essenziale il provisioning e la gestione remota. I responsabili IT devono essere in grado di vedere cosa sta succedendo all’edge ed essere in grado di controllare la distribuzione quando necessario.
- Manutenzione fisica. I requisiti di manutenzione fisica non possono essere trascurati. I dispositivi IoT hanno spesso una durata limitata con sostituzioni di routine di batterie e dispositivi. Gear fallisce e alla fine richiede manutenzione e sostituzione. La logistica pratica del sito deve essere inclusa con la manutenzione.
Edge computing, IoT e 5G possibilità
Edge computing continua ad evolversi, utilizzando nuove tecnologie e pratiche per migliorare le sue capacità e prestazioni. Forse la tendenza più degna di nota è la disponibilità di edge, e i servizi edge dovrebbero diventare disponibili in tutto il mondo entro il 2028. Dove l’edge computing è spesso specifico della situazione oggi, la tecnologia dovrebbe diventare più onnipresente e spostare il modo in cui Internet viene utilizzato, portando più astrazione e potenziali casi d’uso per la tecnologia edge.
Questo può essere visto nella proliferazione di prodotti di calcolo, storage e appliance di rete specificamente progettati per l’edge computing. Più partnership multivendor consentiranno una migliore interoperabilità dei prodotti e flessibilità all’avanguardia. Un esempio include una partnership tra AWS e Verizon per portare una migliore connettività all’edge.
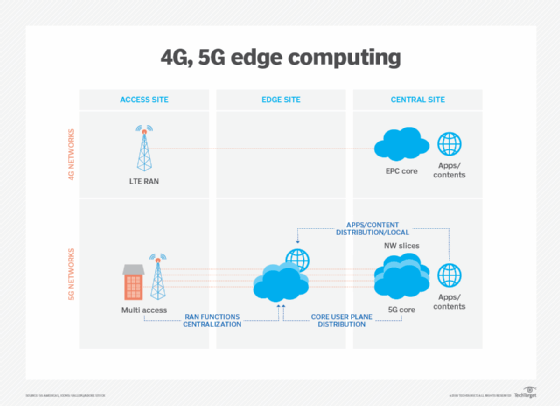
Le tecnologie di comunicazione wireless, come 5G e Wi-Fi 6, influenzeranno anche le implementazioni e l’utilizzo di edge nei prossimi anni, consentendo funzionalità di virtualizzazione e automazione che devono ancora essere esplorate, come una migliore autonomia del veicolo e migrazioni del carico di lavoro verso edge, rendendo le reti wireless più flessibili e convenienti.
L’edge computing ha guadagnato visibilità con l’ascesa dell’IoT e l’improvvisa sovrabbondanza di dati prodotti da tali dispositivi. Ma con le tecnologie IoT ancora in relativa infanzia, l’evoluzione dei dispositivi IoT avrà anche un impatto sul futuro sviluppo dell’edge computing. Un esempio di tali alternative future è lo sviluppo di micro data center modulari (MMDC). L’MMDC è fondamentalmente un data center in una scatola, mettendo un data center completo all’interno di un piccolo sistema mobile che può essere distribuito più vicino ai dati-come in una città o una regione-per ottenere il calcolo molto più vicino ai dati senza mettere il bordo ai dati corretta.