L’Edge computing est une architecture de technologie de l’information distribuée (TI) dans laquelle les données client sont traitées à la périphérie du réseau, aussi près que possible de la source d’origine.
Les données sont la pierre angulaire de l’entreprise moderne, elles fournissent des informations précieuses sur l’entreprise et soutiennent le contrôle en temps réel des processus et des opérations critiques de l’entreprise. Les entreprises d’aujourd’hui sont inondées d’un océan de données, et d’énormes quantités de données peuvent être collectées régulièrement à partir de capteurs et d’appareils IoT fonctionnant en temps réel à partir de sites distants et d’environnements d’exploitation inhospitaliers presque partout dans le monde.
Mais ce flot virtuel de données change également la façon dont les entreprises gèrent l’informatique. Le paradigme informatique traditionnel basé sur un centre de données centralisé et un Internet de tous les jours n’est pas bien adapté au déplacement de rivières sans cesse croissantes de données du monde réel. Les limitations de bande passante, les problèmes de latence et les perturbations imprévisibles du réseau peuvent tous compliquer ces efforts. Les entreprises répondent à ces défis en matière de données grâce à l’utilisation d’une architecture edge computing.
En termes simples, l’informatique de périphérie déplace une partie du stockage et des ressources de calcul hors du centre de données central et plus près de la source des données elle-même. Plutôt que de transmettre des données brutes à un centre de données central pour traitement et analyse, ce travail est plutôt effectué là où les données sont réellement générées – qu’il s’agisse d’un magasin de détail, d’une usine, d’un service public tentaculaire ou d’une ville intelligente. Seul le résultat de ce travail informatique à la périphérie, comme des informations commerciales en temps réel, des prévisions de maintenance des équipements ou d’autres réponses exploitables, est renvoyé au centre de données principal pour examen et autres interactions humaines.
Ainsi, le edge computing est en train de remodeler l’informatique et l’informatique d’entreprise. Examinez en détail ce qu’est l’informatique de périphérie, son fonctionnement, l’influence du cloud, les cas d’utilisation de périphérie, les compromis et les considérations de mise en œuvre.
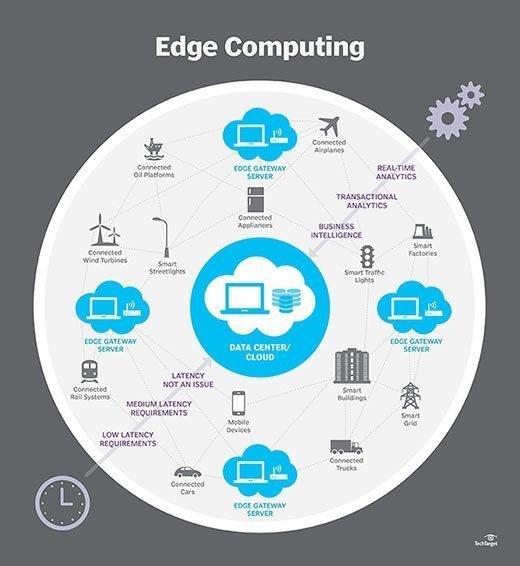
Comment fonctionne l’edge computing ?
L’informatique de périphérie est une question de localisation. Dans l’informatique d’entreprise traditionnelle, les données sont produites sur un point de terminaison client, tel que l’ordinateur d’un utilisateur. Ces données sont déplacées sur un WAN tel qu’Internet, via le réseau local d’entreprise, où les données sont stockées et traitées par une application d’entreprise. Les résultats de ce travail sont ensuite renvoyés au point de terminaison client. Cela reste une approche éprouvée et éprouvée de l’informatique client-serveur pour la plupart des applications métier typiques.
Mais le nombre d’appareils connectés à Internet et le volume de données produites par ces appareils et utilisées par les entreprises augmentent beaucoup trop rapidement pour que les infrastructures de centres de données traditionnels puissent s’adapter. Gartner a prédit que d’ici 2025, 75% des données générées par l’entreprise seront créées en dehors des centres de données centralisés. La perspective de déplacer autant de données dans des situations souvent sensibles au temps ou aux perturbations exerce une pression incroyable sur l’Internet mondial, qui lui-même est souvent sujet à des embouteillages et à des perturbations.
Les architectes informatiques ont donc déplacé leur attention du centre de données central vers la périphérie logique de l’infrastructure – en prenant des ressources de stockage et de calcul du centre de données et en déplaçant ces ressources au point où les données sont générées. Le principe est simple: Si vous ne pouvez pas rapprocher les données du centre de données, rapprochez le centre de données des données. Le concept d’informatique de périphérie n’est pas nouveau, et il est enraciné dans des idées vieilles de plusieurs décennies d’informatique à distance – telles que les bureaux distants et les succursales – où il était plus fiable et efficace de placer les ressources informatiques à l’emplacement souhaité plutôt que de s’appuyer sur un seul emplacement central.

L’Edge computing place le stockage et les serveurs là où se trouvent les données, nécessitant souvent un peu plus qu’un rack partiel pour fonctionner sur le réseau local distant pour collecter et traiter les données localement. Dans de nombreux cas, l’équipement informatique est déployé dans des enceintes blindées ou durcies pour le protéger des températures extrêmes, de l’humidité et d’autres conditions environnementales. Le traitement implique souvent la normalisation et l’analyse du flux de données pour rechercher une intelligence d’affaires, et seuls les résultats de l’analyse sont renvoyés au centre de données principal.
L’idée de business intelligence peut varier considérablement. Certains exemples incluent des environnements de vente au détail où la surveillance vidéo de l’étage de la salle d’exposition peut être combinée avec des données de vente réelles pour déterminer la configuration du produit ou la demande du consommateur la plus souhaitable. D’autres exemples impliquent des analyses prédictives qui peuvent guider la maintenance et la réparation de l’équipement avant que des défauts ou des défaillances réels ne se produisent. D’autres exemples encore sont souvent alignés sur les services publics, tels que le traitement de l’eau ou la production d’électricité, pour garantir le bon fonctionnement des équipements et maintenir la qualité de la production.
Bord vs nuage vs fog computing
L’Edge computing est étroitement associé aux concepts de cloud computing et de fog computing. Bien qu’il y ait un certain chevauchement entre ces concepts, ils ne sont pas la même chose et ne devraient généralement pas être utilisés de manière interchangeable. Il est utile de comparer les concepts et de comprendre leurs différences.
L’une des façons les plus simples de comprendre les différences entre edge, cloud et fog computing consiste à mettre en évidence leur thème commun: Les trois concepts se rapportent à l’informatique distribuée et se concentrent sur le déploiement physique des ressources de calcul et de stockage par rapport aux données produites. La différence est une question de localisation de ces ressources.
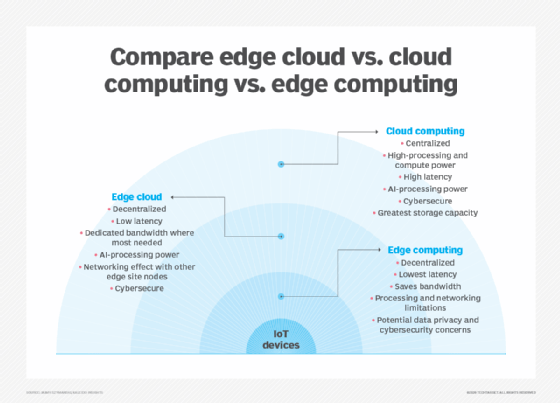
Bord. L’Edge computing est le déploiement de ressources informatiques et de stockage à l’emplacement où les données sont produites. Cela place idéalement le calcul et le stockage au même point que la source de données à la périphérie du réseau. Par exemple, une petite enceinte avec plusieurs serveurs et un certain stockage peut être installée au sommet d’une éolienne pour collecter et traiter les données produites par les capteurs dans la turbine elle-même. Autre exemple, une gare ferroviaire peut placer une quantité modeste de calcul et de stockage dans la gare pour collecter et traiter une myriade de données de capteurs de trafic ferroviaire et ferroviaire. Les résultats d’un tel traitement peuvent ensuite être renvoyés à un autre centre de données pour examen humain, archivage et fusion avec d’autres résultats de données pour une analyse plus large.
Nuage. Le Cloud computing est un déploiement énorme et hautement évolutif de ressources de calcul et de stockage sur l’un des nombreux sites mondiaux distribués (régions). Les fournisseurs de cloud intègrent également un assortiment de services préemballés pour les opérations IoT, faisant du cloud une plate-forme centralisée privilégiée pour les déploiements IoT. Mais même si le cloud computing offre bien plus que suffisamment de ressources et de services pour faire face à des analyses complexes, l’installation cloud régionale la plus proche peut toujours se trouver à des centaines de kilomètres du point de collecte des données, et les connexions reposent sur la même connectivité Internet capricieuse qui prend en charge les centres de données traditionnels. En pratique, le cloud computing est une alternative – ou parfois un complément – aux centres de données traditionnels. Le cloud peut rapprocher l’informatique centralisée d’une source de données, mais pas à la périphérie du réseau.
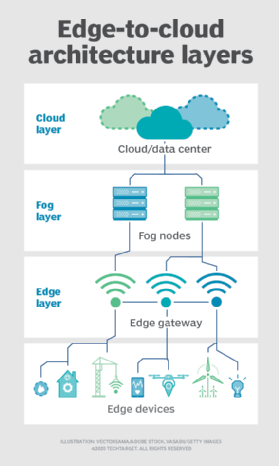
Brouillard. Mais le choix du déploiement du calcul et du stockage ne se limite pas au cloud ou à la périphérie. Un centre de données cloud est peut-être trop éloigné, mais le déploiement en périphérie peut simplement être trop limité en ressources, ou physiquement dispersé ou distribué, pour rendre l’informatique de périphérie stricte pratique. Dans ce cas, la notion de calcul du brouillard peut aider. L’informatique Fog prend généralement du recul et place les ressources de calcul et de stockage « dans » les données, mais pas nécessairement « dans » les données.
Les environnements informatiques de brouillard peuvent produire des quantités déconcertantes de données de capteurs ou IoT générées sur des zones physiques étendues qui sont tout simplement trop grandes pour définir une périphérie. Les exemples incluent les bâtiments intelligents, les villes intelligentes ou même les réseaux publics intelligents. Envisagez une ville intelligente où les données peuvent être utilisées pour suivre, analyser et optimiser le système de transport en commun, les services publics municipaux, les services municipaux et guider la planification urbaine à long terme. Un déploiement périphérique unique n’est tout simplement pas suffisant pour gérer une telle charge, de sorte que fog computing peut exploiter une série de déploiements de nœuds fog dans le cadre de l’environnement pour collecter, traiter et analyser des données.
Remarque: Il est important de répéter que fog computing et edge computing partagent une définition et une architecture presque identiques, et les termes sont parfois utilisés de manière interchangeable, même parmi les experts en technologie.
Pourquoi l’edge computing est-il important ?
Les tâches informatiques exigent des architectures appropriées, et l’architecture qui convient à un type de tâche informatique ne convient pas nécessairement à tous les types de tâches informatiques. L’informatique de périphérie est apparue comme une architecture viable et importante qui prend en charge l’informatique distribuée pour déployer des ressources de calcul et de stockage plus près – idéalement au même emplacement physique que – de la source de données. En général, les modèles d’informatique distribuée ne sont guère nouveaux et les concepts de bureaux distants, de succursales, de colocation de centres de données et de cloud computing ont fait leurs preuves depuis longtemps.
Mais la décentralisation peut être difficile, exigeant des niveaux élevés de surveillance et de contrôle qui sont facilement négligés lorsqu’on s’éloigne d’un modèle informatique centralisé traditionnel. L’Edge computing est devenu pertinent car il offre une solution efficace aux problèmes de réseau émergents associés au déplacement d’énormes volumes de données que les organisations d’aujourd’hui produisent et consomment. Ce n’est pas seulement un problème de montant. C’est aussi une question de temps ; les demandes dépendent du traitement et des réponses qui sont de plus en plus sensibles au temps.
Considérez l’essor des voitures autonomes. Ils dépendront de signaux de contrôle de la circulation intelligents. Les voitures et les contrôles de la circulation devront produire, analyser et échanger des données en temps réel. Multipliez cette exigence par un grand nombre de véhicules autonomes, et l’étendue des problèmes potentiels devient plus claire. Cela exige un réseau rapide et réactif. Edge computing et fog computing computing répondent à trois limitations principales du réseau: bande passante, latence et congestion ou fiabilité.
- Bande passante. La bande passante est la quantité de données qu’un réseau peut transporter au fil du temps, généralement exprimée en bits par seconde. Tous les réseaux ont une bande passante limitée et les limites sont plus sévères pour la communication sans fil. Cela signifie qu’il existe une limite finie à la quantité de données – ou au nombre de périphériques – pouvant communiquer des données sur le réseau. Bien qu’il soit possible d’augmenter la bande passante du réseau pour accueillir plus d’appareils et de données, le coût peut être important, il y a encore des limites finies (plus élevées) et cela ne résout pas d’autres problèmes.
- Latence. La latence est le temps nécessaire pour envoyer des données entre deux points d’un réseau. Bien que la communication se fasse idéalement à la vitesse de la lumière, les grandes distances physiques associées à la congestion ou aux pannes du réseau peuvent retarder le mouvement des données sur le réseau. Cela retarde les processus d’analyse et de prise de décision et réduit la capacité d’un système à réagir en temps réel. Cela a même coûté des vies dans l’exemple du véhicule autonome.
- Congestion. Internet est fondamentalement un « réseau mondial de réseaux ». »Bien qu’il ait évolué pour offrir de bons échanges de données à usage général pour la plupart des tâches informatiques quotidiennes – telles que les échanges de fichiers ou le streaming de base -, le volume de données impliqué avec des dizaines de milliards d’appareils peut submerger Internet, provoquant des niveaux élevés de congestion et forçant des retransmissions de données chronophages. Dans d’autres cas, les pannes de réseau peuvent exacerber la congestion et même couper complètement la communication avec certains utilisateurs d’Internet – rendant l’Internet des objets inutile pendant les pannes.
En déployant des serveurs et un stockage où les données sont générées, l’edge computing peut faire fonctionner de nombreux périphériques sur un réseau local beaucoup plus petit et plus efficace où une large bande passante est utilisée exclusivement par des périphériques locaux générant des données, rendant la latence et la congestion pratiquement inexistantes. Le stockage local collecte et protège les données brutes, tandis que les serveurs locaux peuvent effectuer des analyses de périphérie essentielles – ou du moins prétraiter et réduire les données – pour prendre des décisions en temps réel avant d’envoyer les résultats, ou simplement les données essentielles, au cloud ou au centre de données central.
Exemples et cas d’utilisation du Edge computing
En principe, les techniques de edge computing sont utilisées pour collecter, filtrer, traiter et analyser des données » sur place » au niveau de la périphérie du réseau ou à proximité. C’est un moyen puissant d’utiliser des données qui ne peuvent pas être déplacées d’abord vers un emplacement centralisé – généralement parce que le volume de données rend ces déplacements prohibitifs, peu pratiques sur le plan technologique ou peuvent enfreindre les obligations de conformité, telles que la souveraineté des données. Cette définition a engendré une myriade d’exemples et de cas d’utilisation réels :
- Fabrication. Un fabricant industriel a déployé l’edge computing pour surveiller la fabrication, permettant des analyses en temps réel et un apprentissage automatique à la périphérie pour détecter les erreurs de production et améliorer la qualité de fabrication des produits. L’Edge computing a pris en charge l’ajout de capteurs environnementaux dans toute l’usine de fabrication, fournissant un aperçu de la manière dont chaque composant du produit est assemblé et stocké — et de la durée de conservation des composants. Le fabricant peut désormais prendre des décisions commerciales plus rapides et plus précises concernant les installations de l’usine et les opérations de fabrication.
- Agriculture. Considérez une entreprise qui cultive des cultures à l’intérieur sans lumière du soleil, sol ou pesticides. Le processus réduit les temps de croissance de plus de 60%. L’utilisation de capteurs permet à l’entreprise de suivre l’utilisation de l’eau, la densité des nutriments et de déterminer la récolte optimale. Les données sont collectées et analysées pour trouver les effets des facteurs environnementaux et améliorer continuellement les algorithmes de culture et s’assurer que les cultures sont récoltées en parfait état.
- Optimisation du réseau. L’informatique de périphérie peut aider à optimiser les performances du réseau en mesurant les performances des utilisateurs sur Internet, puis en utilisant des analyses pour déterminer le chemin de réseau le plus fiable et à faible latence pour le trafic de chaque utilisateur. En effet, l’informatique de périphérie est utilisée pour » diriger » le trafic sur le réseau pour des performances de trafic optimales en fonction du temps.
- Sécurité au travail. L’Edge computing peut combiner et analyser les données des caméras sur site, des dispositifs de sécurité des employés et de divers autres capteurs pour aider les entreprises à surveiller les conditions de travail ou à s’assurer que les employés suivent les protocoles de sécurité établis, en particulier lorsque le lieu de travail est éloigné ou exceptionnellement dangereux, comme les chantiers de construction ou les plates-formes pétrolières.
- Amélioration des soins de santé. L’industrie de la santé a considérablement augmenté la quantité de données sur les patients collectées à partir d’appareils, de capteurs et d’autres équipements médicaux. Cet énorme volume de données nécessite l’informatique de pointe pour appliquer l’automatisation et l’apprentissage automatique pour accéder aux données, ignorer les données « normales » et identifier les données problématiques afin que les cliniciens puissent prendre des mesures immédiates pour aider les patients à éviter les incidents de santé en temps réel.
- Transport. Les véhicules autonomes nécessitent et produisent de 5 à 20 To par jour, recueillant des informations sur l’emplacement, la vitesse, l’état du véhicule, l’état des routes, les conditions de circulation et d’autres véhicules. Et les données doivent être agrégées et analysées en temps réel, pendant que le véhicule est en mouvement. Cela nécessite un calcul embarqué important each chaque véhicule autonome devient un « edge ». »En outre, les données peuvent aider les autorités et les entreprises à gérer leurs flottes de véhicules en fonction des conditions réelles sur le terrain.
- Vente au détail. Les entreprises de détail peuvent également produire d’énormes volumes de données à partir de la surveillance, du suivi des stocks, des données de vente et d’autres détails commerciaux en temps réel. L’Edge computing peut aider à analyser ces diverses données et à identifier les opportunités commerciales, telles qu’une enveloppe finale ou une campagne efficace, à prédire les ventes et à optimiser les commandes des fournisseurs, etc. Étant donné que les commerces de détail peuvent varier considérablement dans les environnements locaux, l’informatique de périphérie peut être une solution efficace pour le traitement local dans chaque magasin.
Avantages de l’informatique de périphérie
L’informatique de périphérie répond à des défis d’infrastructure vitaux – tels que les limitations de bande passante, la latence excessive et la congestion du réseau – mais il existe plusieurs avantages supplémentaires potentiels à l’informatique de périphérie qui peuvent rendre l’approche attrayante dans d’autres situations.
Autonomie. L’informatique de périphérie est utile lorsque la connectivité n’est pas fiable ou que la bande passante est restreinte en raison des caractéristiques environnementales du site. Les exemples incluent les plates-formes pétrolières, les navires en mer, les fermes isolées ou d’autres endroits éloignés, comme une forêt tropicale ou un désert. Edge computing effectue le travail de calcul sur site – parfois sur l’appareil edge lui-même -, comme des capteurs de qualité de l’eau sur des purificateurs d’eau dans des villages éloignés, et peut enregistrer des données pour les transmettre à un point central uniquement lorsque la connectivité est disponible. En traitant les données localement, la quantité de données à envoyer peut être considérablement réduite, nécessitant beaucoup moins de bande passante ou de temps de connectivité que ce qui pourrait autrement être nécessaire.
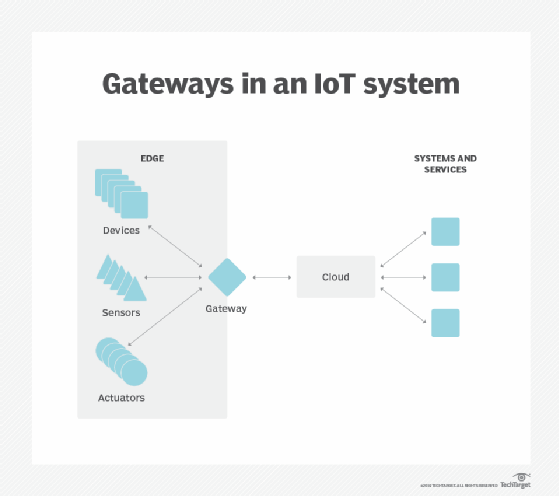
Souveraineté des données. Déplacer d’énormes quantités de données n’est pas seulement un problème technique. Le voyage des données à travers les frontières nationales et régionales peut poser des problèmes supplémentaires pour la sécurité des données, la confidentialité et d’autres questions juridiques. L’informatique de périphérie peut être utilisée pour conserver les données à proximité de leur source et dans les limites des lois en vigueur sur la souveraineté des données, telles que le RGPD de l’Union européenne, qui définit la manière dont les données doivent être stockées, traitées et exposées. Cela peut permettre de traiter des données brutes localement, en masquant ou en sécurisant toute donnée sensible avant d’envoyer quoi que ce soit au cloud ou au centre de données principal, qui peut se trouver dans d’autres juridictions.
Sécurité périphérique. Enfin, l’edge computing offre une opportunité supplémentaire de mettre en œuvre et d’assurer la sécurité des données. Bien que les fournisseurs de cloud disposent de services IoT et se spécialisent dans l’analyse complexe, les entreprises restent préoccupées par la sûreté et la sécurité des données une fois qu’elles quittent la périphérie et retournent dans le cloud ou le centre de données. En implémentant l’informatique en périphérie, toutes les données traversant le réseau vers le cloud ou le centre de données peuvent être sécurisées par cryptage, et le déploiement en périphérie lui-même peut être renforcé contre les pirates et autres activités malveillantes – même lorsque la sécurité sur les appareils IoT reste limitée.
Défis de l’edge computing
Bien que l’edge computing puisse offrir des avantages convaincants dans une multitude de cas d’utilisation, la technologie est loin d’être infaillible. Au-delà des problèmes traditionnels de limitations du réseau, plusieurs considérations clés peuvent affecter l’adoption de l’informatique de périphérie :
- Capacité limitée. Une partie de l’attrait que le cloud computing apporte à edge – ou fog – computing réside dans la variété et l’échelle des ressources et des services. Le déploiement d’une infrastructure à la périphérie peut être efficace, mais la portée et l’objectif du déploiement à la périphérie doivent être clairement définis – même un déploiement informatique de périphérie étendu remplit un objectif spécifique à une échelle prédéterminée en utilisant des ressources limitées et peu de services.
- Connectivité. L’Edge computing surmonte les limitations réseau typiques, mais même le déploiement edge le plus tolérant nécessitera un niveau minimum de connectivité. Il est essentiel de concevoir un déploiement périphérique qui s’adapte à une connectivité médiocre ou erratique et de prendre en compte ce qui se passe à la périphérie lorsque la connectivité est perdue. L’autonomie, l’IA et la planification gracieuse des défaillances à la suite de problèmes de connectivité sont essentielles au succès de l’informatique de périphérie.
- Sécurité. Les appareils IoT sont notoirement peu sûrs, il est donc essentiel de concevoir un déploiement informatique de périphérie qui mettra l’accent sur une gestion appropriée des appareils, telle que l’application de la configuration basée sur des politiques, ainsi que la sécurité des ressources informatiques et de stockage – y compris des facteurs tels que les correctifs logiciels et les mises à jour – avec une attention particulière au cryptage des données au repos et en vol. Les services IoT des principaux fournisseurs de cloud incluent des communications sécurisées, mais ce n’est pas automatique lors de la création d’un site périphérique à partir de zéro.
- Cycles de vie des données. Le problème permanent de la surabondance de données d’aujourd’hui est qu’une grande partie de ces données sont inutiles. Considérez un dispositif de surveillance médicale – ce ne sont que les données problématiques qui sont critiques, et il est peu utile de conserver des jours de données normales sur les patients. La plupart des données impliquées dans l’analyse en temps réel sont des données à court terme qui ne sont pas conservées à long terme. Une entreprise doit décider quelles données conserver et quelles données supprimer une fois les analyses effectuées. Et les données conservées doivent être protégées conformément aux politiques commerciales et réglementaires.
Implémentation du Edge computing
Le Edge computing est une idée simple qui peut sembler facile sur le papier, mais développer une stratégie cohérente et mettre en œuvre un déploiement solide à la périphérie peut être un exercice difficile.
Le premier élément essentiel de tout déploiement technologique réussi est la création d’une stratégie commerciale et technique de pointe significative. Une telle stratégie ne consiste pas à choisir des fournisseurs ou du matériel. Au lieu de cela, une stratégie de périphérie prend en compte la nécessité de l’informatique de périphérie. Comprendre le « pourquoi » exige une compréhension claire des problèmes techniques et commerciaux que l’organisation tente de résoudre, tels que surmonter les contraintes du réseau et observer la souveraineté des données.

De telles stratégies pourraient commencer par une discussion sur ce que signifie le bord, où il existe pour l’entreprise et comment il devrait bénéficier à l’organisation. Les stratégies de périphérie devraient également s’aligner sur les plans d’activités et les feuilles de route technologiques existants. Par exemple, si l’entreprise cherche à réduire l’empreinte de son centre de données centralisé, les technologies edge et autres technologies informatiques distribuées pourraient bien s’aligner.
À mesure que le projet se rapproche de sa mise en œuvre, il est important d’évaluer soigneusement les options matérielles et logicielles. Il existe de nombreux fournisseurs dans l’espace informatique de périphérie, notamment la technologie Adlink, Cisco, Amazon, Dell EMC et HPE. Chaque offre de produits doit être évaluée pour son coût, ses performances, ses fonctionnalités, son interopérabilité et son support. Du point de vue logiciel, les outils doivent fournir une visibilité et un contrôle complets sur l’environnement de périphérie distant.
Le déploiement réel d’une initiative d’informatique de périphérie peut varier considérablement en termes de portée et d’échelle, allant d’un équipement informatique local dans un boîtier durci au sommet d’un utilitaire à une vaste gamme de capteurs alimentant une connexion réseau à bande passante élevée et à faible latence au cloud public. Il n’y a pas deux déploiements périphériques identiques. Ce sont ces variations qui rendent la stratégie et la planification de périphérie si essentielles à la réussite du projet de périphérie.
Un déploiement en périphérie nécessite une surveillance complète. N’oubliez pas qu’il peut être difficile – voire impossible – d’amener le personnel informatique sur le site périphérique physique, les déploiements périphériques doivent donc être conçus de manière à offrir des capacités de résilience, de tolérance aux pannes et d’auto-guérison. Les outils de surveillance doivent offrir une vue d’ensemble claire du déploiement à distance, permettre un provisionnement et une configuration faciles, offrir des alertes et des rapports complets et maintenir la sécurité de l’installation et de ses données. La surveillance de périphérie implique souvent un ensemble de mesures et d’indicateurs clés de performance, tels que la disponibilité ou la disponibilité du site, les performances du réseau, la capacité et l’utilisation du stockage et les ressources de calcul.
Et aucune implémentation edge ne serait complète sans un examen attentif de la maintenance edge :
- Sécurité. Les précautions de sécurité physiques et logiques sont vitales et devraient impliquer des outils qui mettent l’accent sur la gestion des vulnérabilités et la détection et la prévention des intrusions. La sécurité doit s’étendre aux capteurs et aux appareils IoT, car chaque appareil est un élément de réseau accessible ou piraté – présentant un nombre déconcertant de surfaces d’attaque possibles.
- Connectivité. La connectivité est un autre problème, et des dispositions doivent être prises pour l’accès au contrôle et aux rapports même lorsque la connectivité pour les données réelles n’est pas disponible. Certains déploiements périphériques utilisent une connexion secondaire pour la connectivité et le contrôle de sauvegarde.
- Gestion. Les emplacements distants et souvent inhospitaliers des déploiements périphériques rendent le provisionnement et la gestion à distance essentiels. Les responsables informatiques doivent être en mesure de voir ce qui se passe en périphérie et de contrôler le déploiement si nécessaire.
- Entretien physique. Les exigences d’entretien physique ne peuvent être négligées. Les appareils IoT ont souvent une durée de vie limitée avec des remplacements de batterie et d’appareils de routine. L’équipement tombe en panne et nécessite éventuellement un entretien et un remplacement. La logistique pratique du site doit être incluse dans la maintenance.
Possibilités de l’informatique de pointe, de l’IoT et de la 5G
L’informatique de pointe continue d’évoluer, utilisant de nouvelles technologies et pratiques pour améliorer ses capacités et ses performances. La tendance la plus remarquable est peut-être la disponibilité en périphérie, et les services en périphérie devraient être disponibles dans le monde entier d’ici 2028. Là où l’informatique de périphérie est souvent adaptée à la situation actuelle, la technologie devrait devenir plus omniprésente et changer la façon dont Internet est utilisé, apportant plus d’abstraction et de cas d’utilisation potentiels pour la technologie de périphérie.
Cela se voit dans la prolifération de produits de calcul, de stockage et d’appliances réseau spécialement conçus pour le edge computing. Plus de partenariats multi-fournisseurs permettront une meilleure interopérabilité des produits et une meilleure flexibilité à la périphérie. Un exemple inclut un partenariat entre AWS et Verizon pour apporter une meilleure connectivité à la périphérie.
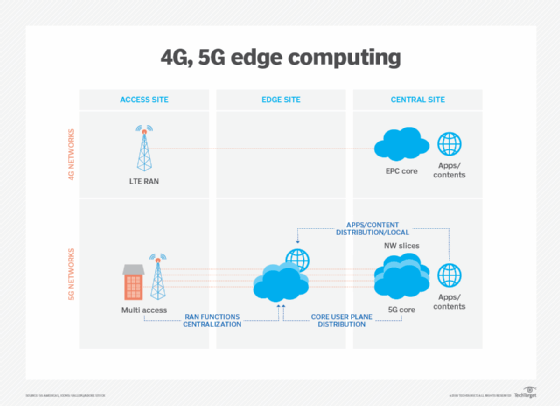
Les technologies de communication sans fil, telles que la 5G et le Wi-Fi 6, affecteront également les déploiements et l’utilisation en périphérie dans les années à venir, permettant des capacités de virtualisation et d’automatisation qui restent à explorer, telles qu’une meilleure autonomie du véhicule et des migrations de charge de travail vers la périphérie, tout en rendant les réseaux sans fil plus flexibles et plus rentables.
L’Edge computing s’est fait remarquer avec l’essor de l’IoT et la surabondance soudaine de données que ces dispositifs produisent. Mais avec les technologies IoT encore relativement balbutiantes, l’évolution des appareils IoT aura également un impact sur le développement futur du edge computing. Un exemple de telles alternatives futures est le développement de micro-centres de données modulaires (MMDC). Le MMDC est essentiellement un centre de données dans une boîte, plaçant un centre de données complet dans un petit système mobile qui peut être déployé plus près des données – comme dans une ville ou une région – pour rapprocher l’informatique des données sans mettre l’avantage sur les données proprement dites.