Edge computing es una arquitectura de tecnología de la información distribuida (TI) en la que los datos del cliente se procesan en la periferia de la red, lo más cerca posible de la fuente de origen.
Los datos son el alma de los negocios modernos, ya que proporcionan información valiosa sobre los negocios y respaldan el control en tiempo real de los procesos y operaciones empresariales críticos. Las empresas de hoy en día están inundadas de un océano de datos, y se pueden recopilar grandes cantidades de datos de forma rutinaria de sensores y dispositivos de IoT que funcionan en tiempo real desde ubicaciones remotas y entornos operativos inhóspitos en casi cualquier parte del mundo.
Pero esta avalancha virtual de datos también está cambiando la forma en que las empresas manejan la informática. El paradigma de computación tradicional basado en un centro de datos centralizado e internet cotidiano no es adecuado para mover ríos de datos del mundo real que crecen sin cesar. Las limitaciones de ancho de banda, los problemas de latencia y las interrupciones impredecibles de la red pueden conspirar para perjudicar dichos esfuerzos. Las empresas están respondiendo a estos desafíos de datos mediante el uso de la arquitectura de edge computing.
En términos simples, la computación perimetral mueve parte de los recursos de almacenamiento y computación fuera del centro de datos central y más cerca de la fuente de los datos en sí. En lugar de transmitir datos sin procesar a un centro de datos central para su procesamiento y análisis, ese trabajo se realiza donde se generan los datos, ya sea en una tienda minorista, una fábrica, una empresa de servicios públicos en expansión o en una ciudad inteligente. Solo el resultado de ese trabajo informático en el perímetro, como información empresarial en tiempo real, predicciones de mantenimiento de equipos u otras respuestas procesables, se envía de vuelta al centro de datos principal para su revisión y otras interacciones humanas.
Por lo tanto, la informática perimetral está remodelando la TI y la informática empresarial. Eche un vistazo exhaustivo a qué es la informática perimetral, cómo funciona, la influencia de la nube, los casos de uso perimetral, las compensaciones y las consideraciones de implementación.
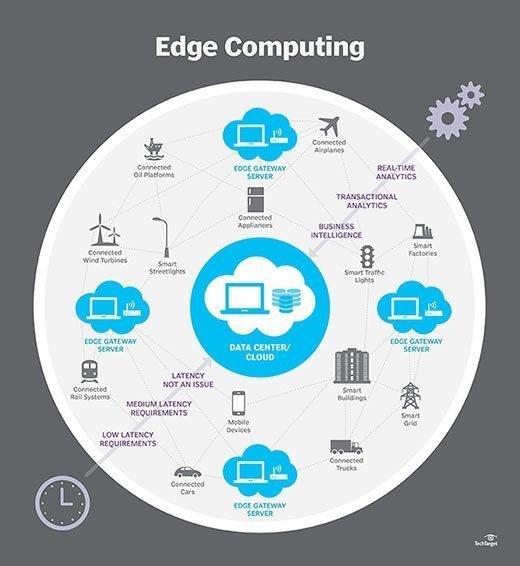
¿Cómo funciona el edge computing?
La computación perimetral es una cuestión de ubicación. En la informática empresarial tradicional, los datos se producen en un punto final de cliente, como el equipo de un usuario. Esos datos se mueven a través de una WAN, como Internet, a través de la LAN corporativa, donde una aplicación empresarial almacena y trabaja los datos. Los resultados de ese trabajo se transmiten de vuelta al punto final del cliente. Este sigue siendo un enfoque probado y probado en el tiempo para la computación cliente-servidor para la mayoría de las aplicaciones empresariales típicas.
Pero el número de dispositivos conectados a Internet, y el volumen de datos que producen esos dispositivos y que utilizan las empresas, está creciendo demasiado rápido para que las infraestructuras de centros de datos tradicionales se adapten. Gartner predijo que para 2025, el 75% de los datos generados por la empresa se crearán fuera de los centros de datos centralizados. La perspectiva de mover tantos datos en situaciones que a menudo pueden ser sensibles al tiempo o a la interrupción pone una tensión increíble en Internet global, que a su vez a menudo está sujeta a la congestión y la interrupción.
Por lo tanto, los arquitectos de TI han cambiado el enfoque del centro de datos central al borde lógico de la infraestructura, tomando el almacenamiento y los recursos informáticos del centro de datos y moviendo esos recursos al punto donde se generan los datos. El principio es sencillo: Si no puede acercar los datos al centro de datos, acerque el centro de datos a los datos. El concepto de computación perimetral no es nuevo, y está arraigado en ideas de computación remota de décadas de antigüedad, como oficinas remotas y sucursales, donde era más confiable y eficiente colocar los recursos informáticos en la ubicación deseada en lugar de depender de una única ubicación central.

Edge computing coloca el almacenamiento y los servidores donde están los datos, a menudo requiriendo poco más que un rack parcial de engranaje para operar en la LAN remota para recopilar y procesar los datos localmente. En muchos casos, el equipo informático se despliega en carcasas blindadas o endurecidas para proteger el equipo de temperaturas extremas, humedad y otras condiciones ambientales. El procesamiento a menudo implica normalizar y analizar el flujo de datos para buscar inteligencia de negocios, y solo los resultados del análisis se envían al centro de datos principal.
La idea de inteligencia de negocios puede variar drásticamente. Algunos ejemplos incluyen entornos minoristas en los que la videovigilancia de la sala de exposición se puede combinar con datos de ventas reales para determinar la configuración del producto o la demanda del consumidor más deseable. Otros ejemplos incluyen análisis predictivos que pueden guiar el mantenimiento y la reparación de los equipos antes de que se produzcan defectos o fallas reales. Otros ejemplos a menudo se alinean con los servicios públicos, como el tratamiento de agua o la generación de electricidad, para garantizar que el equipo funcione correctamente y para mantener la calidad de la producción.
Edge vs nube vs computación de niebla
La computación de borde está estrechamente asociada con los conceptos de computación en la nube y computación de niebla. Aunque hay cierta superposición entre estos conceptos, no son lo mismo, y generalmente no se deben usar indistintamente. Es útil comparar los conceptos y comprender sus diferencias.
Una de las formas más fáciles de entender las diferencias entre edge, cloud y fog computing es resaltar su tema común: Los tres conceptos se relacionan con la computación distribuida y se centran en el despliegue físico de recursos informáticos y de almacenamiento en relación con los datos que se están produciendo. La diferencia radica en la ubicación de esos recursos.
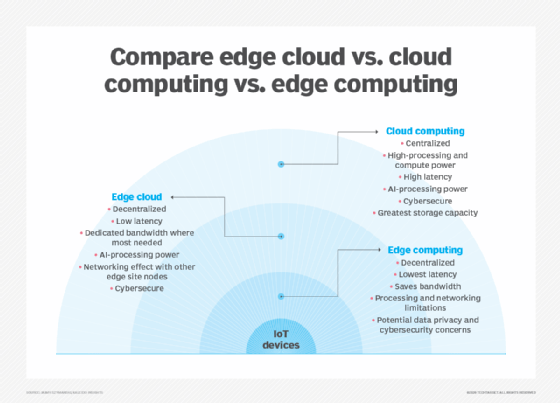
Edge. La informática perimetral es la implementación de recursos informáticos y de almacenamiento en la ubicación donde se producen los datos. Lo ideal es que el procesamiento y el almacenamiento estén en el mismo punto que la fuente de datos en el borde de la red. Por ejemplo, se podría instalar un pequeño recinto con varios servidores y algo de almacenamiento encima de una turbina eólica para recopilar y procesar los datos producidos por los sensores dentro de la propia turbina. Como otro ejemplo, una estación de ferrocarril podría colocar una cantidad modesta de cómputo y almacenamiento dentro de la estación para recopilar y procesar una miríada de datos de sensores de tráfico ferroviario y de vías. Los resultados de cualquier procesamiento de este tipo se pueden enviar de vuelta a otro centro de datos para que los humanos los revisen, archiven y se fusionen con otros resultados de datos para un análisis más amplio.Nube
. La computación en la nube es una implementación enorme y altamente escalable de recursos informáticos y de almacenamiento en una de varias ubicaciones globales distribuidas (regiones). Los proveedores de nube también incorporan una variedad de servicios preempaquetados para operaciones de IoT, lo que convierte a la nube en una plataforma centralizada preferida para implementaciones de IoT. Pero a pesar de que la computación en la nube ofrece recursos y servicios mucho más que suficientes para abordar análisis complejos, la instalación de nube regional más cercana aún puede estar a cientos de millas del punto donde se recopilan los datos, y las conexiones dependen de la misma conectividad a Internet temperamental que admite centros de datos tradicionales. En la práctica, la computación en la nube es una alternativa, o a veces un complemento, a los centros de datos tradicionales. La nube puede hacer que la informática centralizada esté mucho más cerca de una fuente de datos, pero no en el perímetro de la red.
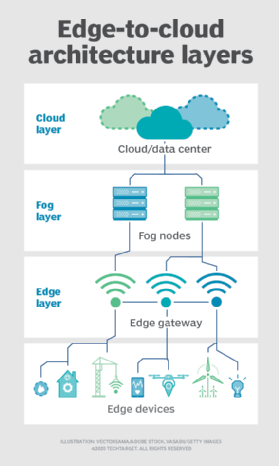
Niebla. Pero la elección de la implementación de computación y almacenamiento no se limita a la nube o al perímetro. Un centro de datos en la nube puede estar demasiado lejos, pero la implementación perimetral puede ser simplemente demasiado limitada en recursos, o estar físicamente dispersa o distribuida, para que la informática perimetral estricta sea práctica. En este caso, la noción de computación de niebla puede ayudar. Por lo general, la computación en niebla da un paso atrás y coloca los recursos informáticos y de almacenamiento «dentro» de los datos, pero no necesariamente «en» los datos.
Los entornos de computación de niebla pueden producir cantidades desconcertantes de datos de sensores o IoT generados en áreas físicas expansivas que son demasiado grandes para definir un borde. Los ejemplos incluyen edificios inteligentes, ciudades inteligentes o incluso redes de servicios públicos inteligentes. Considere una ciudad inteligente donde los datos se puedan usar para rastrear, analizar y optimizar el sistema de transporte público, los servicios públicos municipales, los servicios de la ciudad y guiar la planificación urbana a largo plazo. Una implementación de un solo borde simplemente no es suficiente para manejar tal carga, por lo que fog computing puede operar una serie de implementaciones de nodos de niebla dentro del alcance del entorno para recopilar, procesar y analizar datos.
Nota: Es importante repetir que la computación de niebla y la computación de borde comparten una definición y arquitectura casi idénticas, y los términos a veces se usan indistintamente incluso entre expertos en tecnología.
¿Por qué importa el edge computing?
Las tareas de computación requieren arquitecturas adecuadas, y la arquitectura que se adapta a un tipo de tarea de computación no necesariamente se ajusta a todos los tipos de tareas de computación. La informática perimetral se ha convertido en una arquitectura viable e importante que admite la informática distribuida para implementar recursos informáticos y de almacenamiento más cerca, idealmente en la misma ubicación física que, la fuente de datos. En general, los modelos de computación distribuida no son nuevos, y los conceptos de oficinas remotas, sucursales, colocación en centros de datos y computación en la nube tienen un historial largo y comprobado.
Pero la descentralización puede ser desafiante, exigiendo altos niveles de monitoreo y control que se pasan por alto fácilmente cuando se aleja de un modelo de computación centralizada tradicional. La informática perimetral se ha vuelto relevante porque ofrece una solución eficaz a los problemas de red emergentes asociados con el movimiento de enormes volúmenes de datos que las organizaciones actuales producen y consumen. No es sólo un problema de cantidad. También es cuestión de tiempo; las solicitudes dependen del procesamiento y las respuestas que cada vez son más urgentes.
Considere el aumento de los autos autónomos. Dependerán de señales inteligentes de control de tráfico. Los coches y los controles de tráfico tendrán que producir, analizar e intercambiar datos en tiempo real. Multiplique este requisito por un gran número de vehículos autónomos, y el alcance de los problemas potenciales se vuelve más claro. Esto exige una red rápida y receptiva. La computación Edge — y fog fog aborda tres limitaciones principales de la red: ancho de banda, latencia y congestión o fiabilidad.
- Ancho de banda. El ancho de banda es la cantidad de datos que una red puede llevar a lo largo del tiempo, generalmente expresada en bits por segundo. Todas las redes tienen un ancho de banda limitado, y los límites son más severos para la comunicación inalámbrica. Esto significa que hay un límite finito para la cantidad de datos, o el número de dispositivos, que pueden comunicar datos a través de la red. Aunque es posible aumentar el ancho de banda de la red para acomodar más dispositivos y datos, el costo puede ser significativo, todavía hay límites finitos (más altos) y no resuelve otros problemas.Latencia
- . La latencia es el tiempo necesario para enviar datos entre dos puntos de una red. Aunque la comunicación se lleva a cabo idealmente a la velocidad de la luz, las grandes distancias físicas, junto con la congestión de la red o las interrupciones, pueden retrasar el movimiento de datos a través de la red. Esto retrasa los procesos de análisis y toma de decisiones y reduce la capacidad de un sistema para responder en tiempo real. Incluso costó vidas en el ejemplo del vehículo autónomo.
- Congestión. Internet es básicamente una «red de redes» global.»Aunque ha evolucionado para ofrecer buenos intercambios de datos de propósito general para la mayoría de las tareas informáticas cotidianas, como intercambios de archivos o transmisión básica, el volumen de datos involucrado con decenas de miles de millones de dispositivos puede abrumar a Internet, causando altos niveles de congestión y forzando retransmisiones de datos que consumen mucho tiempo. En otros casos, las interrupciones de la red pueden exacerbar la congestión e incluso cortar la comunicación con algunos usuarios de Internet por completo, lo que hace que el Internet de las cosas sea inútil durante las interrupciones.
Mediante la implementación de servidores y almacenamiento donde se generan los datos, la informática perimetral puede operar muchos dispositivos a través de una LAN mucho más pequeña y eficiente donde los dispositivos locales generadores de datos utilizan un amplio ancho de banda, lo que hace que la latencia y la congestión prácticamente no existan. El almacenamiento local recopila y protege los datos sin procesar, mientras que los servidores locales pueden realizar análisis perimetrales esenciales, o al menos preprocesar y reducir los datos, para tomar decisiones en tiempo real antes de enviar resultados, o simplemente datos esenciales, a la nube o al centro de datos central.
Casos de uso y ejemplos de informática perimetral
En principio, las técnicas de informática perimetral se utilizan para recopilar, filtrar, procesar y analizar datos «in situ» en el perímetro de la red o cerca de él. Es un medio poderoso de usar datos que no se pueden mover primero a una ubicación centralizada, generalmente porque el gran volumen de datos hace que tales movimientos sean prohibitivos, tecnológicamente imprácticos o podrían violar las obligaciones de cumplimiento, como la soberanía de los datos. Esta definición ha generado innumerables ejemplos y casos de uso del mundo real:
- Fabricación. Un fabricante industrial implementó la informática perimetral para supervisar la fabricación, lo que permite el análisis en tiempo real y el aprendizaje automático en el perímetro para encontrar errores de producción y mejorar la calidad de fabricación del producto. La informática perimetral permitió la adición de sensores ambientales en toda la planta de fabricación, proporcionando información sobre cómo se ensambla y almacena cada componente del producto, y cuánto tiempo permanecen los componentes en stock. El fabricante ahora puede tomar decisiones comerciales más rápidas y precisas con respecto a las instalaciones de la fábrica y las operaciones de fabricación.
- Agricultura. Considere un negocio que cultiva en interiores sin luz solar, tierra o pesticidas. El proceso reduce los tiempos de cultivo en más de un 60%. El uso de sensores permite a la empresa rastrear el uso del agua, la densidad de nutrientes y determinar la cosecha óptima. Los datos se recopilan y analizan para encontrar los efectos de los factores ambientales y mejorar continuamente los algoritmos de cultivo y garantizar que los cultivos se cosechen en condiciones óptimas.
- optimización de la Red. La informática perimetral puede ayudar a optimizar el rendimiento de la red midiendo el rendimiento de los usuarios a través de Internet y, a continuación, empleando análisis para determinar la ruta de red más fiable y de baja latencia para el tráfico de cada usuario. En efecto, la informática perimetral se utiliza para «dirigir» el tráfico a través de la red para un rendimiento óptimo del tráfico sensible al tiempo.
- Seguridad en el lugar de trabajo. La informática perimetral puede combinar y analizar datos de cámaras in situ, dispositivos de seguridad para empleados y otros sensores para ayudar a las empresas a supervisar las condiciones del lugar de trabajo o garantizar que los empleados sigan los protocolos de seguridad establecidos, especialmente cuando el lugar de trabajo es remoto o inusualmente peligroso, como sitios de construcción o plataformas petrolíferas.
- Mejora de la atención sanitaria. La industria de la salud ha ampliado drásticamente la cantidad de datos de pacientes recopilados de dispositivos, sensores y otros equipos médicos. Ese enorme volumen de datos requiere la informática perimetral para aplicar la automatización y el aprendizaje automático para acceder a los datos, ignorar los datos «normales» e identificar los datos de problemas para que los médicos puedan tomar medidas inmediatas para ayudar a los pacientes a evitar incidentes de salud en tiempo real.
- Transporte. Los vehículos autónomos requieren y producen entre 5 y 20 TB por día, recopilando información sobre la ubicación, la velocidad, el estado del vehículo, las condiciones de la carretera, las condiciones del tráfico y otros vehículos. Y los datos deben agregarse y analizarse en tiempo real, mientras el vehículo está en movimiento. Esto requiere una importante computación a bordo: cada vehículo autónomo se convierte en una «ventaja».»Además, los datos pueden ayudar a las autoridades y a las empresas a gestionar las flotas de vehículos en función de las condiciones reales sobre el terreno.
- Venta al por menor. Las empresas minoristas también pueden producir enormes volúmenes de datos a partir de la vigilancia, el seguimiento de existencias, los datos de ventas y otros detalles comerciales en tiempo real. La informática perimetral puede ayudar a analizar esta diversidad de datos e identificar oportunidades de negocio, como una cobertura final o campaña eficaz, predecir las ventas y optimizar los pedidos de los proveedores, etc. Dado que los negocios minoristas pueden variar drásticamente en entornos locales, la informática perimetral puede ser una solución eficaz para el procesamiento local en cada tienda.
Beneficios de la informática perimetral
La informática perimetral aborda los desafíos vitales de la infraestructura, como las limitaciones de ancho de banda, el exceso de latencia y la congestión de la red, pero hay varios beneficios adicionales potenciales de la informática perimetral que pueden hacer que el enfoque sea atractivo en otras situaciones.
Autonomía. La computación perimetral es útil cuando la conectividad no es confiable o el ancho de banda está restringido debido a las características ambientales del sitio. Los ejemplos incluyen plataformas petrolíferas, barcos en el mar, granjas remotas u otros lugares remotos, como una selva tropical o un desierto. La informática perimetral realiza el trabajo de cómputo en el sitio, a veces en el propio dispositivo perimetral, como sensores de calidad del agua en purificadores de agua en aldeas remotas, y puede guardar datos para transmitirlos a un punto central solo cuando hay conectividad disponible. Al procesar los datos localmente, la cantidad de datos que se enviarán se puede reducir enormemente, requiriendo mucho menos ancho de banda o tiempo de conectividad de lo que de otro modo sería necesario.
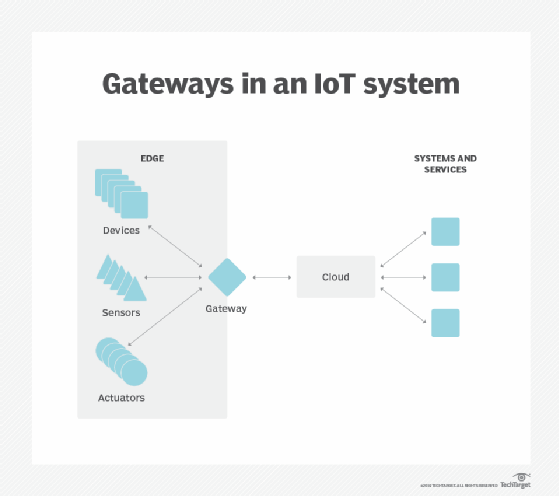
Soberanía de datos. Mover grandes cantidades de datos no es solo un problema técnico. El recorrido de los datos a través de las fronteras nacionales y regionales puede plantear problemas adicionales para la seguridad de los datos, la privacidad y otros asuntos legales. La informática perimetral se puede utilizar para mantener los datos cerca de su fuente y dentro de los límites de las leyes de soberanía de datos vigentes, como el RGPD de la Unión Europea, que define cómo deben almacenarse, procesarse y exponerse los datos. Esto puede permitir que los datos sin procesar se procesen localmente, ocultando o asegurando cualquier dato confidencial antes de enviar nada a la nube o al centro de datos primario, que puede estar en otras jurisdicciones.
Seguridad de borde. Por último, la informática perimetral ofrece una oportunidad adicional para implementar y garantizar la seguridad de los datos. Aunque los proveedores de nube tienen servicios de IoT y se especializan en análisis complejos, las empresas siguen preocupadas por la seguridad de los datos una vez que salen del perímetro y regresan a la nube o al centro de datos. Al implementar la informática en el perímetro, los datos que atraviesan la red de vuelta a la nube o al centro de datos se pueden proteger a través del cifrado, y la implementación en el perímetro en sí se puede reforzar contra hackers y otras actividades maliciosas, incluso cuando la seguridad en los dispositivos IoT sigue siendo limitada.
Desafíos de la informática perimetral
Aunque la informática perimetral tiene el potencial de proporcionar beneficios convincentes en una multitud de casos de uso, la tecnología está lejos de ser infalible. Más allá de los problemas tradicionales de limitaciones de red, hay varias consideraciones clave que pueden afectar la adopción de la computación perimetral:
- Capacidad limitada. Parte del atractivo que aporta la computación en la nube a la computación perimetral, o de niebla, es la variedad y la escala de los recursos y servicios. La implementación de una infraestructura en el perímetro puede ser eficaz, pero el alcance y el propósito de la implementación en el perímetro deben estar claramente definidos, incluso una implementación extensa de informática en el perímetro cumple un propósito específico a una escala predeterminada que utiliza recursos limitados y pocos servicios.
- Conectividad. La informática perimetral supera las limitaciones típicas de la red, pero incluso la implementación perimetral más tolerante requerirá un nivel mínimo de conectividad. Es fundamental diseñar una implementación perimetral que se adapte a una conectividad deficiente o errática y tener en cuenta lo que sucede en el perímetro cuando se pierde la conectividad. La autonomía, la IA y la planificación de fallas elegante a raíz de problemas de conectividad son esenciales para el éxito de la informática perimetral.
- Seguridad. Los dispositivos IoT son notoriamente inseguros, por lo que es vital diseñar una implementación de informática perimetral que haga hincapié en la administración adecuada de los dispositivos, como el cumplimiento de la configuración basada en políticas, así como en la seguridad de los recursos informáticos y de almacenamiento, incluidos factores como parches y actualizaciones de software, con especial atención al cifrado de los datos en reposo y en vuelo. Los servicios de IoT de los principales proveedores de nube incluyen comunicaciones seguras, pero esto no es automático cuando se crea un sitio perimetral desde cero.
- Ciclos de vida de los datos. El problema perenne con el exceso de datos de hoy en día es que gran parte de esos datos son innecesarios. Considere un dispositivo de monitoreo médico: solo los datos de los problemas son críticos, y no tiene mucho sentido mantener días de datos normales del paciente. La mayoría de los datos involucrados en el análisis en tiempo real son datos a corto plazo que no se conservan a largo plazo. Una empresa debe decidir qué datos conservar y qué descartar una vez que se realizan los análisis. Y los datos que se conservan deben protegerse de acuerdo con las políticas comerciales y regulatorias.
Implementación de informática perimetral
La informática perimetral es una idea sencilla que puede parecer fácil en papel, pero desarrollar una estrategia coherente e implementar una implementación sólida en el perímetro puede ser un ejercicio desafiante.
El primer elemento vital de cualquier implementación de tecnología exitosa es la creación de una estrategia empresarial y de vanguardia técnica significativa. Tal estrategia no se trata de elegir vendedores o equipo. En su lugar, una estrategia de perímetro considera la necesidad de la informática de perímetro. Comprender el «por qué» exige una comprensión clara de los problemas técnicos y comerciales que la organización está tratando de resolver, como superar las limitaciones de la red y observar la soberanía de los datos.

Tales estrategias podrían comenzar con una discusión de lo que significa el borde, dónde existe para el negocio y cómo debería beneficiar a la organización. Las estrategias de borde también deben alinearse con los planes de negocios y las hojas de ruta tecnológicas existentes. Por ejemplo, si la empresa busca reducir el tamaño de su centro de datos centralizado, las tecnologías edge y otras tecnologías de computación distribuida podrían alinearse bien.
A medida que el proyecto se acerca a la implementación, es importante evaluar cuidadosamente las opciones de hardware y software. Hay muchos proveedores en el espacio de informática perimetral, incluidos Adlink Technology, Cisco, Amazon, Dell EMC y HPE. Cada oferta de productos debe evaluarse en cuanto a coste, rendimiento, características, interoperabilidad y soporte. Desde el punto de vista del software, las herramientas deben proporcionar visibilidad y control integrales sobre el entorno de borde remoto.
La implementación real de una iniciativa de computación perimetral puede variar drásticamente en alcance y escala, desde un equipo de computación local en un recinto reforzado sobre una utilidad hasta una amplia gama de sensores que alimentan una conexión de red de alto ancho de banda y baja latencia a la nube pública. No hay dos implementaciones perimetrales iguales. Son estas variaciones las que hacen que la estrategia y la planificación perimetrales sean tan críticas para el éxito del proyecto perimetral.
Una implementación perimetral exige una supervisión integral. Recuerde que puede ser difícil, o incluso imposible, llevar al personal de TI al sitio físico perimetral, por lo que las implementaciones perimetrales deben diseñarse para proporcionar resiliencia, tolerancia a fallos y capacidades de autocuración. Las herramientas de supervisión deben ofrecer una visión general clara de la implementación remota, facilitar el aprovisionamiento y la configuración, ofrecer alertas e informes completos y mantener la seguridad de la instalación y sus datos. La supervisión perimetral a menudo implica una serie de métricas e indicadores clave de rendimiento, como la disponibilidad o el tiempo de actividad del sitio, el rendimiento de la red, la capacidad y utilización de almacenamiento y los recursos informáticos.
Y ninguna implementación perimetral estaría completa sin una cuidadosa consideración del mantenimiento perimetral: Seguridad
- . Las precauciones de seguridad física y lógica son vitales y deben incluir herramientas que hagan hincapié en la gestión de vulnerabilidades y la detección y prevención de intrusos. La seguridad debe extenderse a los dispositivos de sensores e IoT, ya que cada dispositivo es un elemento de red al que se puede acceder o hackear, lo que presenta un número desconcertante de posibles superficies de ataque.
- Conectividad. La conectividad es otro problema, y se deben tomar disposiciones para el acceso al control y la presentación de informes, incluso cuando no se disponga de conectividad para los datos reales. Algunas implementaciones perimetrales utilizan una conexión secundaria para la conectividad y el control de copias de seguridad.
- Gestión. Las ubicaciones remotas y a menudo inhóspitas de las implementaciones perimetrales hacen que el aprovisionamiento y la administración remotos sean esenciales. Los administradores de TI deben poder ver lo que está sucediendo en el perímetro y controlar la implementación cuando sea necesario.
- Mantenimiento físico. Los requisitos de mantenimiento físico no se pueden pasar por alto. Los dispositivos IoT a menudo tienen una vida útil limitada con reemplazos rutinarios de baterías y dispositivos. El engranaje falla y, finalmente, requiere mantenimiento y reemplazo. La logística práctica del sitio debe incluirse con el mantenimiento.
Las posibilidades de informática perimetral, IoT y 5G
La informática perimetral sigue evolucionando, utilizando nuevas tecnologías y prácticas para mejorar sus capacidades y rendimiento. Quizás la tendencia más notable es la disponibilidad en el borde, y se espera que los servicios en el borde estén disponibles en todo el mundo para 2028. Donde la informática perimetral es a menudo específica de la situación actual, se espera que la tecnología se vuelva más ubicua y cambie la forma en que se usa Internet, trayendo más abstracción y casos de uso potenciales para la tecnología perimetral.
Esto se puede ver en la proliferación de productos de computación, almacenamiento y dispositivos de red diseñados específicamente para la informática perimetral. Más asociaciones de múltiples proveedores permitirán una mejor interoperabilidad de productos y flexibilidad en el perímetro. Un ejemplo incluye una asociación entre AWS y Verizon para brindar una mejor conectividad al perímetro.
Las tecnologías de comunicación inalámbricas, como 5G y Wi-Fi 6, también afectarán a las implementaciones y la utilización en el perímetro en los próximos años, permitiendo capacidades de virtualización y automatización que aún no se han explorado, como una mejor autonomía del vehículo y migraciones de carga de trabajo al perímetro, al tiempo que hacen que las redes inalámbricas sean más flexibles y rentables.
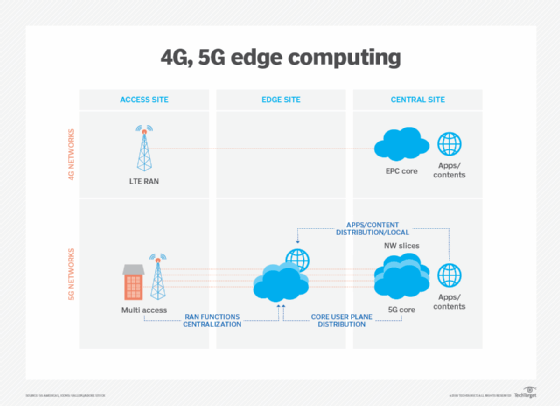
La informática perimetral ganó notoriedad con el auge de IoT y la repentina saturación de datos que producen estos dispositivos. Pero con las tecnologías de IoT aún en una infancia relativa, la evolución de los dispositivos de IoT también tendrá un impacto en el desarrollo futuro de la informática perimetral. Un ejemplo de esas alternativas futuras es el desarrollo de micro centros de datos modulares (MMDC). El MMDC es básicamente un centro de datos en una caja, que coloca un centro de datos completo dentro de un pequeño sistema móvil que se puede implementar más cerca de los datos, como en una ciudad o región, para acercar la computación a los datos sin poner el borde en los datos propiamente dichos.