Edge Computing ist eine verteilte IT-Architektur, bei der Kundendaten an der Peripherie des Netzwerks so nah wie möglich an der Ursprungsquelle verarbeitet werden.
Daten sind das Lebenselixier moderner Unternehmen, sie liefern wertvolle Geschäftseinblicke und unterstützen die Echtzeitkontrolle kritischer Geschäftsprozesse und -abläufe. Die heutigen Unternehmen sind in einem Ozean von Daten überflutet, und riesige Datenmengen können routinemäßig von Sensoren und IoT-Geräten gesammelt werden, die in Echtzeit von entfernten Standorten und unwirtlichen Betriebsumgebungen fast überall auf der Welt arbeiten.
Diese virtuelle Datenflut verändert aber auch die Art und Weise, wie Unternehmen mit Computern umgehen. Das traditionelle Computing-Paradigma, das auf einem zentralisierten Rechenzentrum und dem täglichen Internet basiert, ist nicht gut geeignet, um endlos wachsende Flüsse realer Daten zu bewegen. Bandbreitenbeschränkungen, Latenzprobleme und unvorhersehbare Netzwerkunterbrechungen können solche Bemühungen beeinträchtigen. Unternehmen reagieren auf diese Datenherausforderungen durch den Einsatz von Edge-Computing-Architektur.Im einfachsten Sinne verschiebt Edge Computing einen Teil der Speicher- und Rechenressourcen aus dem zentralen Rechenzentrum und näher an die Quelle der Daten selbst. Anstatt Rohdaten zur Verarbeitung und Analyse an ein zentrales Rechenzentrum zu übertragen, wird diese Arbeit stattdessen dort ausgeführt, wo die Daten tatsächlich generiert werden – sei es in einem Einzelhandelsgeschäft, einer Fabrikhalle, einem weitläufigen Versorgungsunternehmen oder in einer Smart City. Nur das Ergebnis dieser Rechenarbeit am Edge, wie z. B. Geschäftseinblicke in Echtzeit, Vorhersagen zur Gerätewartung oder andere umsetzbare Antworten, wird zur Überprüfung und anderen menschlichen Interaktionen an das Hauptrechenzentrum zurückgesandt.
Edge Computing verändert IT und Business Computing. Werfen Sie einen umfassenden Blick darauf, was Edge Computing ist, wie es funktioniert, den Einfluss der Cloud, Edge-Anwendungsfälle, Kompromisse und Implementierungsüberlegungen.
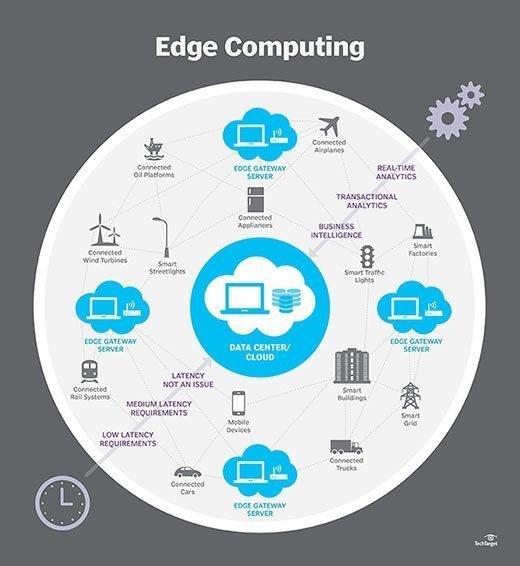
Wie funktioniert Edge Computing?
Edge Computing ist eine Frage des Standorts. Beim herkömmlichen Enterprise Computing werden Daten an einem Client-Endpunkt wie dem Computer eines Benutzers erstellt. Diese Daten werden über ein WAN wie das Internet über das Unternehmens-LAN verschoben, wo die Daten gespeichert und von einer Unternehmensanwendung bearbeitet werden. Die Ergebnisse dieser Arbeit werden dann an den Client-Endpunkt zurückgesandt. Dies bleibt ein bewährter und bewährter Ansatz für Client-Server-Computing für die meisten typischen Geschäftsanwendungen.
Aber die Anzahl der Geräte, die mit dem Internet verbunden sind, und das Datenvolumen, das von diesen Geräten produziert und von Unternehmen verwendet wird, wächst viel zu schnell, als dass traditionelle Rechenzentrumsinfrastrukturen dies aufnehmen könnten. Gartner prognostizierte, dass bis 2025 75% der von Unternehmen generierten Daten außerhalb zentraler Rechenzentren erstellt werden. Die Aussicht, so viele Daten in Situationen zu verschieben, die oft zeit- oder störungsempfindlich sein können, belastet das globale Internet, das selbst oft überlastet und gestört ist, unglaublich.Daher haben IT-Architekten den Fokus vom zentralen Rechenzentrum auf den logischen Rand der Infrastruktur verlagert – sie haben Speicher- und Rechenressourcen aus dem Rechenzentrum genommen und diese Ressourcen an den Punkt verschoben, an dem die Daten generiert werden. Das Prinzip ist einfach: Wenn Sie die Daten nicht näher an das Rechenzentrum heranbringen können, bringen Sie das Rechenzentrum näher an die Daten heran. Das Konzept des Edge Computing ist nicht neu, und es wurzelt in jahrzehntelangen Ideen des Remote Computing – wie Remote-Büros und Zweigstellen -, bei denen es zuverlässiger und effizienter war, Computerressourcen am gewünschten Ort zu platzieren, anstatt sich auf einen einzigen zentralen Ort zu verlassen.

Edge Computing stellt Speicher und Server dort auf, wo sich die Daten befinden, und erfordert häufig wenig mehr als ein Teilgestell, um im Remote-LAN zu arbeiten und die Daten lokal zu sammeln und zu verarbeiten. In vielen Fällen wird die Computerausrüstung in abgeschirmten oder gehärteten Gehäusen eingesetzt, um die Ausrüstung vor extremen Temperaturen, Feuchtigkeit und anderen Umgebungsbedingungen zu schützen. Die Verarbeitung umfasst häufig die Normalisierung und Analyse des Datenstroms, um nach Business Intelligence zu suchen, und nur die Ergebnisse der Analyse werden an das Hauptrechenzentrum zurückgesendet.
Die Vorstellung von Business Intelligence kann sehr unterschiedlich sein. Einige Beispiele umfassen Einzelhandelsumgebungen, in denen die Videoüberwachung des Ausstellungsraums mit tatsächlichen Verkaufsdaten kombiniert werden kann, um die wünschenswerteste Produktkonfiguration oder Verbrauchernachfrage zu bestimmen. Andere Beispiele beinhalten vorausschauende Analysen, die die Wartung und Reparatur von Geräten leiten können, bevor tatsächliche Defekte oder Ausfälle auftreten. Wieder andere Beispiele werden häufig mit Versorgungsunternehmen wie Wasseraufbereitung oder Stromerzeugung abgestimmt, um sicherzustellen, dass die Geräte ordnungsgemäß funktionieren und die Qualität der Leistung erhalten bleibt.
Edge vs. Cloud vs. fog Computing
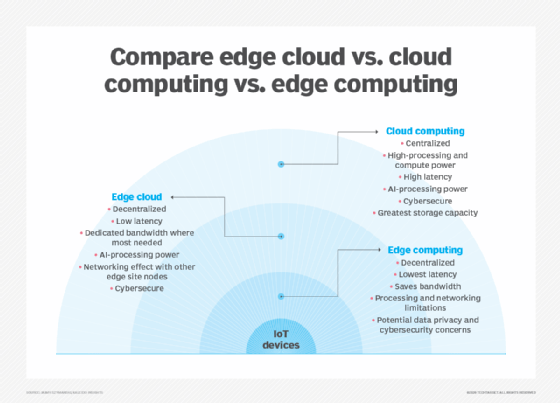
Edge Computing ist eng mit den Konzepten Cloud Computing und Fog Computing verbunden. Obwohl es einige Überschneidungen zwischen diesen Konzepten gibt, sind sie nicht dasselbe und sollten im Allgemeinen nicht austauschbar verwendet werden. Es ist hilfreich, die Konzepte zu vergleichen und ihre Unterschiede zu verstehen.
Eine der einfachsten Möglichkeiten, die Unterschiede zwischen Edge-, Cloud- und Fog-Computing zu verstehen, besteht darin, ihr gemeinsames Thema hervorzuheben: Alle drei Konzepte beziehen sich auf verteiltes Computing und konzentrieren sich auf die physische Bereitstellung von Rechen- und Speicherressourcen in Bezug auf die erzeugten Daten. Der Unterschied liegt darin, wo sich diese Ressourcen befinden.
Rand. Edge Computing ist die Bereitstellung von Rechen- und Speicherressourcen an dem Ort, an dem Daten erzeugt werden. Dies stellt im Idealfall Rechen- und Speicher an der gleichen Stelle wie die Datenquelle am Netzwerkrand. Zum Beispiel könnte ein kleines Gehäuse mit mehreren Servern und etwas Speicher auf einer Windkraftanlage installiert werden, um Daten zu sammeln und zu verarbeiten, die von Sensoren in der Turbine selbst erzeugt werden. Als ein weiteres Beispiel könnte ein Bahnhof eine bescheidene Menge an Rechen- und Speicher innerhalb des Bahnhofs platzieren, um unzählige Gleis- und Schienenverkehrssensordaten zu sammeln und zu verarbeiten. Die Ergebnisse einer solchen Verarbeitung können dann zur Überprüfung, Archivierung und Zusammenführung mit anderen Datenergebnissen für umfassendere Analysen an ein anderes Rechenzentrum gesendet werden.
Wolke. Cloud Computing ist eine riesige, hochskalierbare Bereitstellung von Rechen- und Speicherressourcen an einem von mehreren verteilten globalen Standorten (Regionen). Cloud-Anbieter integrieren auch eine Reihe vorgefertigter Services für IoT-Vorgänge, wodurch die Cloud zu einer bevorzugten zentralen Plattform für IoT-Bereitstellungen wird. Aber obwohl Cloud Computing weit mehr als genug Ressourcen und Dienste bietet, um komplexe Analysen zu bewältigen, kann die nächstgelegene regionale Cloud-Einrichtung immer noch Hunderte von Kilometern von dem Punkt entfernt sein, an dem Daten gesammelt werden, und Verbindungen basieren auf derselben temperamentvollen Internetverbindung, die herkömmliche Rechenzentren unterstützt. In der Praxis ist Cloud Computing eine Alternative – oder manchmal eine Ergänzung – zu herkömmlichen Rechenzentren. Die Cloud kann das zentralisierte Computing viel näher an eine Datenquelle heranführen, jedoch nicht am Netzwerkrand.
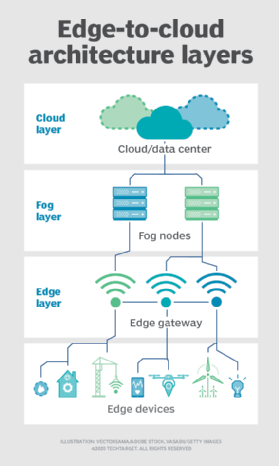
Nebel. Die Wahl der Rechen- und Speicherbereitstellung ist jedoch nicht auf die Cloud oder den Edge beschränkt. Ein Cloud-Rechenzentrum ist möglicherweise zu weit entfernt, aber die Edge-Bereitstellung ist möglicherweise einfach zu ressourcenlimitiert oder physisch verstreut oder verteilt, um striktes Edge-Computing praktikabel zu machen. In diesem Fall kann der Begriff Fog Computing helfen. Fog Computing macht in der Regel einen Schritt zurück und stellt Rechen- und Speicherressourcen „innerhalb“ der Daten bereit, aber nicht unbedingt „bei“ den Daten.Fog-Computing-Umgebungen können verwirrende Mengen an Sensor- oder IoT-Daten erzeugen, die in weitläufigen physischen Bereichen generiert werden, die einfach zu groß sind, um einen Edge zu definieren. Beispiele hierfür sind intelligente Gebäude, intelligente Städte oder sogar intelligente Stromnetze. Stellen Sie sich eine intelligente Stadt vor, in der Daten verwendet werden können, um das öffentliche Verkehrssystem, die Stadtwerke, die städtischen Dienstleistungen und die langfristige Stadtplanung zu verfolgen, zu analysieren und zu optimieren. Eine einzelne Edge-Bereitstellung reicht einfach nicht aus, um eine solche Last zu bewältigen, sodass Fog Computing eine Reihe von Fog Node-Bereitstellungen im Rahmen der Umgebung ausführen kann, um Daten zu sammeln, zu verarbeiten und zu analysieren.Hinweis: Es ist wichtig zu wiederholen, dass Fog Computing und Edge Computing eine fast identische Definition und Architektur haben und die Begriffe manchmal sogar von Technologieexperten synonym verwendet werden.
Warum ist Edge Computing wichtig?
Rechenaufgaben erfordern geeignete Architekturen, und die Architektur, die zu einer Art von Rechenaufgabe passt, passt nicht unbedingt zu allen Arten von Rechenaufgaben. Edge Computing hat sich zu einer praktikablen und wichtigen Architektur entwickelt, die verteiltes Computing unterstützt, um Rechen- und Speicherressourcen näher an der Datenquelle bereitzustellen – idealerweise am selben physischen Ort wie die Datenquelle. Im Allgemeinen sind verteilte Rechenmodelle kaum neu, und die Konzepte von Remote-Büros, Zweigstellen, Colocation von Rechenzentren und Cloud Computing haben eine lange und bewährte Erfolgsbilanz.Dezentralisierung kann jedoch eine Herausforderung sein und ein hohes Maß an Überwachung und Kontrolle erfordern, das bei der Abkehr von einem traditionellen zentralisierten Rechenmodell leicht übersehen wird. Edge Computing ist relevant geworden, weil es eine effektive Lösung für aufkommende Netzwerkprobleme bietet, die mit dem Verschieben enormer Datenmengen verbunden sind, die die heutigen Organisationen produzieren und konsumieren. Es ist nicht nur ein Problem der Menge. Es ist auch eine Frage der Zeit; Anwendungen hängen von Verarbeitungen und Antworten ab, die zunehmend zeitkritisch sind.
Betrachten Sie den Aufstieg selbstfahrender Autos. Sie werden auf intelligente Verkehrssteuersignale angewiesen sein. Autos und Verkehrskontrollen müssen Daten in Echtzeit produzieren, analysieren und austauschen. Multiplizieren Sie diese Anforderung mit einer großen Anzahl autonomer Fahrzeuge, und der Umfang der potenziellen Probleme wird klarer. Dies erfordert ein schnelles und reaktionsschnelles Netzwerk. Edge- und Fog-Computing adressieren drei Hauptnetzwerkbeschränkungen: bandbreite, Latenz und Überlastung oder Zuverlässigkeit.
- Bandbreite. Bandbreite ist die Datenmenge, die ein Netzwerk im Laufe der Zeit übertragen kann, normalerweise ausgedrückt in Bits pro Sekunde. Alle Netzwerke haben eine begrenzte Bandbreite, und die Grenzen für die drahtlose Kommunikation sind strenger. Dies bedeutet, dass es eine endliche Grenze für die Datenmenge – oder die Anzahl der Geräte – gibt, die Daten über das Netzwerk kommunizieren können. Obwohl es möglich ist, die Netzwerkbandbreite zu erhöhen, um mehr Geräte und Daten unterzubringen, können die Kosten erheblich sein, es gibt immer noch (höhere) endliche Grenzen und es löst keine anderen Probleme.
- Latenz. Latenz ist die Zeit, die benötigt wird, um Daten zwischen zwei Punkten in einem Netzwerk zu senden. Obwohl die Kommunikation idealerweise mit Lichtgeschwindigkeit erfolgt, können große physische Entfernungen in Verbindung mit Netzwerküberlastung oder -ausfällen die Datenbewegung im Netzwerk verzögern. Dies verzögert Analyse- und Entscheidungsprozesse und verringert die Fähigkeit eines Systems, in Echtzeit zu reagieren. Im Beispiel autonomer Fahrzeuge kostete es sogar Leben.
- Überlastung. Das Internet ist im Grunde ein globales „Netzwerk von Netzwerken.“ Obwohl es sich weiterentwickelt hat, um einen guten Allzweck-Datenaustausch für die meisten alltäglichen Computeraufgaben – wie Dateiaustausch oder grundlegendes Streaming – anzubieten, kann das Datenvolumen, das mit zig Milliarden von Geräten verbunden ist, das Internet überfordern, was zu einer hohen Überlastung führt und zeitaufwändige Datenübertragungen erzwingt. In anderen Fällen können Netzwerkausfälle die Überlastung verschlimmern und sogar die Kommunikation mit einigen Internetnutzern vollständig unterbrechen – wodurch das Internet der Dinge bei Ausfällen unbrauchbar wird.
Durch die Bereitstellung von Servern und Speicher, auf denen die Daten generiert werden, kann Edge Computing viele Geräte über ein viel kleineres und effizienteres LAN betreiben, in dem reichlich Bandbreite ausschließlich von lokalen datengenerierenden Geräten genutzt wird Latenz und Überlastung praktisch nicht vorhanden. Lokaler Speicher sammelt und schützt die Rohdaten, während lokale Server Essential Edge-Analysen durchführen oder die Daten zumindest vorverarbeiten und reduzieren können, um Entscheidungen in Echtzeit zu treffen, bevor Ergebnisse oder nur wichtige Daten an die Cloud oder das zentrale Rechenzentrum gesendet werden.
Edge Computing Anwendungsfälle und Beispiele
Grundsätzlich werden Edge-Computing-Techniken verwendet, um Daten „vor Ort“ am oder nahe dem Netzwerkrand zu sammeln, zu filtern, zu verarbeiten und zu analysieren. Es ist ein leistungsfähiges Mittel, um Daten zu verwenden, die nicht zuerst an einen zentralen Ort verschoben werden können – in der Regel, weil das schiere Datenvolumen solche Bewegungen unerschwinglich macht, technologisch unpraktisch ist oder anderweitig gegen Compliance-Verpflichtungen wie Datensouveränität verstößt. Diese Definition hat unzählige Beispiele und Anwendungsfälle aus der Praxis hervorgebracht:
- Fertigung. Ein industrieller Hersteller setzte Edge Computing zur Überwachung der Fertigung ein und ermöglichte Echtzeitanalysen und maschinelles Lernen am Rand, um Produktionsfehler zu finden und die Produktherstellungsqualität zu verbessern. Edge Computing unterstützte die Hinzufügung von Umgebungssensoren in der gesamten Produktionsanlage und gab Aufschluss darüber, wie jede Produktkomponente zusammengebaut und gelagert wird – und wie lange die Komponenten auf Lager bleiben. Der Hersteller kann jetzt schnellere und genauere Geschäftsentscheidungen in Bezug auf die Fabrikanlage und den Fertigungsbetrieb treffen.
- Landwirtschaft. Betrachten Sie ein Unternehmen, das Pflanzen in Innenräumen ohne Sonnenlicht, Erde oder Pestizide anbaut. Der Prozess reduziert die Wachstumszeiten um mehr als 60%. Mithilfe von Sensoren kann das Unternehmen den Wasserverbrauch und die Nährstoffdichte verfolgen und die optimale Ernte bestimmen. Die Daten werden gesammelt und analysiert, um die Auswirkungen von Umweltfaktoren zu ermitteln, die Algorithmen für den Anbau von Kulturpflanzen kontinuierlich zu verbessern und sicherzustellen, dass die Kulturpflanzen in einem Spitzenzustand geerntet werden.
- Netzwerkoptimierung. Edge Computing kann zur Optimierung der Netzwerkleistung beitragen, indem die Leistung für Benutzer im gesamten Internet gemessen und anschließend mithilfe von Analysen der zuverlässigste Netzwerkpfad mit niedriger Latenz für den Datenverkehr jedes Benutzers ermittelt wird. Tatsächlich wird Edge Computing verwendet, um den Datenverkehr über das Netzwerk zu „steuern“, um eine optimale zeitkritische Datenverkehrsleistung zu erzielen.
- Sicherheit am Arbeitsplatz. Edge Computing kann Daten von Vor-Ort-Kameras, Mitarbeitersicherheitsgeräten und verschiedenen anderen Sensoren kombinieren und analysieren, um Unternehmen dabei zu helfen, die Bedingungen am Arbeitsplatz zu überwachen oder sicherzustellen, dass die Mitarbeiter die festgelegten Sicherheitsprotokolle einhalten – insbesondere wenn der Arbeitsplatz abgelegen oder ungewöhnlich gefährlich ist, z. B. auf Baustellen oder Ölplattformen.
- Verbesserte Gesundheitsversorgung. Die Gesundheitsbranche hat die Menge an Patientendaten, die von Geräten, Sensoren und anderen medizinischen Geräten erfasst werden, drastisch erhöht. Dieses enorme Datenvolumen erfordert Edge Computing, um Automatisierung und maschinelles Lernen anzuwenden, um auf die Daten zuzugreifen, „normale“ Daten zu ignorieren und Problemdaten zu identifizieren, damit Kliniker sofort Maßnahmen ergreifen können, um Patienten zu helfen, Gesundheitsvorfälle in Echtzeit zu vermeiden.
- Verkehr. Autonome Fahrzeuge benötigen und produzieren zwischen 5 TB und 20 TB pro Tag und sammeln Informationen über Standort, Geschwindigkeit, Fahrzeugzustand, Straßenzustand, Verkehrsbedingungen und andere Fahrzeuge. Und die Daten müssen in Echtzeit aggregiert und analysiert werden, während das Fahrzeug in Bewegung ist. Dies erfordert erhebliche Onboard-Computing – jedes autonome Fahrzeug wird zu einem „Edge“.“ Darüber hinaus können die Daten Behörden und Unternehmen dabei helfen, Fahrzeugflotten basierend auf den tatsächlichen Bedingungen vor Ort zu verwalten.
- Einzelhandel. Einzelhandelsunternehmen können auch enorme Datenmengen aus Überwachung, Bestandsverfolgung, Verkaufsdaten und anderen Geschäftsdetails in Echtzeit erzeugen. Edge Computing kann dabei helfen, diese vielfältigen Daten zu analysieren und Geschäftsmöglichkeiten wie eine effektive Endkappe oder Kampagne zu identifizieren, Verkäufe vorherzusagen und die Bestellung von Lieferanten zu optimieren usw. Da Einzelhandelsunternehmen in lokalen Umgebungen stark variieren können, kann Edge Computing eine effektive Lösung für die lokale Verarbeitung in jedem Geschäft sein.
Vorteile von Edge Computing
Edge Computing adressiert wichtige Infrastrukturherausforderungen – wie Bandbreitenbeschränkungen, übermäßige Latenz und Netzwerküberlastung -, aber es gibt mehrere potenzielle zusätzliche Vorteile von Edge Computing, die den Ansatz in anderen Situationen attraktiv machen können.
Autonomie. Edge Computing ist nützlich, wenn die Konnektivität unzuverlässig ist oder die Bandbreite aufgrund der Umgebungsmerkmale des Standorts eingeschränkt ist. Beispiele sind Bohrinseln, Schiffe auf See, abgelegene Farmen oder andere abgelegene Orte wie Regenwald oder Wüste. Edge Computing erledigt die Rechenarbeit vor Ort – manchmal auf dem Edge-Gerät selbst – wie z. B. Wasserqualitätssensoren an Wasserreinigern in abgelegenen Dörfern, und kann Daten speichern, um sie nur dann an einen zentralen Punkt zu übertragen, wenn eine Konnektivität verfügbar ist. Durch die lokale Verarbeitung von Daten kann die zu sendende Datenmenge erheblich reduziert werden, was weitaus weniger Bandbreite oder Verbindungszeit erfordert, als sonst erforderlich wäre.
Datenhoheit. Das Verschieben großer Datenmengen ist nicht nur ein technisches Problem. Die Reise von Daten über nationale und regionale Grenzen hinweg kann zusätzliche Probleme für die Datensicherheit, den Datenschutz und andere rechtliche Fragen mit sich bringen. Edge Computing kann verwendet werden, um Daten nahe an ihrer Quelle und im Rahmen der geltenden Gesetze zur Datenhoheit wie der DSGVO der Europäischen Union zu halten, die definiert, wie Daten gespeichert, verarbeitet und offengelegt werden sollen. Auf diese Weise können Rohdaten lokal verarbeitet werden, wodurch vertrauliche Daten verdeckt oder gesichert werden, bevor sie an die Cloud oder das primäre Rechenzentrum gesendet werden, das sich in anderen Ländern befinden kann.
Edge-Sicherheit. Schließlich bietet Edge Computing eine zusätzliche Möglichkeit, Datensicherheit zu implementieren und zu gewährleisten. Obwohl Cloud-Anbieter über IoT-Dienste verfügen und sich auf komplexe Analysen spezialisiert haben, sind Unternehmen nach wie vor besorgt über die Sicherheit von Daten, sobald diese den Edge verlassen und in die Cloud oder das Rechenzentrum zurückkehren. Durch die Implementierung von Computing am Edge können alle Daten, die das Netzwerk zurück in die Cloud oder ins Rechenzentrum übertragen, durch Verschlüsselung gesichert werden, und die Edge-Bereitstellung selbst kann gegen Hacker und andere böswillige Aktivitäten geschützt werden – selbst wenn die Sicherheit auf IoT-Geräten begrenzt bleibt.
Herausforderungen des Edge Computing
Obwohl Edge Computing das Potenzial hat, in einer Vielzahl von Anwendungsfällen überzeugende Vorteile zu bieten, ist die Technologie alles andere als narrensicher. Abgesehen von den traditionellen Problemen der Netzwerkbeschränkungen gibt es mehrere wichtige Überlegungen, die die Einführung von Edge Computing beeinflussen können:
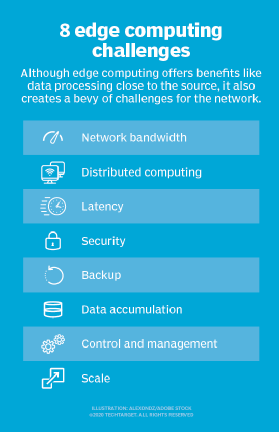
- Eingeschränkte Fähigkeit. Ein Teil des Reizes, den Cloud Computing für Edge – oder Fog-Computing mit sich bringt, ist die Vielfalt und der Umfang der Ressourcen und Dienste. Die Bereitstellung einer Infrastruktur am Edge kann effektiv sein, aber Umfang und Zweck der Edge-Bereitstellung müssen klar definiert sein – selbst eine umfangreiche Edge-Computing-Bereitstellung dient einem bestimmten Zweck in einem vorher festgelegten Maßstab mit begrenzten Ressourcen und wenigen Diensten.
- Konnektivität. Edge Computing überwindet typische Netzwerkbeschränkungen, aber selbst die fehlerverzeihendste Edge-Bereitstellung erfordert ein Mindestmaß an Konnektivität. Es ist wichtig, eine Edge-Bereitstellung zu entwerfen, die eine schlechte oder unregelmäßige Konnektivität ermöglicht, und zu berücksichtigen, was am Edge passiert, wenn die Konnektivität verloren geht. Autonomie, KI und Graceful Failure Planning im Zuge von Konnektivitätsproblemen sind für erfolgreiches Edge Computing unerlässlich.
- Sicherheit. IoT-Geräte sind bekanntermaßen unsicher, daher ist es wichtig, eine Edge-Computing-Bereitstellung zu entwickeln, die ein ordnungsgemäßes Gerätemanagement, wie z. B. richtliniengesteuerte Konfigurationsdurchsetzung, sowie die Sicherheit der Rechen- und Speicherressourcen – einschließlich Faktoren wie Software-Patches und -updates – mit besonderem Augenmerk auf die Verschlüsselung der Daten im Ruhezustand und im Flug betont. IoT-Dienste von großen Cloud-Anbietern umfassen sichere Kommunikation, dies ist jedoch nicht automatisch der Fall, wenn eine Edge-Site von Grund auf neu erstellt wird.
- Datenlebenszyklen. Das ewige Problem mit der heutigen Datenschwemme ist, dass so viele dieser Daten unnötig sind. Betrachten Sie ein medizinisches Überwachungsgerät – es sind nur die Problemdaten, die kritisch sind, und es macht wenig Sinn, Tage normaler Patientendaten aufzubewahren. Bei den meisten Daten, die in Echtzeitanalysen enthalten sind, handelt es sich um kurzfristige Daten, die nicht langfristig gespeichert werden. Ein Unternehmen muss entscheiden, welche Daten aufbewahrt und welche verworfen werden sollen, sobald Analysen durchgeführt wurden. Und die Daten, die aufbewahrt werden, müssen in Übereinstimmung mit den Geschäfts- und Regulierungsrichtlinien geschützt werden.
Edge-Computing-Implementierung
Edge-Computing ist eine einfache Idee, die auf dem Papier vielleicht einfach aussieht, aber die Entwicklung einer kohärenten Strategie und die Implementierung einer soliden Bereitstellung am Edge können eine Herausforderung sein.
Das erste wichtige Element eines erfolgreichen Technologieeinsatzes ist die Erstellung einer sinnvollen geschäftlichen und technischen Edge-Strategie. Bei einer solchen Strategie geht es nicht darum, Anbieter oder Ausrüstung auszuwählen. Stattdessen berücksichtigt eine Edge-Strategie die Notwendigkeit von Edge Computing. Um das „Warum“ zu verstehen, ist ein klares Verständnis der technischen und geschäftlichen Probleme erforderlich, die das Unternehmen zu lösen versucht, z. B. die Überwindung von Netzwerkbeschränkungen und die Einhaltung der Datensouveränität.

Solche Strategien könnten mit einer Diskussion darüber beginnen, was der Edge bedeutet, wo er für das Unternehmen existiert und wie er der Organisation zugute kommen sollte. Edge-Strategien sollten auch mit bestehenden Geschäftsplänen und Technologie-Roadmaps übereinstimmen. Wenn das Unternehmen beispielsweise seine zentralisierte Rechenzentrumsfläche reduzieren möchte, können Edge- und andere verteilte Computertechnologien gut aufeinander abgestimmt sein.
Da sich das Projekt der Implementierung nähert, ist es wichtig, die Hardware- und Softwareoptionen sorgfältig zu bewerten. Es gibt viele Anbieter im Edge-Computing-Bereich, darunter Adlink Technology, Cisco, Amazon, Dell EMC und HPE. Jedes Produktangebot muss hinsichtlich Kosten, Leistung, Funktionen, Interoperabilität und Support bewertet werden. Aus Software-Sicht sollten Tools umfassende Transparenz und Kontrolle über die Remote-Edge-Umgebung bieten.Die tatsächliche Bereitstellung einer Edge-Computing-Initiative kann in Umfang und Umfang dramatisch variieren und reicht von einigen lokalen Computergeräten in einem kampferprobten Gehäuse auf einem Versorgungsunternehmen bis hin zu einer Vielzahl von Sensoren, die eine Netzwerkverbindung mit hoher Bandbreite und niedriger Latenzzeit mit der Public Cloud versorgen. Keine zwei Edge-Bereitstellungen sind gleich. Es sind diese Variationen, die die Edge-Strategie und -Planung für den Erfolg von Edge-Projekten so entscheidend machen.
Eine Edge-Bereitstellung erfordert eine umfassende Überwachung. Denken Sie daran, dass es schwierig oder sogar unmöglich sein kann, IT-Mitarbeiter an den physischen Edge-Standort zu bringen, daher sollten Edge-Bereitstellungen so konzipiert sein, dass sie Ausfallsicherheit, Fehlertoleranz und Selbstheilungsfunktionen bieten. Überwachungstools müssen einen klaren Überblick über die Remote-Bereitstellung bieten, eine einfache Bereitstellung und Konfiguration ermöglichen, umfassende Warnmeldungen und Berichte bieten und die Sicherheit der Installation und ihrer Daten gewährleisten. Die Edge-Überwachung umfasst häufig eine Reihe von Metriken und KPIs, z. B. Standortverfügbarkeit oder -verfügbarkeit, Netzwerkleistung, Speicherkapazität und -auslastung sowie Rechenressourcen.
Und keine Edge-Implementierung wäre ohne eine sorgfältige Berücksichtigung der Edge-Wartung vollständig:
- Sicherheit. Physische und logische Sicherheitsvorkehrungen sind von entscheidender Bedeutung und sollten Tools umfassen, die das Schwachstellenmanagement sowie die Erkennung und Verhinderung von Eindringlingen in den Vordergrund stellen. Die Sicherheit muss sich auf Sensor- und IoT-Geräte erstrecken, da jedes Gerät ein Netzwerkelement ist, auf das zugegriffen oder gehackt werden kann – was eine verwirrende Anzahl möglicher Angriffsflächen darstellt.
- Konnektivität. Konnektivität ist ein weiteres Problem, und es müssen Vorkehrungen für den Zugriff auf Kontrolle und Berichterstattung getroffen werden, auch wenn die Konnektivität für die tatsächlichen Daten nicht verfügbar ist. Einige Edge-Bereitstellungen verwenden eine sekundäre Verbindung für die Backup-Konnektivität und -Steuerung.
- Verwaltung. Die entfernten und oft unwirtlichen Standorte von Edge-Bereitstellungen machen die Remote-Bereitstellung und -Verwaltung unerlässlich. IT-Manager müssen in der Lage sein, zu sehen, was am Edge passiert, und die Bereitstellung bei Bedarf steuern zu können.
- Physische Wartung. Physische Wartungsanforderungen können nicht übersehen werden. IoT-Geräte haben oft eine begrenzte Lebensdauer mit routinemäßigem Batterie- und Geräteaustausch. Getriebe versagt und erfordert schließlich Wartung und Austausch. Die praktische Baustellenlogistik muss in die Instandhaltung einbezogen werden.
Möglichkeiten von Edge Computing, IoT und 5G
Edge Computing entwickelt sich ständig weiter und nutzt neue Technologien und Praktiken, um seine Fähigkeiten und Leistung zu verbessern. Der vielleicht bemerkenswerteste Trend ist die Edge-Verfügbarkeit, und Edge-Dienste werden voraussichtlich bis 2028 weltweit verfügbar sein. Wo Edge Computing heute oft situationsspezifisch ist, wird erwartet, dass die Technologie allgegenwärtiger wird und die Art und Weise, wie das Internet genutzt wird, verändert, was mehr Abstraktion und potenzielle Anwendungsfälle für Edge-Technologie mit sich bringt.
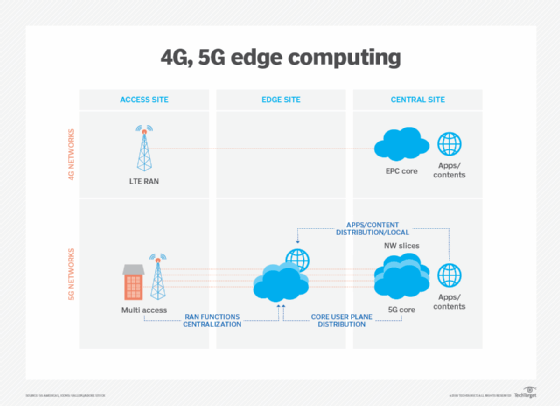
Dies zeigt sich in der Verbreitung von Rechen-, Speicher- und Netzwerk-Appliance-Produkten, die speziell für Edge Computing entwickelt wurden. Mehr herstellerübergreifende Partnerschaften werden eine bessere Produkt-Interoperabilität und Flexibilität am Edge ermöglichen. Ein Beispiel ist eine Partnerschaft zwischen AWS und Verizon, um eine bessere Konnektivität zum Edge zu ermöglichen.Drahtlose Kommunikationstechnologien wie 5G und Wi-Fi 6 werden sich in den kommenden Jahren auch auf die Edge-Bereitstellung und -Nutzung auswirken und Virtualisierungs- und Automatisierungsfunktionen ermöglichen, die noch nicht erforscht sind, wie z. B. eine bessere Fahrzeugautonomie und Workload-Migrationen zum Edge, während drahtlose Netzwerke flexibler und kostengünstiger werden.
Edge Computing wurde mit dem Aufkommen des IoT und der plötzlichen Datenschwemme, die solche Geräte produzieren, bekannt. Da sich IoT-Technologien jedoch noch in den Kinderschuhen befinden, wird sich die Entwicklung von IoT-Geräten auch auf die zukünftige Entwicklung von Edge Computing auswirken. Ein Beispiel für solche zukünftigen Alternativen ist die Entwicklung von Micro Modular Data Centers (MMDCs). Das MMDC ist im Grunde ein Rechenzentrum in einer Box, das ein komplettes Rechenzentrum in ein kleines mobiles System integriert, das näher an den Daten eingesetzt werden kann – z. B. in einer Stadt oder einer Region -, um die Datenverarbeitung viel näher an die Daten heranzuführen, ohne den Rand zu setzen an den Daten selbst.