Edge computing är en distribuerad informationsteknologi (IT) arkitektur där klientdata behandlas i nätverkets periferi, så nära ursprungskällan som möjligt.
Data är livsnerven i modern verksamhet, vilket ger värdefull affärsinsikt och stöder realtidskontroll över kritiska affärsprocesser och verksamheter. Dagens företag är översvämmade i ett hav av data, och enorma mängder data kan rutinmässigt samlas in från sensorer och IoT-enheter som arbetar i realtid från avlägsna platser och ogästvänliga driftsmiljöer nästan var som helst i världen.
men denna virtuella flod av data förändrar också hur företag hanterar databehandling. Det traditionella datorparadigmet byggt på ett centraliserat datacenter och vardagligt internet är inte väl lämpat för att flytta oändligt växande floder av verkliga data. Bandbreddsbegränsningar, latensproblem och oförutsägbara Nätverksstörningar kan alla konspirera för att försämra sådana ansträngningar. Företag svarar på dessa datautmaningar genom användning av edge computing architecture.
i enklaste termer flyttar edge computing en del av lagrings-och beräkningsresurser från det centrala datacentret och närmare källan till själva data. I stället för att överföra rådata till ett centralt datacenter för bearbetning och analys utförs det arbetet istället där data faktiskt genereras-oavsett om det är en butik, ett fabriksgolv, ett spridande verktyg eller över en smart stad. Endast resultatet av det datorarbetet vid kanten, såsom realtidsinsikter, förutsägelser om underhåll av utrustning eller andra handlingsbara svar, skickas tillbaka till huvuddatacentret för granskning och andra mänskliga interaktioner.
således omformar edge computing IT och business computing. Ta en omfattande titt på vad edge computing är, hur det fungerar, molnens inflytande, edge-användningsfall, avvägningar och implementeringshänsyn.
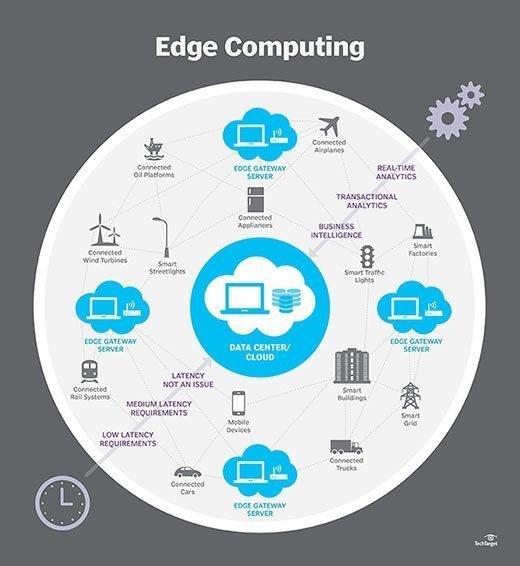
hur fungerar edge computing?
Edge computing är en fråga om plats. I traditionell företagsberäkning produceras data på en klientens slutpunkt, till exempel en användares dator. Dessa data flyttas över ett WAN som internet, via företagets LAN, där data lagras och bearbetas av en företagsapplikation. Resultatet av det arbetet överförs sedan tillbaka till kundens slutpunkt. Detta är fortfarande ett beprövat och tidtestat tillvägagångssätt för klient-serverberäkning för de flesta typiska affärsapplikationer.
men antalet enheter som är anslutna till internet och volymen av data som produceras av dessa enheter och används av företag växer alltför snabbt för att traditionella datacenterinfrastrukturer ska kunna rymma. Gartner förutspådde att år 2025 kommer 75% av företagsgenererade data att skapas utanför centraliserade datacenter. Utsikterna att flytta så mycket data i situationer som ofta kan vara tids – eller störningskänsliga sätter otrolig belastning på det globala internet, som i sig ofta utsätts för trängsel och störningar.
så IT-arkitekter har skiftat fokus från det centrala datacentret till den logiska kanten av infrastrukturen-tar lagrings-och datorresurser från datacentret och flyttar dessa resurser till den punkt där data genereras. Principen är enkel: om du inte kan få data närmare datacentret, få datacentret närmare data. Begreppet edge computing är inte nytt, och det är rotat i årtionden gamla ideer om fjärrberäkning-som fjärrkontor och filialkontor-där det var mer tillförlitligt och effektivt att placera datorresurser på önskad plats snarare än att förlita sig på en enda central plats.

Edge computing sätter lagring och servrar där data är, ofta kräver lite mer än en partiell kuggstång för att fungera på fjärrlan för att samla in och bearbeta data lokalt. I många fall används datorutrustningen i skärmade eller härdade höljen för att skydda växeln från extrema temperaturer, fukt och andra miljöförhållanden. Bearbetning innebär ofta normalisering och analys av dataströmmen för att leta efter Business intelligence, och endast resultaten av analysen skickas tillbaka till huvuddatacentret.
tanken på Business intelligence kan variera dramatiskt. Några exempel är detaljhandelsmiljöer där videoövervakning av showroom-golvet kan kombineras med faktiska försäljningsdata för att bestämma den mest önskvärda produktkonfigurationen eller konsumenternas efterfrågan. Andra exempel innefattar prediktiv analys som kan styra underhåll och reparation av utrustning innan faktiska fel eller fel uppstår. Ytterligare andra exempel är ofta anpassade till verktyg, såsom vattenrening eller elproduktion, för att säkerställa att utrustningen fungerar korrekt och för att upprätthålla kvaliteten på produktionen.
Edge vs. moln vs. fog computing
Edge computing är nära associerad med begreppen cloud computing och fog computing. Även om det finns en viss överlappning mellan dessa begrepp, är de inte samma sak, och i allmänhet bör inte användas omväxlande. Det är bra att jämföra begreppen och förstå deras skillnader.
ett av de enklaste sätten att förstå skillnaderna mellan edge, cloud och fog computing är att lyfta fram deras gemensamma tema: Alla tre koncepten relaterar till distribuerad databehandling och fokuserar på fysisk distribution av beräknings-och lagringsresurser i förhållande till de data som produceras. Skillnaden är en fråga om var dessa resurser finns.
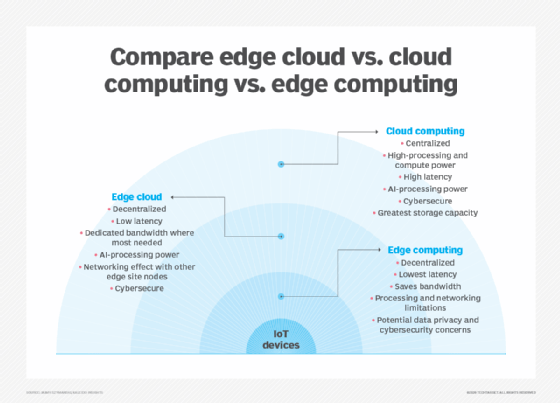
kant. Edge computing är utbyggnaden av dator-och lagringsresurser på den plats där data produceras. Detta sätter idealiskt beräkning och lagring vid samma punkt som datakällan vid nätverkskanten. Till exempel kan ett litet hölje med flera servrar och viss lagring installeras ovanpå en vindkraftverk för att samla in och bearbeta data som produceras av sensorer i själva turbinen. Som ett annat exempel kan en järnvägsstation placera en blygsam mängd beräkning och lagring inom stationen för att samla in och bearbeta otaliga spår-och järnvägstrafiksensordata. Resultaten av sådan behandling kan sedan skickas tillbaka till ett annat datacenter för mänsklig granskning, arkivering och slås samman med andra dataresultat för bredare analyser.
moln. Cloud computing är en enorm, mycket skalbar distribution av beräknings-och lagringsresurser på en av flera distribuerade globala platser (regioner). Molnleverantörer innehåller också ett sortiment av färdigförpackade tjänster för IoT-operationer, vilket gör molnet till en föredragen centraliserad plattform för IoT-distributioner. Men även om cloud computing erbjuder mycket mer än tillräckligt med resurser och tjänster för att hantera komplexa analyser, kan den närmaste regionala molnanläggningen fortfarande vara hundratals mil från den punkt där data samlas in, och anslutningar är beroende av samma temperamentsfulla internetanslutning som stöder traditionella datacenter. I praktiken är cloud computing ett alternativ-eller ibland ett komplement-till traditionella datacenter. Molnet kan få centraliserad databehandling mycket närmare en datakälla, men inte vid nätverkskanten.
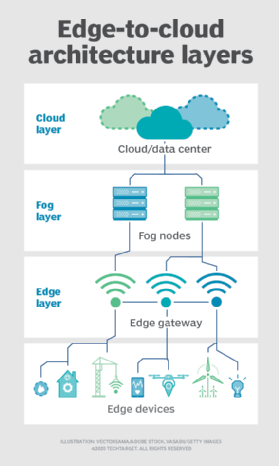
dimma. Men valet av beräknings-och lagringsdistribution är inte begränsat till molnet eller edge. Ett molndatacenter kan vara för långt borta, men edge-distributionen kan helt enkelt vara för resursbegränsad, eller fysiskt spridd eller distribuerad, för att göra strikt edge computing praktiskt. I detta fall kan begreppet dimma beräkning hjälpa. Fog computing tar vanligtvis ett steg tillbaka och sätter beräknings-och lagringsresurser ”inom” data, men inte nödvändigtvis ”på” data.
Fog-datormiljöer kan producera förvirrande mängder sensor-eller IoT-data som genereras över expansiva fysiska områden som bara är för stora för att definiera en kant. Exempel är smarta byggnader, smarta städer eller till och med smarta verktygsnät. Tänk på en smart stad där data kan användas för att spåra, analysera och optimera kollektivtrafiksystemet, kommunala verktyg, stadstjänster och vägleda långsiktig stadsplanering. En enda kantdistribution räcker helt enkelt inte för att hantera en sådan belastning, så fog computing kan driva en serie dimmnoddistributioner inom ramen för miljön för att samla in, bearbeta och analysera data.
Obs: Det är viktigt att upprepa att fog computing och edge computing delar en nästan identisk definition och arkitektur, och termerna används ibland omväxlande även bland teknikexperter.
Varför spelar edge computing Roll?
datoruppgifter kräver lämpliga arkitekturer, och arkitekturen som passar en typ av datoruppgift passar inte nödvändigtvis alla typer av datoruppgifter. Edge computing har framstått som en livskraftig och viktig arkitektur som stöder distribuerad databehandling för att distribuera beräknings-och lagringsresurser närmare-helst på samma fysiska plats som-datakällan. I allmänhet är distribuerade datormodeller knappast nya, och begreppen fjärrkontor, filialkontor, datacenterkolokalisering och molnberäkning har en lång och beprövad rekord.men decentralisering kan vara utmanande och kräver höga nivåer av övervakning och kontroll som lätt förbises när man flyttar sig från en traditionell centraliserad datormodell. Edge computing har blivit relevant eftersom det erbjuder en effektiv lösning på nya nätverksproblem i samband med att flytta enorma datamängder som dagens organisationer producerar och konsumerar. Det är inte bara ett problem med mängden. Det är också en tidsfråga; applikationer beror på bearbetning och svar som blir alltmer tidskänsliga.
Tänk på ökningen av självkörande bilar. De kommer att bero på intelligenta trafikstyrningssignaler. Bilar och trafikkontroller måste producera, analysera och utbyta data i realtid. Multiplicera detta krav med ett stort antal autonoma fordon, och omfattningen av de potentiella problemen blir tydligare. Detta kräver ett snabbt och responsivt nätverk. Edge – och fog-computing adresserar tre huvudsakliga nätverksbegränsningar: bandbredd, latens och trängsel eller tillförlitlighet.
- bandbredd. Bandbredd är mängden data som ett nätverk kan bära över tiden, vanligtvis uttryckt i bitar per sekund. Alla nätverk har en begränsad bandbredd, och gränserna är svårare för trådlös kommunikation. Detta innebär att det finns en begränsad gräns för mängden data-eller antalet enheter-som kan kommunicera data över nätverket. Även om det är möjligt att öka nätverksbandbredden för att rymma fler enheter och data, kan kostnaden vara betydande, Det finns fortfarande (högre) ändliga gränser och det löser inte andra problem.
- latens. Latens är den tid som behövs för att skicka data mellan två punkter i ett nätverk. Även om kommunikation idealiskt sker med ljusets hastighet kan stora fysiska avstånd i kombination med överbelastning eller avbrott i nätverket fördröja datarörelsen över nätverket. Detta fördröjer alla analyser och beslutsprocesser och minskar möjligheten för ett system att svara i realtid. Det kostar till och med liv i det autonoma fordonsexemplet.
- trängsel. Internet är i grunden ett globalt ” nätverk av nätverk.”Även om det har utvecklats för att erbjuda bra allmänna datautbyten för de flesta vardagliga datoruppgifter-som filutbyten eller grundläggande streaming-kan volymen av data som är involverad i tiotals miljarder enheter överväldiga internet, vilket orsakar höga nivåer av trängsel och tvingar tidskrävande dataöverföring. I andra fall kan nätverksavbrott förvärra trängsel och till och med avbryta kommunikationen till vissa Internetanvändare helt – vilket gör Internet of things värdelös under avbrott.
genom att distribuera servrar och lagring där data genereras kan edge computing använda många enheter över ett mycket mindre och effektivare LAN där riklig bandbredd endast används av lokala datagenererande enheter, vilket gör latens och trängsel praktiskt taget obefintlig. Lokal lagring samlar in och skyddar rådata, medan lokala servrar kan utföra viktiga edge-analyser – eller åtminstone förbehandla och minska data-för att fatta beslut i realtid innan de skickar resultat, eller bara viktiga data, till molnet eller det centrala datacentret.
Edge computing användningsfall och exempel
i princip används edge computing-tekniker för att samla in, filtrera, bearbeta och analysera data ”på plats” vid eller nära nätverkskanten. Det är ett kraftfullt sätt att använda data som inte kan flyttas först till en centraliserad plats-vanligtvis för att den stora datamängden gör sådana drag kostnadseffektiva, Tekniskt opraktiska eller annars kan bryta mot efterlevnadsförpliktelser, såsom datasuveränitet. Denna definition har gett upphov till otaliga verkliga exempel och användningsfall:
- tillverkning. En industriell tillverkare distribuerade edge computing för att övervaka tillverkningen, vilket möjliggör analys i realtid och maskininlärning vid kanten för att hitta produktionsfel och förbättra produkttillverkningskvaliteten. Edge computing stödde tillägget av miljösensorer i hela tillverkningsanläggningen, vilket gav insikt i hur varje produktkomponent monteras och lagras-och hur länge komponenterna finns kvar i lager. Tillverkaren kan nu fatta snabbare och mer exakta affärsbeslut angående fabriksfaciliteten och tillverkningsverksamheten.
- jordbruk. Tänk på ett företag som odlar grödor inomhus utan solljus, jord eller bekämpningsmedel. Processen minskar växlingstiderna med mer än 60%. Med hjälp av sensorer kan verksamheten spåra vattenanvändning, näringsdensitet och bestämma optimal skörd. Data samlas in och analyseras för att hitta effekterna av miljöfaktorer och kontinuerligt förbättra grödodlingsalgoritmerna och se till att grödor skördas i toppskick.
- nätverksoptimering. Edge computing kan hjälpa till att optimera nätverksprestanda genom att mäta prestanda för användare över hela internet och sedan använda analyser för att bestämma den mest tillförlitliga nätverksbanan med låg latens för varje användares trafik. I själva verket används edge computing för att” styra ” trafik över nätverket för optimal tidskänslig trafikprestanda.
- säkerhet på arbetsplatsen. Edge computing kan kombinera och analysera data från kameror på plats, anställdas säkerhetsanordningar och olika andra sensorer för att hjälpa företag att övervaka arbetsplatsförhållandena eller se till att anställda följer etablerade säkerhetsprotokoll-särskilt när arbetsplatsen är avlägsen eller ovanligt farlig, till exempel byggarbetsplatser eller oljeriggar.
- förbättrad sjukvård. Sjukvårdsindustrin har dramatiskt utökat mängden patientdata som samlats in från enheter, sensorer och annan medicinsk utrustning. Den enorma datavolymen kräver edge computing för att tillämpa automatisering och maskininlärning för att komma åt data, ignorera ”normala” data och identifiera problemdata så att kliniker kan vidta omedelbara åtgärder för att hjälpa patienter att undvika hälsoincidenter i realtid.
- transport. Autonoma fordon kräver och producerar allt från 5 TB till 20 TB per dag och samlar information om plats, hastighet, fordonskondition, vägförhållanden, trafikförhållanden och andra fordon. Och data måste aggregeras och analyseras i realtid, medan fordonet är i rörelse. Detta kräver betydande ombordberäkning – varje autonomt fordon blir en ” kant.”Dessutom kan uppgifterna hjälpa myndigheter och företag att hantera fordonsflottor baserat på faktiska förhållanden på marken.
- detaljhandel. Detaljhandelsföretag kan också producera enorma datavolymer från övervakning, lagerspårning, försäljningsdata och andra affärsuppgifter i realtid. Edge computing kan hjälpa till att analysera dessa olika data och identifiera affärsmöjligheter, till exempel en effektiv endcap eller kampanj, förutsäga försäljning och optimera leverantörsbeställning och så vidare. Eftersom detaljhandeln kan variera dramatiskt i lokala miljöer kan edge computing vara en effektiv lösning för lokal bearbetning i varje butik.
fördelar med edge computing
Edge computing adresserar viktiga infrastrukturutmaningar – såsom bandbreddsbegränsningar, överdriven latens och överbelastning av nätverket-men det finns flera potentiella ytterligare fördelar med edge computing som kan göra tillvägagångssättet tilltalande i andra situationer.
autonomi. Edge computing är användbart där anslutningen är opålitlig eller bandbredd är begränsad på grund av webbplatsens miljöegenskaper. Exempel inkluderar oljeriggar, fartyg till sjöss, avlägsna gårdar eller andra avlägsna platser, såsom regnskog eller öken. Edge computing fungerar beräkningen på plats-ibland på själva edge-enheten-till exempel vattenkvalitetssensorer på vattenrenare i avlägsna byar, och kan spara data för att bara överföra till en central punkt när anslutning är tillgänglig. Genom att bearbeta data lokalt kan mängden data som ska skickas avsevärt minskas, vilket kräver mycket mindre bandbredd eller anslutningstid än vad som annars skulle vara nödvändigt.
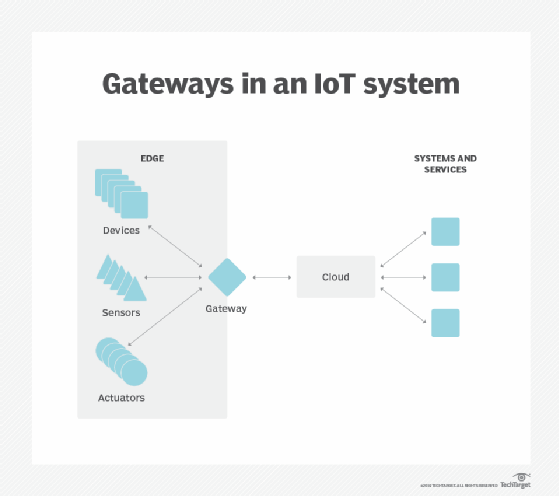
data suveränitet. Att flytta stora mängder data är inte bara ett tekniskt problem. Datas resa över nationella och regionala gränser kan innebära ytterligare problem för datasäkerhet, integritet och andra juridiska frågor. Edge computing kan användas för att hålla data nära källan och inom gränserna för rådande datasuveränitetslagar, till exempel EU: s GDPR, som definierar hur data ska lagras, bearbetas och exponeras. Detta kan göra det möjligt att bearbeta rådata lokalt, dölja eller säkra känsliga data innan du skickar något till molnet eller det primära datacentret, vilket kan vara i andra jurisdiktioner.
kant säkerhet. Slutligen erbjuder edge computing ytterligare en möjlighet att implementera och säkerställa datasäkerhet. Även om molnleverantörer har IoT-tjänster och är specialiserade på komplex analys, förblir företagen oroade över säkerheten och säkerheten för data när den lämnar kanten och reser tillbaka till molnet eller datacentret. Genom att implementera databehandling vid kanten kan alla data som passerar nätverket tillbaka till molnet eller datacentret säkras genom kryptering, och själva Edge-distributionen kan härdas mot hackare och andra skadliga aktiviteter-även när säkerheten på IoT-enheter förblir begränsad.
utmaningar för edge computing
även om edge computing har potential att ge övertygande fördelar över en mängd användningsfall, är tekniken långt ifrån idiotsäker. Utöver de traditionella problemen med nätverksbegränsningar finns det flera viktiga överväganden som kan påverka antagandet av edge computing:
- begränsad kapacitet. En del av lockelsen som cloud computing ger till edge-eller fog-computing är mångfalden och omfattningen av resurser och tjänster. Att distribuera en infrastruktur i edge kan vara effektivt, men omfattningen och syftet med edge-distributionen måste tydligt definieras-även en omfattande edge computing-distribution tjänar ett specifikt syfte i en förutbestämd skala med begränsade resurser och få tjänster.
- anslutning. Edge computing övervinner typiska nätverksbegränsningar, men även den mest förlåtande edge-distributionen kräver viss miniminivå av anslutning. Det är viktigt att utforma en edge-distribution som rymmer dålig eller oregelbunden anslutning och överväga vad som händer vid kanten när anslutningen går förlorad. Autonomi, AI och graciös misslyckande planering i kölvattnet av anslutningsproblem är avgörande för framgångsrik edge computing.
- säkerhet. IoT-enheter är notoriskt osäkra, så det är viktigt att utforma en edge computing-distribution som kommer att betona korrekt enhetshantering, såsom policydriven konfigurationshantering, samt säkerhet i dator-och lagringsresurser-inklusive faktorer som programvarupatchning och uppdateringar-med särskild uppmärksamhet på kryptering i data i vila och under flygning. IoT-tjänster från stora molnleverantörer inkluderar säker kommunikation, men det är inte automatiskt när man bygger en edge-webbplats från början.
- data livscykler. Det ständiga problemet med dagens dataglut är att så mycket av den informationen är onödig. Tänk på en medicinsk övervakningsenhet-det är bara problemdata som är kritiska, och det är liten mening att hålla dagar med normala patientdata. De flesta data som är involverade i realtidsanalys är kortsiktiga data som inte lagras på lång sikt. Ett företag måste bestämma vilka data som ska behållas och vad som ska kasseras när analyser utförs. Och de uppgifter som lagras måste skyddas i enlighet med affärs-och regleringspolicyer.
Edge computing implementation
Edge computing är en enkel ide som kan se lätt ut på papper, men att utveckla en sammanhängande strategi och implementera en ljuddistribution vid kanten kan vara en utmanande övning.
det första viktiga elementet i en framgångsrik teknikdistribution är skapandet av en meningsfull affärs-och teknisk kantstrategi. En sådan strategi handlar inte om att plocka leverantörer eller redskap. Istället tar en edge-strategi hänsyn till behovet av edge computing. Att förstå ”varför” kräver en tydlig förståelse för de tekniska och affärsproblem som organisationen försöker lösa, till exempel att övervinna nätverksbegränsningar och observera datasuveränitet.

sådana strategier kan börja med en diskussion om precis vad kanten betyder, var den finns för verksamheten och hur den ska gynna organisationen. Edge-strategier bör också anpassas till befintliga affärsplaner och tekniska färdplaner. Om företaget till exempel försöker minska sitt centraliserade datacenteravtryck, kan edge och annan distribuerad datateknik anpassa sig väl.
När projektet närmar sig implementeringen är det viktigt att utvärdera hårdvaru-och programvarualternativ noggrant. Det finns många leverantörer i edge – datorutrymmet, inklusive Adlink Technology, Cisco, Amazon, Dell EMC och HPE. Varje produktutbud måste utvärderas för kostnad, prestanda, funktioner, interoperabilitet och support. Ur ett mjukvaruperspektiv bör verktyg ge omfattande synlighet och kontroll över fjärrkantmiljön.
den faktiska utplaceringen av ett edge computing-initiativ kan variera dramatiskt i omfattning och skala, allt från vissa lokala datorutrustning i ett stridshärdat hölje ovanpå ett verktyg till ett stort antal sensorer som matar en nätverksanslutning med hög bandbredd, låg latens till det offentliga molnet. Inga två edge-distributioner är desamma. Det är dessa variationer som gör edge strategi och planering så avgörande för edge projekt framgång.
en edge-distribution kräver omfattande övervakning. Kom ihåg att det kan vara svårt-eller till och med omöjligt-att få IT-Personal till den fysiska kantplatsen, så kantutplaceringar bör utformas för att ge motståndskraft, feltolerans och självläkande förmåga. Övervakningsverktyg måste erbjuda en tydlig överblick över fjärrdistributionen, möjliggöra enkel provisionering och konfiguration, erbjuda omfattande varningar och rapportering och upprätthålla säkerheten för installationen och dess data. Edge övervakning innebär ofta en rad mätvärden och KPI: er, såsom plats tillgänglighet eller drifttid, nätverksprestanda, lagringskapacitet och utnyttjande, och beräkna resurser.
och ingen edge-implementering skulle vara komplett utan noggrant övervägande av edge maintenance:
- säkerhet. Fysiska och logiska säkerhetsåtgärder är viktiga och bör omfatta verktyg som betonar sårbarhetshantering och intrångsdetektering och förebyggande. Säkerheten måste utvidgas till sensor-och IoT-enheter, eftersom varje enhet är ett nätverkselement som kan nås eller hackas-presentera ett förvirrande antal möjliga attackytor.
- anslutning. Anslutning är en annan fråga, och bestämmelser måste göras för tillgång till kontroll och rapportering även när anslutning för de faktiska uppgifterna inte är tillgänglig. Vissa edge-distributioner använder en sekundär anslutning för säkerhetskopiering och kontroll.
- förvaltning. De avlägsna och ofta ogästvänliga platserna för edge-distributioner gör fjärradministration och hantering nödvändig. IT-chefer måste kunna se vad som händer vid kanten och kunna kontrollera distributionen vid behov.
- fysiskt underhåll. Fysiska underhållskrav kan inte förbises. IoT-enheter har ofta begränsad livslängd med rutinmässiga batteri-och enhetsbyten. Gear misslyckas och kräver så småningom underhåll och utbyte. Praktisk platslogistik måste ingå i underhållet.
Edge computing, IoT och 5G möjligheter
Edge computing fortsätter att utvecklas, med hjälp av ny teknik och praxis för att förbättra dess kapacitet och prestanda. Den kanske mest anmärkningsvärda trenden är edge tillgänglighet, och edge-tjänster förväntas bli tillgängliga över hela världen av 2028. Där edge computing ofta är situationsspecifik idag förväntas tekniken bli mer allestädes närvarande och förändra sättet som internet används, vilket ger mer abstraktion och potentiella användningsfall för edge-teknik.
detta kan ses i spridningen av dator -, lagrings-och nätverksapparatprodukter som är speciellt utformade för kantberäkning. Fler multivendor-partnerskap kommer att möjliggöra bättre Produktkompatibilitet och flexibilitet i kanten. Ett exempel inkluderar ett partnerskap mellan AWS och Verizon för att få bättre anslutning till kanten.
trådlös kommunikationsteknik, som 5G och Wi-Fi 6, kommer också att påverka Edge-distributioner och utnyttjande under de kommande åren, vilket möjliggör virtualiserings-och automatiseringsfunktioner som ännu inte har utforskats, till exempel bättre fordonsautonomi och arbetsbelastningsmigrationer till edge, samtidigt som trådlösa nätverk blir mer flexibla och kostnadseffektiva.
Edge computing fick meddelande med ökningen av IoT och den plötsliga överflöd av data som sådana enheter producerar. Men med IoT-teknik fortfarande i relativ spädbarn kommer utvecklingen av IoT-enheter också att påverka den framtida utvecklingen av edge computing. Ett exempel på sådana framtida alternativ är utvecklingen av mikromodulära datacenter (MMDCs). MMDC är i grunden ett datacenter i en låda och sätter ett komplett datacenter i ett litet mobilsystem som kan distribueras närmare data-till exempel över en stad eller en region-för att få datorer mycket närmare data utan att sätta kanten på rätt data.