Edge computing to rozproszona Architektura informatyczna (IT), w której dane klientów są przetwarzane na peryferiach sieci, jak najbliżej źródła, z którego pochodzą.
dane są siłą napędową nowoczesnego biznesu, zapewniając cenne informacje biznesowe i wspierając kontrolę w czasie rzeczywistym nad krytycznymi procesami i operacjami biznesowymi. Dzisiejsze firmy są zalane oceanem danych, a ogromne ilości danych mogą być rutynowo gromadzone z czujników i urządzeń IoT pracujących w czasie rzeczywistym z odległych lokalizacji i nieprzyjaznych środowisk operacyjnych niemal z dowolnego miejsca na świecie.
ale ten wirtualny zalew danych zmienia również sposób, w jaki firmy radzą sobie z komputerami. Tradycyjny paradygmat obliczeniowy zbudowany na scentralizowanym centrum danych i codziennym Internecie nie nadaje się do przenoszenia nieskończenie rosnących rzek rzeczywistych danych. Ograniczenia przepustowości, problemy z opóźnieniami i nieprzewidywalne zakłócenia sieci mogą utrudniać takie wysiłki. Firmy reagują na te wyzwania dzięki zastosowaniu nowoczesnej architektury obliczeniowej.
najprościej mówiąc, edge computing przenosi część pamięci masowej i zasobów obliczeniowych z centralnego centrum danych i bliżej źródła samych danych. Zamiast przesyłać surowe dane do centralnego centrum danych w celu ich przetwarzania i analizy, praca ta jest wykonywana tam , gdzie dane są faktycznie generowane-czy to w sklepie detalicznym, fabryce, rozległym przedsiębiorstwie czy w inteligentnym mieście. Tylko wyniki pracy obliczeniowej w edge, takie jak analizy biznesowe w czasie rzeczywistym, prognozy dotyczące konserwacji sprzętu lub inne możliwe do zastosowania odpowiedzi, są przesyłane z powrotem do głównego centrum danych w celu przeglądu i innych interakcji z ludźmi.
edge computing przekształca informatykę i informatykę biznesową. Kompleksowo przyjrzyj się, czym jest edge computing, jak działa, wpływowi chmury, przypadkom użycia edge, kompromisom i względom implementacji.
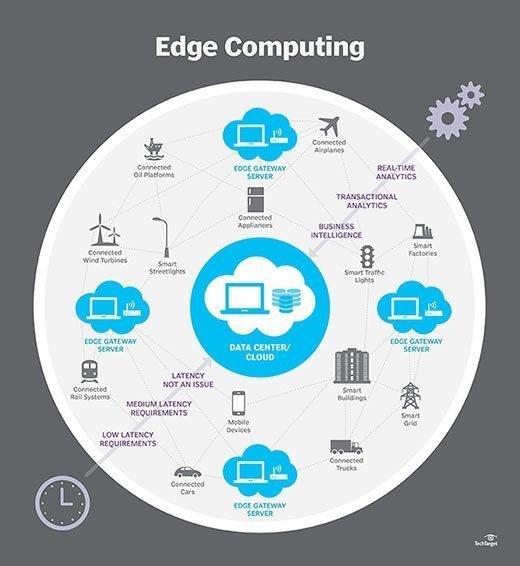
Jak działa edge computing?
Edge computing to wszystko kwestia lokalizacji. W tradycyjnych komputerach korporacyjnych dane są generowane w punkcie końcowym klienta, takim jak komputer użytkownika. Dane te są przesyłane przez sieć WAN, taką jak internet, przez korporacyjną sieć LAN, gdzie dane są przechowywane i przetwarzane przez aplikację korporacyjną. Wyniki tych prac są następnie przekazywane z powrotem do punktu końcowego klienta. Pozostaje to sprawdzone i sprawdzone podejście do przetwarzania klient-serwer dla większości typowych aplikacji biznesowych.
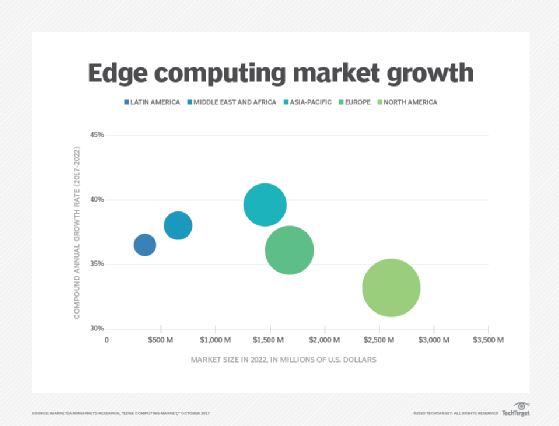
jednak liczba urządzeń podłączonych do Internetu oraz ilość danych wytwarzanych przez te urządzenia i wykorzystywanych przez firmy rośnie zbyt szybko, aby mogła pomieścić tradycyjną infrastrukturę centrów danych. Firma Gartner przewiduje, że do 2025 r. 75% danych generowanych przez przedsiębiorstwa będzie tworzone poza scentralizowanymi centrami danych. Perspektywa przenoszenia tak dużej ilości danych w sytuacjach, które często mogą być wrażliwe na czas lub zakłócenia, powoduje ogromne obciążenie globalnej sieci internet, która sama w sobie jest często narażona na zatory i zakłócenia.
architekci it przenieśli więc uwagę z centralnego centrum danych na logiczną krawędź infrastruktury — pobierając zasoby pamięci masowej i obliczeniowe z centrum danych i przenosząc je do punktu, w którym generowane są dane. Zasada jest prosta: jeśli nie możesz zbliżyć danych do centrum danych, zbliż je do nich. Koncepcja edge computing nie jest nowa i jest zakorzeniona w kilkudziesięcioletnich ideach zdalnego przetwarzania, takich jak zdalne biura i oddziały, gdzie bardziej niezawodne i wydajne było umieszczanie zasobów obliczeniowych w pożądanym miejscu, niż poleganie na jednej centralnej lokalizacji.

Edge computing stawia pamięć masową i serwery tam, gdzie są dane, często wymagając niewiele więcej niż częściowego sprzętu do pracy w zdalnej sieci LAN w celu gromadzenia i przetwarzania danych lokalnie. W wielu przypadkach sprzęt komputerowy jest instalowany w ekranowanych lub hartowanych obudowach, aby chronić go przed ekstremalnymi temperaturami, wilgocią i innymi warunkami środowiskowymi. Przetwarzanie często wiąże się z normalizacją i analizą strumienia danych w celu poszukiwania Business intelligence, a tylko wyniki analizy są wysyłane z powrotem do głównego centrum danych.
idea Business intelligence może się diametralnie różnić. Niektóre przykłady obejmują środowiska detaliczne, w których Nadzór wideo na podłodze salonu może być połączony z rzeczywistymi danymi sprzedaży w celu określenia najbardziej pożądanej konfiguracji produktu lub popytu konsumentów. Inne przykłady obejmują analizy predykcyjne, które mogą prowadzić do konserwacji i naprawy sprzętu, zanim wystąpią rzeczywiste usterki lub awarie. Nadal inne przykłady są często dostosowane do mediów, takich jak Uzdatnianie wody lub wytwarzanie energii elektrycznej, aby zapewnić prawidłowe działanie urządzeń i utrzymać jakość produkcji.
Edge vs. cloud vs. Fog computing
Edge computing jest ściśle związany z pojęciami cloud computing i fog computing. Chociaż istnieje pewne nakładanie się tych pojęć, nie są one tym samym i generalnie nie powinny być używane zamiennie. Pomocne jest porównanie pojęć i zrozumienie ich różnic.
jednym z najprostszych sposobów na zrozumienie różnic między edge, cloud i fog computing jest podkreślenie ich wspólnego tematu: Wszystkie trzy koncepcje odnoszą się do obliczeń rozproszonych i koncentrują się na fizycznym rozmieszczeniu zasobów obliczeniowych i pamięci masowej w odniesieniu do wytwarzanych danych. Różnica polega na tym, gdzie znajdują się te zasoby.
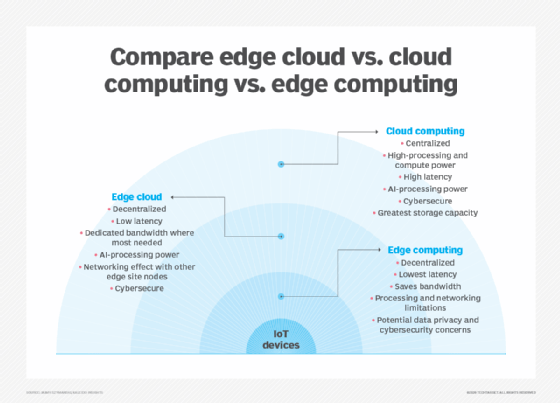
Edge. Edge computing to wdrożenie zasobów obliczeniowych i pamięci masowej w miejscu, w którym wytwarzane są dane. Dzięki temu obliczenia i pamięć masowa znajdują się w tym samym punkcie, co źródło danych na krawędzi sieci. Na przykład mała obudowa z kilkoma serwerami i pamięcią masową może zostać zainstalowana na turbinie wiatrowej w celu gromadzenia i przetwarzania danych wytwarzanych przez czujniki w samej turbinie. Jako inny przykład, stacja kolejowa może umieścić niewielką ilość obliczeń i przechowywania na stacji w celu gromadzenia i przetwarzania niezliczonych danych z czujników ruchu kolejowego i kolejowego. Wyniki takiego przetwarzania mogą być następnie przesłane z powrotem do innego centrum danych w celu przeglądu, archiwizacji i scalenia z innymi wynikami danych w celu szerszej analizy.
Chmura. Cloud computing to ogromne, wysoce skalowalne wdrożenie zasobów obliczeniowych i pamięci masowej w jednym z kilku rozproszonych globalnych lokalizacji (regionów). Dostawcy usług chmurowych zawierają również asortyment wstępnie zapakowanych usług dla operacji IoT, dzięki czemu chmura jest preferowaną scentralizowaną platformą dla wdrożeń IoT. Mimo że przetwarzanie w chmurze oferuje znacznie więcej niż wystarczającą ilość zasobów i usług do kompleksowej analizy, najbliższy regionalny obiekt w chmurze nadal może znajdować się setki mil od miejsca, w którym gromadzone są dane, a połączenia opierają się na tej samej temperamentnej łączności z Internetem, która obsługuje tradycyjne centra danych. W praktyce przetwarzanie w chmurze jest alternatywą , a czasem uzupełnieniem tradycyjnych centrów danych. Chmura może uzyskać scentralizowane przetwarzanie znacznie bliżej źródła danych, ale nie na krawędzi sieci.
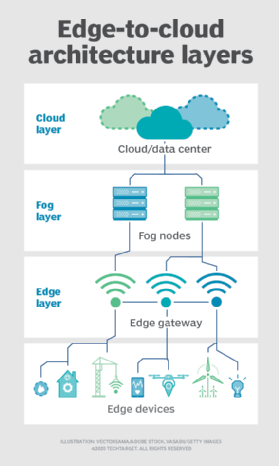
Ale wybór wdrożenia obliczeniowego i pamięci masowej nie ogranicza się do chmury ani krawędzi. Centrum danych w chmurze może być zbyt daleko, ale wdrożenie brzegowe może być po prostu zbyt ograniczone zasobami lub fizycznie rozproszone lub rozproszone, aby ścisłe przetwarzanie brzegowe było praktyczne. W tym przypadku może pomóc pojęcie Fog computing. Fog computing zazwyczaj robi krok wstecz i umieszcza zasoby obliczeniowe i magazynowe ” w „danych, ale niekoniecznie” w ” danych.
środowiska obliczeniowe mgły mogą wytwarzać oszałamiające ilości danych z czujników lub IoT generowanych w rozległych obszarach fizycznych, które są po prostu zbyt duże, aby zdefiniować krawędź. Przykłady obejmują inteligentne budynki, inteligentne miasta, a nawet inteligentne sieci użyteczności publicznej. Rozważ inteligentne miasto, w którym dane mogą być wykorzystywane do śledzenia, analizowania i optymalizacji systemu transportu publicznego, usług komunalnych, usług miejskich i długoterminowego planowania urbanistycznego. Pojedyncze wdrożenie krawędzi po prostu nie wystarcza, aby poradzić sobie z takim obciążeniem, więc Fog computing może obsługiwać szereg wdrożeń węzłów fog W ramach środowiska w celu gromadzenia, przetwarzania i analizy danych.
Uwaga: ważne jest, aby powtórzyć, że Fog computing i edge computing mają prawie identyczną definicję i architekturę, a terminy te są czasami używane zamiennie nawet wśród ekspertów technologicznych.
dlaczego edge computing ma znaczenie?
zadania obliczeniowe wymagają odpowiednich architektur, a architektura odpowiadająca jednemu typowi zadań obliczeniowych niekoniecznie pasuje do wszystkich typów zadań obliczeniowych. Edge computing stało się realną i ważną architekturą, która obsługuje przetwarzanie rozproszone w celu wdrożenia zasobów obliczeniowych i pamięci masowej bliżej-najlepiej w tej samej fizycznej lokalizacji, co-źródło danych. Ogólnie rzecz biorąc, modele przetwarzania rozproszonego nie są niczym nowym, A koncepcje zdalnych biur, oddziałów, kolokacji centrów danych i przetwarzania w chmurze mają długą i sprawdzoną historię.
ale decentralizacja może być wyzwaniem, wymagającym wysokiego poziomu monitorowania i kontroli, które łatwo przeoczyć, gdy odejdzie od tradycyjnego scentralizowanego modelu obliczeniowego. Edge computing stało się istotne, ponieważ oferuje skuteczne rozwiązanie pojawiających się problemów sieciowych związanych z przenoszeniem ogromnych ilości danych, które dzisiejsze organizacje produkują i zużywają. Nie chodzi tylko o ilość. Jest to również kwestia czasu; Aplikacje zależą od przetwarzania i odpowiedzi, które są coraz bardziej wrażliwe na czas.
rozważ rozwój AUT samojezdnych. Będą one zależeć od inteligentnych sygnałów sterowania ruchem. Samochody i kontrola ruchu będą musiały produkować, analizować i wymieniać dane w czasie rzeczywistym. Pomnóż ten wymóg przez ogromną liczbę autonomicznych pojazdów, a zakres potencjalnych problemów stanie się jaśniejszy. Wymaga to szybkiej i elastycznej sieci. Edge — i fog — computing rozwiązuje trzy główne ograniczenia sieciowe: przepustowość, opóźnienia i przeciążenia lub niezawodność.
- Przepustowość to ilość danych, które sieć może przenosić w czasie, zwykle wyrażana w bitach na sekundę. Wszystkie sieci mają ograniczoną przepustowość, a ograniczenia są bardziej dotkliwe dla komunikacji bezprzewodowej. Oznacza to, że istnieje ograniczona ilość danych-lub liczba urządzeń-które mogą przekazywać dane w sieci. Chociaż możliwe jest zwiększenie przepustowości sieci, aby pomieścić więcej urządzeń i danych, koszt może być znaczny, nadal istnieją (wyższe) ograniczone limity i nie rozwiązuje to innych problemów.
- opóźnienie. Opóźnienie to czas potrzebny do wysłania danych między dwoma punktami w sieci. Chociaż komunikacja odbywa się idealnie z prędkością światła, duże odległości fizyczne w połączeniu z przeciążeniem sieci lub przerwami w dostawie mogą opóźnić przepływ danych w sieci. Opóźnia to wszelkie procesy analityczne i decyzyjne oraz zmniejsza zdolność systemu do reagowania w czasie rzeczywistym. W przypadku pojazdów autonomicznych kosztowało to nawet życie.
- zatory. Internet jest w zasadzie globalną ” siecią sieci.”Chociaż rozwinęła się, aby oferować dobrą wymianę danych ogólnego przeznaczenia do większości codziennych zadań obliczeniowych-takich jak wymiana plików lub podstawowe przesyłanie strumieniowe-ilość danych związanych z dziesiątkami miliardów urządzeń może przytłoczyć internet, powodując wysoki poziom zatorów i wymuszając czasochłonne retransmisje danych. W innych przypadkach przerwy w działaniu sieci mogą nasilić zatory, a nawet całkowicie zerwać komunikację z niektórymi użytkownikami Internetu, co czyni internet rzeczy bezużytecznymi podczas przerw.
dzięki wdrożeniu serwerów i pamięci masowej, w których generowane są dane, edge computing może obsługiwać wiele urządzeń w znacznie mniejszej i bardziej wydajnej sieci LAN, gdzie duża przepustowość jest wykorzystywana wyłącznie przez lokalne urządzenia generujące dane, dzięki czemu opóźnienia i przeciążenia praktycznie nie występują. Lokalna pamięć masowa gromadzi i chroni surowe dane, podczas gdy lokalne serwery mogą przeprowadzać niezbędne analizy brzegowe-lub przynajmniej wstępnie przetwarzać i zmniejszać dane-w celu podejmowania decyzji w czasie rzeczywistym przed wysłaniem wyników lub tylko podstawowych danych do chmury lub centralnego centrum danych.
przypadki użycia i przykłady obliczeń brzegowych
zasadniczo techniki obliczeń brzegowych są używane do zbierania, filtrowania, przetwarzania i analizy danych „na miejscu” na krawędzi sieci lub w jej pobliżu. Jest to potężny sposób wykorzystania danych, których nie można najpierw przenieść do scentralizowanej lokalizacji-zwykle dlatego, że sama ilość danych sprawia, że takie ruchy są kosztowne, niepraktyczne technologicznie lub mogą w inny sposób naruszać obowiązki zgodności, takie jak suwerenność danych. Definicja ta zrodziła wiele rzeczywistych przykładów i przypadków użycia:
- Manufacturing. Producent przemysłowy wdrożył edge computing w celu monitorowania produkcji, umożliwiając analizę w czasie rzeczywistym i uczenie maszynowe na brzegu, aby znaleźć błędy produkcyjne i poprawić jakość produkcji produktu. Firma Edge computing wspierała dodawanie czujników środowiskowych w całym zakładzie produkcyjnym, zapewniając wgląd w sposób montażu i przechowywania każdego komponentu produktu oraz czas przechowywania komponentów w magazynie. Producent może teraz podejmować szybsze i dokładniejsze decyzje biznesowe dotyczące zakładu produkcyjnego i operacji produkcyjnych.
- Rolnictwo. Rozważ firmę, która uprawia rośliny w pomieszczeniach bez światła słonecznego, gleby lub pestycydów. Proces ten skraca czas wzrostu o ponad 60%. Korzystanie z czujników umożliwia firmie śledzenie zużycia wody, gęstości składników odżywczych i określenie optymalnych zbiorów. Dane są zbierane i analizowane w celu znalezienia wpływu czynników środowiskowych i ciągłego ulepszania algorytmów uprawy i zapewnienia, że zbiory są zbierane w szczytowym stanie.
- optymalizacja sieci. Edge computing może pomóc zoptymalizować wydajność sieci, mierząc wydajność użytkowników w Internecie, a następnie stosując analizy w celu określenia najbardziej niezawodnej ścieżki sieci o niskim opóźnieniu dla ruchu każdego użytkownika. W efekcie, edge computing służy do „kierowania” ruchem w sieci, aby uzyskać optymalną czasową wydajność ruchu.
- bezpieczeństwo w miejscu pracy. Edge computing może łączyć i analizować dane z kamer na miejscu pracy, urządzeń bezpieczeństwa pracowników i różnych innych czujników, aby pomóc firmom nadzorować warunki pracy lub zapewnić, że pracownicy przestrzegają ustalonych protokołów bezpieczeństwa-zwłaszcza gdy miejsce pracy jest odległe lub niezwykle niebezpieczne, takie jak place budowy lub platformy wiertnicze.
- poprawa opieki zdrowotnej. Branża opieki zdrowotnej znacznie zwiększyła ilość danych pacjentów zebranych z urządzeń, czujników i innego sprzętu medycznego. Ta ogromna ilość danych wymaga zastosowania technologii edge computing do automatyzacji i uczenia maszynowego w celu uzyskania dostępu do danych, ignorowania „normalnych” danych i identyfikacji danych problemowych, aby lekarze mogli podjąć natychmiastowe działania, aby pomóc pacjentom uniknąć incydentów zdrowotnych w czasie rzeczywistym.
- Transport. Pojazdy autonomiczne wymagają i produkują w dowolnym miejscu od 5 TB do 20 TB dziennie, zbierając informacje o lokalizacji, prędkości, stanie pojazdu, warunkach drogowych, warunkach ruchu i innych pojazdach. Dane muszą być agregowane i analizowane w czasie rzeczywistym, gdy pojazd jest w ruchu. Wymaga to znacznego przetwarzania na pokładzie-każdy autonomiczny pojazd staje się „krawędzią”.”Ponadto dane te mogą pomóc władzom i firmom w zarządzaniu flotami pojazdów w oparciu o rzeczywiste warunki w terenie.
- Sprzedaż detaliczna. Firmy detaliczne mogą również generować ogromne ilości danych z nadzoru, śledzenia zapasów, danych sprzedaży i innych szczegółów biznesowych w czasie rzeczywistym. Edge computing może pomóc analizować te różnorodne Dane i identyfikować możliwości biznesowe, takie jak efektywny plan końcowy lub kampania, przewidywać sprzedaż i optymalizować zamówienia dostawców itp. Ponieważ firmy detaliczne mogą się znacznie różnić w lokalnych środowiskach, przetwarzanie brzegowe może być skutecznym rozwiązaniem dla lokalnego przetwarzania w każdym sklepie.
zalety edge computing
Edge computing rozwiązuje istotne problemy infrastrukturalne-takie jak ograniczenia przepustowości, nadmierne opóźnienia i przeciążenie sieci-ale istnieje kilka potencjalnych dodatkowych korzyści dla edge computing, które mogą sprawić, że podejście to będzie atrakcyjne w innych sytuacjach.
Autonomia. Przetwarzanie brzegowe jest przydatne, gdy łączność jest zawodna lub przepustowość jest ograniczona ze względu na charakterystykę środowiska witryny. Przykłady obejmują platformy wiertnicze, statki na morzu, odległe farmy lub inne odległe miejsca, takie jak Las deszczowy lub pustynia. Edge computing wykonuje obliczenia na miejscu – czasami na samym urządzeniu edge – takie jak czujniki jakości wody na oczyszczaczach wody w odległych wioskach i może zapisywać dane do przesyłania do centralnego punktu tylko wtedy, gdy dostępna jest łączność. Przetwarzając dane lokalnie, ilość wysyłanych danych może zostać znacznie zmniejszona, co wymaga znacznie mniejszej przepustowości lub czasu połączenia, niż byłoby to konieczne.
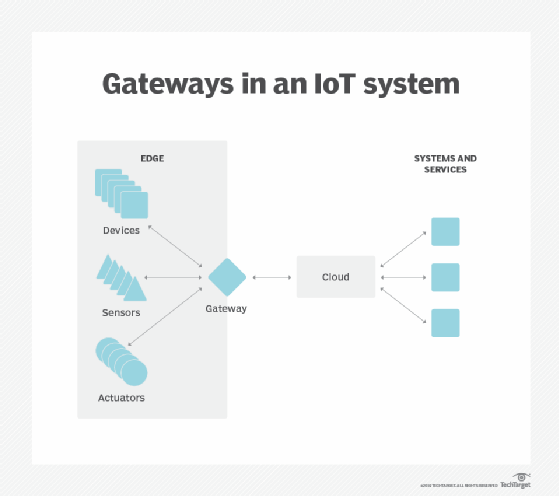
Przenoszenie ogromnych ilości danych to nie tylko problem techniczny. Podróż danych przez granice krajowe i regionalne może stwarzać dodatkowe problemy z bezpieczeństwem danych, prywatnością i innymi kwestiami prawnymi. Edge computing może być używany do przechowywania danych blisko ich źródła i w granicach obowiązujących przepisów dotyczących suwerenności danych, takich jak RODO Unii Europejskiej, które określa, w jaki sposób dane powinny być przechowywane, przetwarzane i ujawniane. Pozwala to na lokalne przetwarzanie nieprzetworzonych danych, zaciemnianie lub zabezpieczanie poufnych danych przed wysłaniem czegokolwiek do chmury lub podstawowego centrum danych, które może znajdować się w innych jurysdykcjach.
Zabezpieczenie krawędzi. Ponadto edge computing oferuje dodatkową możliwość wdrożenia i zapewnienia bezpieczeństwa danych. Chociaż dostawcy usług chmurowych oferują usługi IoT i specjalizują się w kompleksowej analizie, przedsiębiorstwa nadal martwią się o bezpieczeństwo danych po opuszczeniu krawędzi i powrocie do chmury lub centrum danych. Dzięki wdrożeniu przetwarzania w edge wszelkie dane przechodzące przez sieć z powrotem do chmury lub centrum danych można zabezpieczyć za pomocą szyfrowania, a samo wdrożenie edge można zabezpieczyć przed hakerami i innymi złośliwymi działaniami-nawet wtedy, gdy bezpieczeństwo urządzeń IoT pozostaje ograniczone.
wyzwania związane z edge computing
chociaż edge computing ma potencjał, aby zapewnić atrakcyjne korzyści w wielu przypadkach użycia, technologia ta nie jest niezawodna. Oprócz tradycyjnych problemów związanych z ograniczeniami sieci, istnieje kilka kluczowych czynników, które mogą mieć wpływ na przyjęcie obliczeń brzegowych:
- ograniczona zdolność. Część uroku, który cloud computing przynosi do krawędzi — lub mgły — komputerów jest różnorodność i skala zasobów i usług. Wdrożenie infrastruktury na krawędzi może być skuteczne, ale zakres i cel wdrożenia krawędzi musi być jasno określony-nawet rozległe wdrożenie komputerów brzegowych służy konkretnemu celowi w określonej skali przy użyciu ograniczonych zasobów i niewielu usług.
- łączność. Edge computing pokonuje typowe ograniczenia sieciowe, ale nawet najbardziej wyrozumiałe wdrożenie edge będzie wymagało minimalnego poziomu łączności. Kluczowe znaczenie ma zaprojektowanie wdrożenia brzegowego, które zapewnia słabą lub nieregularną łączność, i zastanowienie się, co dzieje się na krawędzi, gdy łączność zostanie utracona. Autonomia, sztuczna inteligencja i płynne planowanie awarii w wyniku problemów z łącznością są niezbędne do skutecznego przetwarzania brzegowego.
- bezpieczeństwo. Urządzenia IoT są często niepewne, dlatego ważne jest zaprojektowanie najnowocześniejszych rozwiązań obliczeniowych, które będą kłaść nacisk na właściwe zarządzanie urządzeniami, takie jak egzekwowanie konfiguracji oparte na zasadach, a także bezpieczeństwo zasobów obliczeniowych i pamięci masowej-w tym czynniki takie jak łatanie oprogramowania i aktualizacje-ze szczególnym uwzględnieniem szyfrowania danych w spoczynku i w locie. Usługi IoT świadczone przez głównych dostawców usług w chmurze obejmują bezpieczną komunikację, ale nie jest to automatyczne podczas tworzenia witryny brzegowej od podstaw.
- cykl życia danych. Odwieczny problem z dzisiejszym glut danych jest to, że tak wiele z tych danych jest niepotrzebne. Rozważmy medyczne urządzenie monitorujące — to tylko dane problemowe są krytyczne, i nie ma sensu trzymać dni normalnych danych pacjentów. Większość danych związanych z analizą w czasie rzeczywistym to dane krótkoterminowe, które nie są przechowywane w dłuższej perspektywie. Firma musi zdecydować, które dane zachować, a które odrzucić po przeprowadzeniu analiz. A przechowywane dane muszą być chronione zgodnie z Polityką biznesową i regulacyjną.
implementacja Edge computing
Edge computing to prosty pomysł, który może wyglądać łatwo na papierze, ale opracowanie spójnej strategii i wdrożenie solidnego wdrożenia na krawędzi może być trudnym ćwiczeniem.
pierwszym istotnym elementem każdego udanego wdrożenia technologii jest stworzenie znaczącej strategii biznesowej i technicznej. Taka strategia nie polega na wybieraniu dostawców lub sprzętu. Zamiast tego, strategia edge uwzględnia potrzebę korzystania z edge computing. Zrozumienie „dlaczego” wymaga jasnego zrozumienia problemów technicznych i biznesowych, które organizacja stara się rozwiązać, takich jak przezwyciężenie ograniczeń sieciowych i przestrzeganie suwerenności danych.

takie strategie mogą rozpocząć się od omówienia tego, co oznacza krawędź, gdzie istnieje dla firmy i jak powinna przynieść korzyści organizacji. Strategie Edge powinny również być zgodne z istniejącymi biznesplanami i mapami drogowymi dotyczącymi technologii. Na przykład, jeśli firma dąży do zmniejszenia scentralizowanego obszaru centrów danych, krawędź i inne rozproszone technologie obliczeniowe mogą się dobrze dopasować.
ponieważ projekt zbliża się do realizacji, ważne jest, aby dokładnie ocenić opcje sprzętu i oprogramowania. Istnieje wielu dostawców w przestrzeni obliczeniowej edge, w tym Adlink Technology, Cisco, Amazon, Dell EMC i HPE. Każda oferta produktów musi zostać oceniona pod kątem kosztów, wydajności, funkcji, interoperacyjności i wsparcia. Z punktu widzenia oprogramowania Narzędzia powinny zapewniać kompleksową widoczność i kontrolę nad zdalnym środowiskiem brzegowym.
rzeczywiste wdrożenie inicjatywy edge computing może się znacznie różnić w zakresie i skali, od lokalnego sprzętu komputerowego w utwardzonej w boju obudowie na szczycie narzędzia do szerokiej gamy czujników zasilających połączenie sieciowe o dużej przepustowości i niskich opóźnieniach z chmurą publiczną. Żadne dwa wdrożenia edge nie są takie same. To właśnie te odmiany sprawiają, że strategia i planowanie edge są tak kluczowe dla sukcesu projektu edge.
wdrożenie edge wymaga kompleksowego monitorowania. Pamiętaj, że przeniesienie personelu IT do fizycznej lokalizacji krawędzi może być trudne, a nawet niemożliwe, więc wdrożenia krawędzi powinny być tak zaprojektowane, aby zapewnić odporność, odporność na awarie i możliwości samoleczenia. Narzędzia do monitorowania muszą oferować jasny przegląd zdalnego wdrażania, umożliwiać łatwą aprowizację i konfigurację, oferować kompleksowe ostrzeganie i raportowanie oraz utrzymywać bezpieczeństwo instalacji i jej danych. Monitorowanie brzegów często obejmuje szereg wskaźników i wskaźników KPI, takich jak dostępność witryny lub czas pracy, wydajność sieci, pojemność i wykorzystanie pamięci masowej oraz zasoby obliczeniowe.
i Żadna implementacja edge nie byłaby kompletna bez starannego rozważenia konserwacji edge:
- bezpieczeństwo. Fizyczne i logiczne środki ostrożności są niezbędne i powinny obejmować narzędzia, które kładą nacisk na zarządzanie lukami w zabezpieczeniach oraz wykrywanie i zapobieganie włamaniom. Bezpieczeństwo musi obejmować Czujniki i urządzenia IoT, ponieważ każde urządzenie jest elementem sieci, do którego można uzyskać dostęp lub zhakować-co przedstawia oszałamiającą liczbę możliwych powierzchni ataku.
- łączność. Inną kwestią jest łączność i należy ustanowić przepisy dotyczące dostępu do kontroli i raportowania, nawet jeśli łączność dla rzeczywistych danych jest niedostępna. Niektóre wdrożenia brzegowe wykorzystują dodatkowe połączenie do tworzenia kopii zapasowych połączeń i sterowania.
- Zarządzanie. Zdalne i często nieprzyjazne lokalizacje wdrożeń brzegowych sprawiają, że zdalne udostępnianie i zarządzanie są niezbędne. Menedżerowie IT muszą być w stanie zobaczyć, co dzieje się na krawędzi i być w stanie kontrolować wdrożenie, gdy jest to konieczne.
- konserwacja fizyczna. Nie można przeoczyć fizycznych wymagań konserwacyjnych. Urządzenia IoT często mają ograniczoną żywotność dzięki rutynowej wymianie baterii i urządzeń. Sprzęt ulega awarii i ostatecznie wymaga konserwacji i wymiany. Praktyczna logistyka witryny musi być uwzględniona w konserwacji.
możliwości Edge computing, IoT i 5G
Edge computing nadal ewoluuje, wykorzystując nowe technologie i praktyki w celu zwiększenia swoich możliwości i wydajności. Być może najbardziej godnym uwagi trendem jest dostępność krawędzi, a usługi krawędzi mają stać się dostępne na całym świecie do 2028 roku. Tam, gdzie przetwarzanie brzegowe jest dziś często specyficzne dla danej sytuacji, oczekuje się, że technologia ta stanie się bardziej wszechobecna i zmieni sposób korzystania z Internetu, przynosząc więcej abstrakcji i potencjalnych przypadków użycia technologii brzegowej.
widać to w rozprzestrzenianiu się produktów obliczeniowych, pamięci masowej i urządzeń sieciowych zaprojektowanych specjalnie dla komputerów brzegowych. Więcej partnerstw multivendor umożliwi lepszą interoperacyjność produktów i elastyczność na krawędzi. Przykładem jest partnerstwo między AWS i Verizon w celu zapewnienia lepszej łączności z siecią brzegową.
technologie komunikacji bezprzewodowej, takie jak 5G i Wi-Fi 6, wpłyną również na wdrażanie i wykorzystanie urządzeń brzegowych w nadchodzących latach, umożliwiając wirtualizację i automatyzację, które jeszcze nie zostały zbadane, takich jak lepsza Autonomia pojazdów i migracja obciążeń do urządzeń brzegowych, a jednocześnie czyniąc Sieci bezprzewodowe bardziej elastycznymi i opłacalnymi.
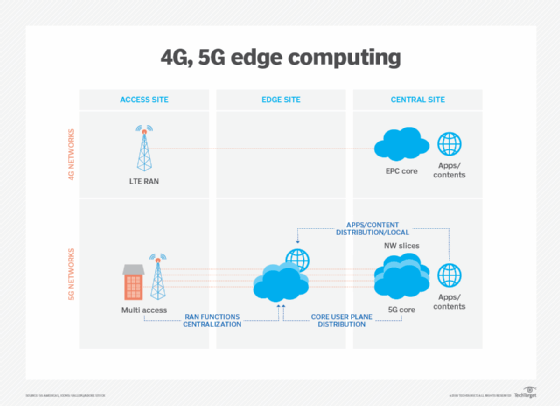
Edge computing zyskało na popularności wraz ze wzrostem IoT i nagłym napływem danych wytwarzanych przez takie urządzenia. Ale ponieważ technologie IoT wciąż są w powijakach, ewolucja urządzeń IoT będzie miała również wpływ na przyszły rozwój technologii edge computing. Przykładem takich przyszłych alternatyw jest rozwój mikromodułowych centrów danych (MMDC). MMDC jest w zasadzie centrum danych w pudełku, umieszczając kompletne centrum danych w małym mobilnym systemie, który może być wdrożony bliżej danych-na przykład w mieście lub regionie-aby uzyskać znacznie bliżej danych bez stawiania przewagi nad danymi.