変化率
線形関数は、一定の速度を含む現実世界の問題に適用されます。
学習目標
変化率に関する問題を解決するために線形方程式を適用する
キーテイクアウト
キーポイント
- 実世界の問題が線形であることがわかっている場合は、ジョグに行くときの移動距離など、関数をグラフ化し、二つの点だけでいくつかの仮定を行うことができます。
- 関数の傾きは、従属変数(y)の変化率と同じです。 たとえば、距離と時間をグラフ化している場合、傾きは時間とともに距離がどのくらい速く変化するか、つまり速度です。
主要な用語
- 変化率:変化している2つの関連する量の間の比率。
- 線形方程式:最初の次数の多項式(x=2y-7など)。
- 勾配:線上の二つの点間の垂直方向と水平方向の距離の比; ラインが水平の場合はゼロ、垂直の場合は未定義です。
変化率
線形方程式には、多くの場合、変化率が含まれています。 たとえば、距離が時間の経過とともに変化する速度は速度と呼ばれます。 時間の2つのポイントと総移動距離が知られている場合、変化率(勾配としても知られています)を決定することができます。 この情報から、線形方程式を記述することができ、その後、予測は、ラインの方程式から行うことができます。
何かが変化している単位または量が指定されていない場合、通常、レートは単位時間あたりです。 最も一般的なタイプの速度は、速度、心拍数、フラックスなどの「単位時間あたり」です。 非時間分母を持つ比率には、為替レート、識字率、および電界(ボルト/メートル単位)が含まれます。
レートの単位を記述する際に、単語”あたり”は、レートを計算するために使用される二つの測定値の単位を分離するために使用されます(例えば、心拍数は”分
変化率: 現実の世界のアプリケーション
アスリートは、夕方の間に次のマラソンのために彼は通常の練習を開始します。 6:00pmに彼は走り始め、彼の家を出る。 午後7時30分、競技者は自宅で走りを終え、合計7.5マイルを走った。 ランの過程で彼の平均速度はどのくらい速かったですか?
変化の速度は、彼の実行の速度です。 したがって、2つの変数は時間(x)と距離(y)です。 最初のポイントは、彼の時計が午後6:00を読んだ彼の家です。 これは開始時間ですので、0に設定しましょう。 彼はまだどこにも走っていなかったので、私たちの最初のポイントは(0,0)です。 時間で私たちの時間について考えてみましょう。 私たちの第二のポイントは1.5時間後であり、私たちは7.5マイルを走った。 2番目のポイントは(1.5,7.5)です。 私たちの速度(変化率)は、単に2つの点を結ぶ線の傾きです。 次のように与えられる勾配:m=\frac{y_{2}-y_{1}}{x_{2}-x_{1}}は、m=\frac{7.5}{1.5}=5マイル/時になります。
例:速度を示す線をグラフ化
この線をグラフ化するには、y切片と方程式を書くための傾きが必要です。 勾配は時速5マイルであり、出発点は(0,0)であったため、y切片は0である。 したがって、最終関数はy=5xです。
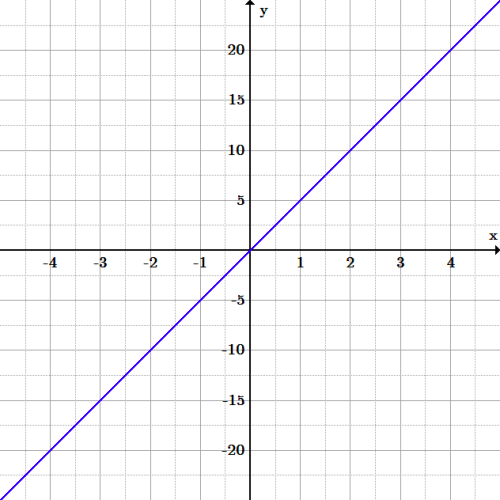
距離と時間のグラフ:y=5xのグラフ。 ランナーが走る速度は時速5マイルです。 グラフを使用して、彼の平均速度が同じままであると仮定して予測を行うことができます。この新しい関数を使用すると、さらにいくつかの質問に答えることができます。
- 彼は最初の30分後に何マイル走ったのですか? 方程式を使用して、x=\frac{1}{2}の場合、yを解きます。y=5xの場合、y=5(0.5)=2.5マイルです。
- 彼は3時間の合計のために同じペースで実行し続けた場合、どのように多くのマイルを実行しているのだろうか? X=3の場合、yを解きます。y=5xの場合、y=5(3)=15マイルです。
線形方程式のための多くのそのようなアプリケーションがあります。 一定の変化率を伴うものは、傾きを持つ線でうまく表すことができます。 実際、2つの点がある限り、関数が線形であることがわかっている場合は、それをグラフ化して質問を開始できます! ただ、あなたが求めていることを確認し、グラフ化は理にかなっています。 たとえば、マラソンの例では、負の時間に入ってマイルを失うことは意味がないので、ドメインは実際にはx\geq0だけです!
線形数学モデル
線形数学モデルは、実世界のアプリケーションを線で記述します。
学習目標
線形数学モデルを現実世界の問題に適用する
キーテイクアウト
キーポイント
- 数学モデルは、数学的概念と言語
- 線形数学モデルは線で記述することができます。 たとえば、時速50マイルで走行する車は、y=50xで表される距離を移動しました。xは時間単位の時間で、yはマイルです。 方程式とグラフは、予測を行うために使用することができます。
- 実世界のアプリケーションは、二つの列車が互いに向かって移動する場合など、複数の線でモデル化することもできます。 二つの線が交差する点は、列車が出会う点です。
Key Terms
- mathematical model:プロセス、デバイス、または概念の抽象的な数学的表現;入力、出力、内部状態、およびそれらの相互作用を記述する方程式と不等式
- 線形回帰: 従属変数yと独立変数xの間の線形関係をモデル化するアプローチ。
数学モデル
数学モデルは、数学的概念と言語を使用したシステムの 数学モデルは、自然科学や工学分野だけでなく、社会科学でも使用されています。 線形モデリングには、人口の変化、電話料金、自転車のレンタルコスト、体重管理、または資金調達が含まれます。 線形モデルには、変化率(m)と初期量であるy切片bが含まれます。 モデルが記述され、線のグラフが作成された後、いずれかを使用して行動に関する予測を行うことができます。
実生活線形モデル
多くの日常の活動は、おそらく無意識のうちに、数学的モデルの使用を必要とします。 数学モデルの難しさの1つは、現実世界のアプリケーションを正確な数学的表現に変換することにあります。
例:移動バンを借りる
レンタル会社は、移動バンを借りるためにマイルあたり30ドルの定額料金と追加の0.25ドルを請求します。 駆動マイル数であるxの観点から、コストy(ドル)を近似する線形方程式を記述します。 75マイルの旅行はどのくらいの費用がかかりますか?
\displaystyle y=mx+b
総コストは、マイルあたりのレートに運転マイル数に定額料金のコストを加えたものに等しいです。
\displaystyle y=0.25x+30
75マイル旅行のコストを計算するには、xを75に代入してください。方程式:=0.25x+30\\&=0.25x+30\\&
\displaystyle\begin{align}y&=0.25x+30\\&&&=48.75\end{align}
複数の方程式を持つ実生活モデル
複数の行とその方程式をモデル化することも可能です。
例
最初は、列車Aとbは互いに325マイル離れています。 列車Aは時速50マイルでBに向かって走行しており、列車Bは時速80マイルでAに向かって走行しています。 2つの列車は何時に会うのですか? この時点で、列車はどこまで移動しましたか?
まず、列車の開始位置(y-intercepts、b)から始めます。 列車Aの開始は原点であり、(0,0)。 列車Bは最初は列車Aから325マイル離れているので、その位置は(0,325)です。第二に、各列車の総距離を時間で表す方程式を書くために、各列車の変化率を計算します。
次に、各列車の変化率を計算します。
次に、各列車の変化率 列車Aはより大きなy値を持つ列車Bに向かって移動しているため、列車Aの変化率は正であり、その速度50に等しくなければなりません。 列車Bはaに向かって移動しており、y値が小さく、Bに負の変化率:-80が与えられます。したがって、二つの線は次のようになります。
\displaystyle y_a=50x\\
そして:
\displaystyle y_b=−80x+325
二つの列車は、二つの線が交差するところで出会うでしょう。 2つの線が交差する場所を見つけるには、方程式を互いに等しく設定し、xを解く:
\displaystyle y_{A}=y_{B}
\displaystyle50x=-80x+325
xを解くと、
\displaystyle x=2.5
2つの列車は2.5時間後に出会う。 これがどこにあるかを見つけるには、2.5をいずれかの式に差し込みます。最初の方程式に差し込むと、50(2.5)=125となり、125マイル移動した後に出会うことを意味します。
ここでは、二つの列車の距離対時間グラフィックモデルです:

列車:列車A(赤線)は式で表されます:y=50x、列車B(青線)は式で表されます:y=-80x+325。 二つの列車は交差点ポイント(2.5、125)で会い、125マイルの後に2.5時間である。
曲線を近似する
曲線を線で近似すると、すべてのデータに”最もよく適合する”ように線を描画しようとします。
学習目標
最小二乗回帰式を使用して、一連の点の最適な直線を計算します
キーテイクアウト
キーポイント
- 曲線近似は、データに最 これにより、データがどのように大まかに分散されているかについての仮定と将来のデータポイントについての予測が可能になります。
- 線形回帰は、データに最も適した線をグラフ化しようとします。
- 通常の最小二乗近似は、近似値(ラインから)と実際の値との差の二乗の合計を最小化する線形回帰の一種です。
- n個のデータ点を近似する線の傾きは、次式で与えられますm=\frac{\sum_{i=1}^{n}x_{i}y_{i}-\frac{1}{n}\sum_{i=1}^{n}x_{i}\sum_{j=1}^{n}y_{j}}{\sum_{i=1}^{n}(x_{i}^{2})-\frac{1}{n}(\sum_{i=1}^{n}x_{i})^{2}}.
- n個のデータ点を近似する線のy切片は、次式で与えられます。
- n個のデータ点を近似する線のy切片: b=\displaystyle{\frac{1}{n}\sum_{i=1}y{n}y_{1}-m\frac{1}{n}\sum_{i=1}x{n}x_{i}=\left(\bar{y}-m\bar{x}\right)}
キー用語
- 曲線近似:一連の曲線に最適な曲線、または数学関数制約の対象となる可能性のあるデータポイント。
- 外れ値:パターンに適合せず、他のほとんどのデータポイントを記述しない統計サンプル内の値。
- 最小二乗近似:予測点と実際の点との間の二乗距離の合計を最小化しようとする試み。
- 線形回帰:従属変数yと独立変数xとの間の線形関係をモデル化するアプローチ。
曲線近似
曲線近似は、おそらく制約の対象となる一連のデー 曲線近似には、データへの正確な近似が必要な補間、またはデータに近似する”滑らかな”関数が構築される平滑化のいずれかが含まれます。 近似曲線は、データの視覚化、データが利用できない関数の値の推測、および2つ以上の変数間の関係の要約のための補助として使用できます。 外挿とは、観測されたデータの範囲を超えた近似曲線の使用を指し、観測されたデータを反映するのと同じくらい曲線を構築するために使用される方法を反映する可能性があるため、より大きな不確実性の対象となります。
このセクションでは、データ点に線を当てはめるだけですが、多項式関数、円、ピース単位の関数、および任意の数の関数をデータに当てはめることができ、統計学で頻繁に使用されるトピックであることに注意する必要があります。
線形回帰式
線形回帰は、従属変数yと独立変数xとの間の線形関係をモデル化するアプローチです。
最も単純でおそらく最も一般的な線形回帰モデルは、通常の最小二乗近似です。 この近似は、線とすべての点との間の二乗距離の合計を最小化しようとします。
\displaystyle m=\frac{\sum_{i=1}^{n}x_{i}y_{i}-\frac{1}{n}\sum_{i=1}^{n}x_{i}\sum_{j=1}^{n}y_{j}}{\sum_{i=1}^{n}(x_{i}^{2})-\frac{1}{n}(\sum_{i=1}^{n}x_{i})^{2}}pここで、best sum_{i=1}x{n}x_{i}y_{i}coordinatesは、\sum_{i=1}x{n}x_{i}y_{i}coordinatesとproduct sum_{i=1}x{n}x_{i}y_{i}coordinatesとproduct sum_{i=1}x{n}x_{i}y_{i}coordinatesとproduct sum_{i=1}x{n}x_{i}y_{i}coordinatesとの積の和です。x座標\sum_{i=1}^{n}x_{i}の合計です。y座標\sum_{j=1}^{n}y_{j}の合計。x座標\sum_{i=1}^{n}(x_{i}^{2})の二乗の和。x座標の二乗和(\sum_{i=1}x{n}x_{i}){{2}。
- y座標の平均。 Y-barと発音される\bar{y}は、すべてのデータポイントの平均(または平均)y値を表します。\bar y=\frac{1}{n}\sum_{i=1}.{n}y_{i}。
- x座標の平均。 それぞれ、x-barと発音される\bar{x}は、すべてのデータポイントの平均(または平均)x値です。\bar x=\frac{1}{n}\sum_{i=1}^{n}x_{i}。値を上記の式に置き換えますb=\bar{y}-m\bar{x}。
これらのmとbの値を使用して、グラフ上の点を近似する線が得られました。
例:最小二乗近似線を記述し、データに最もよく適合する線をグラフ化します
N=8点について: (-1,0),(0,0),(1,1),(2,2),(3,1),(4,2.5),(5,3) と(6,4)。p>
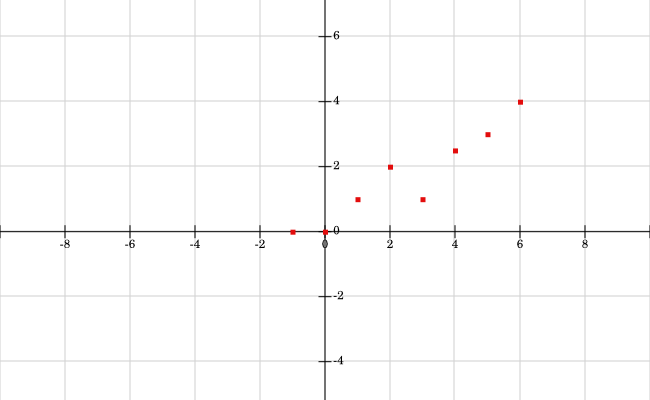
ポイントの例:ポイントは散布図でグラフ化されます。まず、前のセクションの方程式を使用して、このデータを最も近似する勾配(m)とy切片(b)を見つけます。
勾配を見つけるには、次を計算します。
- xとy座標\sum_{i=1}^{n}x_{i}y_{i}。x座標\sum_{i=1}^{n}x_{i}の合計です。y座標\sum_{i=1}^{n}y_{i}の合計。
\displaystyle \begin{align} \sum_{i=1}^{n}x_{i}y_{i}&&=57 \end{align} \displaystyle \begin{align} \sum_{i=1}^{n}x_{i}&&=20 \end{align}\displaystyle \begin{align} \sum_{i=1}^{n}y_{i}&&=13.5\end{align}
\displaystyle m=\frac{\sum_{i=1}^{n}x_{i}y_{i}-\frac{1}{n}\sum_{i=1}^{n}x_{i}\sum_{j=1}^{n}y_{j}}{\sum_{i=1}^{n}(x_{i}^{2})-\frac{1}{n}(\sum_{i=1}^{n}x_{i})^{2}}
4. Numer sum_{i=1}x{n}x_{i}y_{i}-\frac{1}{n}\sum_{i=1}x{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}x_{i}\sum_{j=1}y{n}y_{j}\frac{1}{n}勾配方程式の分子は次のとおりです。
\displaystyle57-\frac{1}{8}(20)(13.5)=23.25
5. 分母を計算する: X sum_{i=1}x{n}(x_{i}x{2})-\frac{1}{n}(\sum_{i=1}x{n}x_{i})){2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{2})begin{2}\frac{1}{n}(x_{i}x{これを行うには、次の手順を実行します。>=1+0+1+4+9+16+25+36\\&=92\end{align}
分母は92-\fracです{1}{8}(20)^{2}=92-50=42 そして、傾きは分子と分母の商です:\frac{23.25}{42}\approx0.554。ここで、y切片については、(b)x座標の平均を8倍にします。\bar{x}=\frac{20}{8}=2。5とy座標の平均の八倍:\バー{y}=\frac{13.5}{8}=1.6875。したがって、b=\frac{1}{n}\sum_{i=1}^{n}y_{1}-m\frac{1}{n}\sum_{i=1}^{n}x_{i}\:
\displaystyle b\approx1\frac{1}{n}\sum_{i=1}^{n}x_{i}\:
\displaystyle b=\frac{1}{n}\sum_{i=1}^{n}x_{i}\:
\displaystyle b\approx1\:
.6875-0.554(2.5)=0.3025.したがって、最終的な方程式はy=0.554x+0.3025であり、この線は点とともにグラフ化されます。
したがって、最後の方程式はy=0.554x+0.3025であり、この線は点と一緒にグラフ化されます。
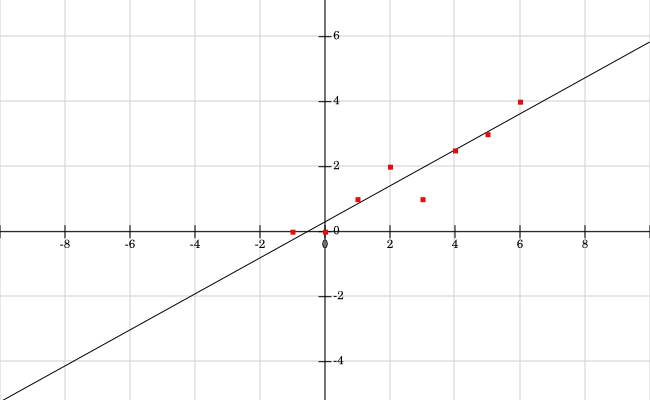
最小二乗法近似線
最小二乗法近似: 最小二乗近似によって求められる線は、y=0.554x+0.3025です。 4点が線の上にあり、4点が線の下にあることに注意してください。
外れ値と最小二乗回帰
近似線から遠く離れた点がある場合、結果が歪められ、線がはるかに悪化します。 たとえば、元の例では、ポイント(-1,0)の代わりに(-1,6)があるとしましょう。新しい点で上記と同じ計算を使用すると、結果は次のようになります。m\approx0.0536およびb\approx2.3035、新しい方程式y=0.0536x+2.3035を取得します。下の新しい図の点と線を見ると、この新しい線は外れ値(-1,6)のためにデータにうまく適合しません。 実際、線形モデルを二次、三次、または非線形のデータ、または外れ値や誤差が多いデータに適合させようとすると、近似が悪くなる可能性があります。
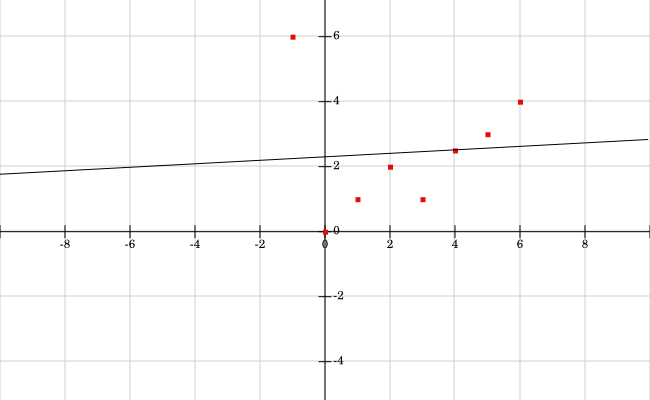
div