エッジコンピューティングは、クライアントデータが可能な限り元のソースに近いネットワークの周辺で処理される分散情報技術(IT)アーキテクチャです。
データは現代のビジネスの生命線であり、貴重なビジネス洞察を提供し、重要なビジネスプロセスと運用をリアルタイムで制御するのをサポートし 今日のビジネスは、データの海にあふれており、膨大な量のデータは、世界中のほぼどこでも遠隔地や無愛想な動作環境からリアルタイムで動作するセン
しかし、データのこの仮想洪水はまた、企業がコンピューティングを処理する方法を変更しています。 集中化されたデータセンターと日常のインターネット上に構築された従来のコンピューティングパラダイムは、無限に成長する現実世界のデータの川を移動するのには適していません。 帯域幅の制限、レイテンシの問題、予測不可能なネットワークの中断は、すべてこのような努力を損なうために共謀する可能性があります。 企業は、エッジコンピューティングアーキテクチャを使用して、これらのデータの課題に対応しています。
簡単に言えば、エッジコンピューティングは、ストレージとコンピューティングリソースの一部を中央のデータセンターから移動し、データ自体のソースに近 処理と分析のために生データを中央のデータセンターに送信するのではなく、その作業は、小売店、工場フロア、広大なユーティリティ、またはスマートシティに リアルタイムのビジネス洞察、機器メンテナンスの予測、その他の実用的な回答など、エッジでのコンピューティング作業の結果のみが、レビューやその他の人間の相互作用のためにメインデータセンターに送り返されます。
したがって、エッジコンピューティングはITとビジネスコンピューティングを再形成しています。 エッジコンピューティングとは何か、その仕組み、クラウドの影響、エッジのユースケース、トレードオフ、実装の考慮事項を包括的に見てみましょう。
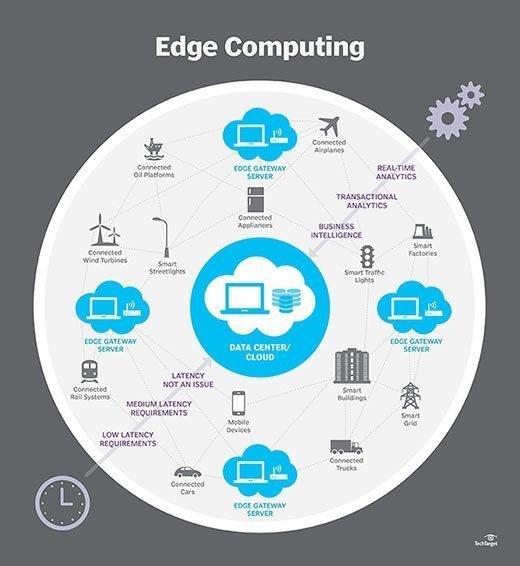
エッジコンピューティングはどのように機能しますか?
エッジコンピューティングは、すべての場所の問題です。 従来のエンタープライズコンピューティングでは、データはユーザーのコンピュータなどのクライアントエンドポイントで生成されます。 このデータは、インターネットなどのWANを介して企業LANを介して移動され、企業アプリケーションによってデータが格納され、処理されます。 その後、その作業の結果がクライアントエンドポイントに返されます。 これは、ほとんどの一般的なビジネスアプリケーションのためのクライアントサーバコンピューティングに実証され、時の試練を経たアプローチのままです。
しかし、インターネットに接続されたデバイスの数、およびそれらのデバイスによって生成され、企業によって使用されるデータの量は、従来のデータセ ガートナーは、2025年までに、企業で生成されたデータの75%が集中型データセンターの外部で作成されると予測しています。 多くの場合、時間や混乱に敏感な状況で非常に多くのデータを移動する見通しは、それ自体が輻輳や混乱の対象となることが多いグローバルインターネット
そのため、ITアーキテクトは、中央のデータセンターからインフラストラクチャの論理エッジに焦点を移し、データセンターからストレージとコンピューティングリソースを取得し、それらのリソースをデータが生成されるポイントに移動しました。 データをデータセンターに近づけることができない場合は、データセンターをデータに近づけることができます。 エッジコンピューティングの概念は新しいものではなく、リモートオフィスやブランチオフィスなどのリモートコンピューティングの数十年前のアイデアに根ざしており、単一の中央の場所に依存するのではなく、コンピューティングリソースを所望の場所に配置する方が信頼性が高く効率的であった。

エッジコンピューティングは、多くの場合、ローカルでデータを収集し、処理するために、リモートLAN上で動作するようにギアの部分的なラッ 多くの場合、計算ギヤは保護されるか、または堅くされたエンクロージャで温度、湿気および他の環境条件の極端からギヤを保護するために配置され 多くの場合、データストリームを正規化して分析してビジネスインテリジェンスを検索し、分析の結果のみがプリンシパルデータセンターに送り返されます。
ビジネスインテリジェンスの考え方は劇的に変化する可能性があります。 例としては、ショールームフロアのビデオ監視を実際の販売データと組み合わせて、最も望ましい製品構成や消費者の需要を判断する小売環境があります。 その他の例には、実際の欠陥や故障が発生する前に機器のメンテナンスや修理を導くことができる予測分析が含まれています。 さらに他の例は、装置が適切に機能していることを保証し、出力の品質を維持するために、水処理や発電などの公益事業と調整されることが多い。
エッジ対クラウド対 fog computing
エッジコンピューティングは、クラウドコンピューティングとfogコンピューティングの概念と密接に関連しています。 これらの概念の間にはいくつかの重複がありますが、それらは同じものではなく、一般的に交換可能に使用すべきではありません。 概念を比較し、その違いを理解することは役に立ちます。
エッジ、クラウド、フォグコンピューティングの違いを理解する最も簡単な方法の一つは、彼らの共通のテーマを強調することです: 3つの概念はすべて分散コンピューティングに関連しており、生成されているデータに関連して計算リソースとストレージリソースの物理的な展開に焦点を当てています。 違いは、それらのリソースがどこにあるかの問題です。
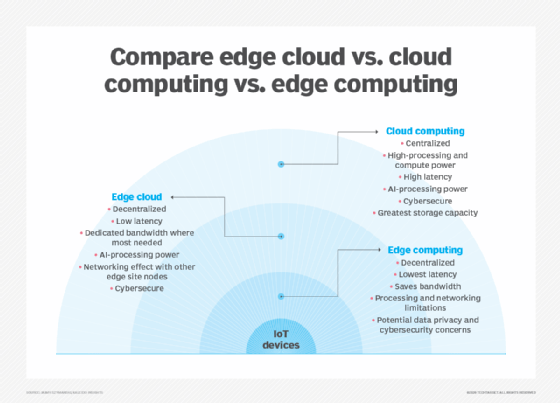
エッジ。 エッジコンピューティングとは、データが生成される場所にコンピューティングとストレージリソースを展開することです。 これにより、理想的には、計算とストレージはネットワークエッジのデータソースと同じポイントに配置されます。 たとえば、複数のサーバーとストレージを備えた小さなエンクロージャを風力タービンの上に設置して、タービン自体内のセンサーによって生成されたデータを収集して処理することができます。 別の例として、鉄道駅は、無数の軌道および鉄道交通センサーデータを収集および処理するために、駅内に適度な量の計算およびストレージを配置するこ そのような処理の結果は、人間のレビュー、アーカイブのために別のデータセンターに送り返され、より広範な分析のために他のデータ結果とマージされます。
クラウド。 クラウドコンピューティングは、いくつかの分散されたグローバルロケーション(リージョン)のいずれかで、コンピュー クラウドプロバイダーは、IoT運用のための事前パッケージ化されたサービスの品揃えも組み込まれているため、クラウドはIoT展開のための優先される集中型プラットフォームになります。 しかし、クラウドコンピューティングは、複雑な分析に取り組むのに十分なリソースとサービスをはるかに提供していますが、最も近い地域のクラウド施設は、データが収集された地点から数百マイル離れている可能性があり、接続は従来のデータセンターをサポートするのと同じ気質のあるインターネット接続に依存しています。 実際には、クラウドコンピューティングは、従来のデータセンターの代替、または時には補完的なものです。 クラウドは、データソースにはるかに近い集中型コンピューティングを得ることができますが、ネットワー
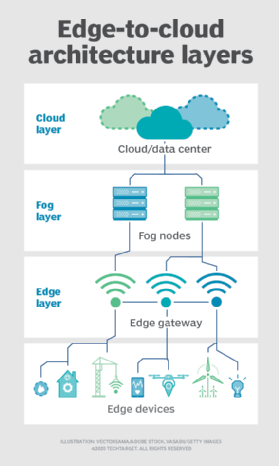
フォグ。 しかし、コンピューティングとストレージの展開の選択は、クラウドやエッジに限定されません。 クラウドデータセンターは遠すぎるかもしれませんが、エッジの展開は、厳密なエッジコンピューティングを実用的にするには、リソースが制限されていたり、物理的に分散されていたり、分散されていたりする可能性があります。 この場合、フォグコンピューティングの概念が役立ちます。 Fogコンピューティングは、通常、一歩後退し、計算リソースとストレージリソースをデータ内に配置しますが、必ずしもデータの”位置”に配置するとは限りません。
Fogコンピューティング環境は、エッジを定義するには大きすぎる広大な物理領域にわたって生成されるセンサーまたはIoTデータの途方もない量を生 例はスマートな建物、スマートな都市またはスマートな実用的な格子を含んでいる。 データを使用して、公共交通システム、地方自治体の公益事業、都市サービスを追跡、分析、最適化し、長期的な都市計画を導くことができるスマートシティを考 単一のエッジ展開では、このような負荷を処理するだけでは不十分なため、fogコンピューティングは、環境の範囲内で一連のfogノード展開を操作して、データを収集、処理、分析することができます。
注:fog computingとedge computingはほぼ同じ定義とアーキテクチャを共有しており、この用語は技術専門家の間でも互換的に使用されることがあります。
なぜエッジコンピューティングは重要なのですか?
コンピューティングタスクには適切なアーキテクチャが必要であり、あるタイプのコンピューティングタスクに適したアーキテクチャは必ずしもすべ エッジコンピューティングは、分散コンピューティングをサポートする実行可能で重要なアーキテクチャとして浮上しており、理想的にはデータソースと同じ物理的な場所にコンピューティングとストレージリソースを配置することができます。 一般的に、分散コンピューティングモデルはほとんど新しいものではなく、リモートオフィス、ブランチオフィス、データセンターのコロケーション、クラウドコンピューティングの概念は長く実証された実績を持っています。
しかし、分散化は困難であり、従来の集中型コンピューティングモデルから離れるときに見落とされがちな高レベルの監視と制御を要求します。 エッジコンピューティングは、今日の組織が生産し、消費する膨大な量のデータを移動することに関連する新たなネットワーク問題に対する効果的なソリ それは量の問題だけではありません。 また、時間の問題であり、アプリケーションはますます時間に敏感な処理と応答に依存しています。
自己駆動車の台頭を考えてみましょう。 彼らはインテリジェントな交通管制信号に依存します。 自動車や交通規制は、リアルタイムでデータを生成、分析、交換する必要があります。 この要件に膨大な数の自律走行車を掛け合わせると、潜在的な問題の範囲がより明確になります。 これには、高速で応答性の高いネットワークが必要です。 Edge–とfog–コンピューティングは、三つの主要なネットワークの制限に対処します: 帯域幅、待ち時間および混雑または信頼性。
- 帯域幅。 帯域幅は、ネットワークが時間をかけて運ぶことができるデータの量であり、通常は毎秒ビットで表されます。 すべてのネットワークには帯域幅が限られており、無線通信の制限はより厳しいものです。 これは、ネットワークを介してデータを通信できるデータの量またはデバイスの数には有限の制限があることを意味します。 より多くのデバイスとデータに対応するためにネットワーク帯域幅を増やすことは可能ですが、コストは大きくなる可能性があり、まだ(より高い)有限
- レイテンシ。 レイテンシとは、ネットワーク上の2つのポイント間でデータを送信するのに必要な時間です。 通信は理想的には光の速度で行われますが、ネットワークの輻輳や停止と相まって、物理的な距離が大きいと、ネットワーク全体のデータ移動が遅れる可能性があります。 これにより、分析と意思決定プロセスが遅延し、システムがリアルタイムで応答する能力が低下します。 自動運転車の例では、コストの命さえもかかっています。
- 輻輳。 インターネットは基本的にグローバルな”ネットワークのネットワークです。”ファイル交換や基本的なストリーミングなど、日常のほとんどのコンピューティングタスクに対して優れた汎用データ交換を提供するように進化しましたが、数千億のデバイスに関連するデータ量はインターネットを圧倒し、高レベルの輻輳を引き起こし、時間のかかるデータの再送信を余儀なくされます。 他のケースでは、ネットワークの停止は輻輳を悪化させ、一部のインターネットユーザーとの通信を完全に切断する可能性があります。
データが生成されるサーバーとストレージを展開することにより、エッジコンピューティングは、ローカルデータ生成デバイスによって排他的に十分な帯域幅が使用されるはるかに小さく、より効率的なLAN上で多くのデバイスを動作させることができ、レイテンシと輻輳を事実上存在させない。 ローカルストレージは生データを収集して保護しますが、ローカルサーバーは本質的なエッジ分析を実行したり、少なくともデータを前処理して削減したりして、結果をクラウドまたは中央データセンターに送信する前にリアルタイムで意思決定を行うことができます。
エッジコンピューティングユースケースと例
基本的に、エッジコンピューティング技術は、ネットワークエッジまたはその近くでデータを”インプレース”で収集、フィルタリング、処理、分析するために使用されます。 これは、最初に集中管理された場所に移動することができないデータを使用する強力な手段です-通常、膨大な量のデータがそのような移動をコスト法外、技術的に非現実的にしたり、データ主権などのコンプライアンス義務に違反する可能性があるためです。 この定義は、無数の実世界の例とユースケースを生み出しました:
- 製造。 ある産業メーカーは、製造を監視するためにエッジコンピューティングを導入し、エッジでリアルタイムの分析と機械学習を可能にして、生産エラーを見つけ エッジコンピューティングは、製造工場全体に環境センサーを追加することをサポートし、各製品コンポーネントがどのように組み立てられ、保管されているか、またコンポーネントがどのくらい在庫に残っているかについての洞察を提供しました。 製造業者は今工場設備および製造作業に関するより速く、より正確なビジネス決定をすることができる。
- 農業。 日光、土または殺虫剤なしで穀物を屋内で育てるビジネスを考慮しなさい。 このプロセスは、成長時間を60%以上短縮します。 センサーを使用することで、水の使用量、栄養密度を追跡し、最適な収穫量を決定することができます。 データが収集され、環境要因の影響を見つけ、継続的に作物の成長アルゴリズムを改善し、作物がピーク状態で収穫されていることを確認するために分析
- ネットワークの最適化。 エッジコンピューティングは、インターネット上のユーザーのパフォーマンスを測定し、分析を使用して、各ユーザーのトラフィックに対して最も信頼性の高い低レイテンシのネットワークパスを決定することにより、ネットワークパフォーマンスを最適化するのに役立ちます。 実際には、エッジコンピューティングは、最適な時間に敏感なトラフィックパフォーマンスのためにネットワーク上のトラフィッ
- 職場の安全。 エッジコンピューティングは、現場のカメラ、従業員の安全装置、その他のさまざまなセンサーからのデータを組み合わせて分析し、職場の状況を監督したり、従業員が確立された安全プロトコルに従うことを保証したりするのに役立ちます。特に、職場が遠く離れている場合や、建設現場や石油リグなどの異常に危険な場合。
- 改善された医療。 ヘルスケア業界は、デバイス、センサー、その他の医療機器から収集される患者データの量を劇的に拡大しています。 その膨大なデータ量には、自動化と機械学習を適用してデータにアクセスし、”通常の”データを無視し、問題データを特定するためのエッジコンピューティングが必
- 交通。 自動運転車は、場所、速度、車両の状態、道路状況、交通状況、およびその他の車両に関する情報を収集し、1日あたり5TBから20TBの場所を必要とし、生産し また、車両が動いている間に、データをリアルタイムで集計して分析する必要があります。 これは重要な機内計算を要求する–各自律車は”端になる。 さらに、このデータは、当局や企業が現場の実際の状況に基づいて車両艦隊を管理するのに役立ちます。
- 小売。 小売業はまた、監視、在庫追跡、販売データ、およびその他のリアルタイムのビジネス詳細から膨大なデータ量を生成することができます。 エッジコンピューティングは、このような多様なデータを分析し、効果的なエンドキャップやキャンペーンなどのビジネス機会を特定し、販売を予測し、ベンダーオーダーを最適化するのに役立ちます。 小売業はローカル環境で劇的に変化する可能性があるため、エッジコンピューティングは各店舗でのローカル処理に効果的なソリ
エッジコンピューティングの利点
エッジコンピューティングは、帯域幅の制限、過剰なレイテンシ、ネットワーク輻輳などの重要なインフ
自律性。 エッジコンピューティングは、接続性が信頼できない場合や、サイトの環境特性のために帯域幅が制限されている場合に便利です。 例としては、石油掘削装置、海上の船、遠隔農場、または熱帯雨林や砂漠などの他の遠隔地などがあります。 エッジコンピューティングは、遠隔地の村の浄水器の水質センサーなど、現場で計算作業を行い、接続が利用可能な場合にのみデータを保存して中心点に送信することができます。 データをローカルで処理することにより、送信されるデータの量を大幅に削減でき、必要な帯域幅や接続時間が必要な場合よりもはるかに少なくなります。
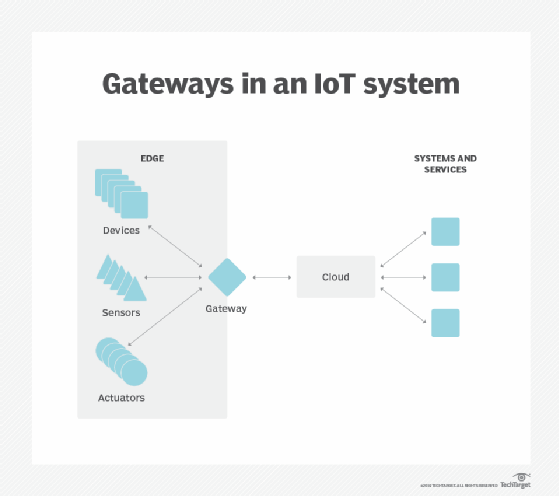
データ主権。 膨大な量のデータを移動することは、単なる技術的な問題ではありません。 国や地域の境界を越えたデータの旅は、データセキュリティ、プライバシー、その他の法的問題に追加の問題をもたらす可能性があります。 エッジコンピューティングを使用すると、データをソースに近く、データの保存、処理、公開方法を定義する欧州連合のGDPRなどの現行のデータ主権法の範囲内に保 これにより、生データをローカルで処理し、機密データを隠したり保護したりしてから、クラウドやプライマリデータセンターに送信することができます。
エッジセキュリティ。 最後に、エッジコンピューティングは、データセキュリティを実装し、確保するための追加の機会を提供します。 クラウドプロバイダーはIoTサービスを持ち、複雑な分析に特化していますが、企業はデータがエッジを離れてクラウドやデータセンターに戻った後も、データの安全性とセキュリティを懸念し続けています。 エッジでコンピューティングを実装することにより、ネットワークを通過してクラウドまたはデータセンターに戻ってくるデータは暗号化によって保護され、IoTデバイスのセキュリティが制限されたままであっても、エッジ展開自体はハッカーやその他の悪意のある活動に対して強化することができます。
エッジコンピューティングの課題
エッジコンピューティングは、多くのユースケースにわたって魅力的な利点を提供する可能性を秘めていますが、この技術は絶対的なものではありません。 従来のネットワーク制限の問題以外にも、エッジコンピューティングの採用に影響を与える可能性のあるいくつかの重要な考慮事項があります。
- 制限された機能。 クラウドコンピューティングがエッジまたはフォグにもたらす魅力の一部は、リソースとサービスの多様性と規模です。 大規模なエッジコンピューティングの展開であっても、限られたリソースと少数のサービスを使用して、事前に決定された規模で特定の目的を果たします。
- 接続性。 エッジコンピューティングは、一般的なネットワークの制限を克服しますが、最も寛容なエッジ展開でさえ、最小限の接続レベルが必要です。 接続が不十分または不安定な状態に対応するエッジ展開を設計し、接続が失われたときにエッジで何が起こるかを検討することが重要です。 エッジコンピューティングを成功させるためには、自律性、AI、接続性の問題をきっかけにした優雅な障害計画が不可欠です。
- セキュリティ。 IoTデバイスは安全ではないことが知られているため、ポリシー駆動型の構成の強制などの適切なデバイス管理、ソフトウェアのパッチ適用や更新などの要因を含むコンピューティングリソースとストレージリソースのセキュリティを重視するエッジコンピューティングの展開を設計することが重要です。 主要なクラウドプロバイダーのIoTサービスには安全な通信が含まれていますが、エッジサイトをゼロから構築するときには自動ではありません。
- データライフサイクル。 今日のデータ供給過剰の多年生の問題は、そのデータの多くが不要であるということです。 医療監視装置を考えてみましょう-それは重要な問題データだけであり、通常の患者データの日数を維持することにはほとんど意味がありません。 リアルタイム分析に関連するデータのほとんどは、長期的には保持されない短期的なデータです。 企業は、分析を実行した後、どのデータを保持し、どのデータを破棄するかを決定する必要があります。 また、保持されるデータは、ビジネスおよび規制ポリシーに従って保護する必要があります。
エッジコンピューティングの実装
エッジコンピューティングは、紙の上では簡単に見えるかもしれない簡単なアイデアですが、凝集戦略を開発し、エッジで健全な展開を実装することは困難な練習になる可能性があります。
成功したテクノロジー展開の最初の重要な要素は、意味のあるビジネスと技術的なエッジ戦略の作成です。 このような戦略は、ベンダーやギアを選ぶことではありません。 代わりに、エッジ戦略はエッジコンピューティングの必要性を考慮します。 「理由」を理解するには、ネットワークの制約の克服やデータ主権の観察など、組織が解決しようとしている技術的およびビジネス上の問題を明確に理解

このような戦略は、エッジが何を意味するのか、ビジネスのために存在するのか、組織にどのように利益をもたらすのかについての議論 エッジ戦略は、既存の事業計画や技術ロードマップと整合する必要があります。 たとえば、ビジネスが集中型データセンターのフットプリントを削減しようとする場合、エッジとその他の分散コンピューティングテクノロジは
プロジェクトが実装に近づくにつれて、ハードウェアとソフトウェアのオプションを慎重に評価することが重要です。 エッジコンピューティングスペースには、Adlink Technology、Cisco、Amazon、Dell EMC、HPEなど、多くのベンダーがあります。 各製品の提供は、コスト、パフォーマンス、機能、相互運用性、およびサポートについて評価する必要があります。 ソフトウェアの観点から見ると、ツールはリモートエッジ環境の包括的な可視性と制御を提供する必要があります。
エッジコンピューティングイニシアチブの実際の展開は、ユーティリティの上に戦闘で硬化したエンクロージャ内のいくつかのローカルコンピューテ 2つのエッジ展開は同じではありません。 エッジの戦略と計画をエッジプロジェクトの成功に非常に重要にするのは、これらのバリエーションです。
エッジ展開では、包括的な監視が必要です。 ITスタッフを物理的なエッジサイトに移動させることは困難、あるいは不可能である可能性があるため、エッジ展開は、回復力、耐障害性、自己修復機能を提供するように設計されるべきであることに注意してください。 監視ツールは、リモート展開の明確な概要を提供し、簡単なプロビジョニングと構成を可能にし、包括的なアラートとレポートを提供し、インストールとそのデー エッジ監視には、多くの場合、サイトの可用性や稼働時間、ネットワークパフォーマンス、ストレージ容量と使用率、コンピューティングリソースなど、一連のメトリクスとKpiが含まれます。
そして、エッジのメンテナンスを慎重に考慮しなければ、エッジの実装は完了しません。
- セキュリティ。 物理的および論理的なセキュリティ上の予防措置は不可欠であり、脆弱性管理と侵入検知と防止を重視するツールを含む必要があります。 すべてのデバイスはアクセスやハッキングが可能なネットワーク要素であり、驚くほど多くの攻撃面が存在するため、セキュリティはセンサーやIoTデバ
- 接続性。 接続性は別の問題であり、実際のデータの接続が利用できない場合でも、制御とレポートへのアクセスのための準備を行う必要があります。 一部のエッジ展開では、バックアップ接続と制御にセカンダリ接続を使用します。
- 管理。 エッジ展開のリモートで、多くの場合、無愛想な場所は、リモートプロビジョニングと管理が不可欠になります。 IT管理者は、エッジで何が起こっているのかを確認し、必要に応じて展開を制御できる必要があります。
- 物理的なメンテナンス。 物理的な保守要件を見落とすことはできません。 IoTデバイスは、多くの場合、定期的なバッテリやデバイスの交換で寿命が限られています。 ギアは故障し、最終的にはメンテナンスと交換が必要です。 実用的な場所の兵站学は維持と含まれていなければならない。
エッジコンピューティング、IoTと5Gの可能性
エッジコンピューティングは、その機能とパフォーマンスを向上させるために、新しい技術や慣行を使用して、進化を続けています。 おそらく最も注目すべき傾向はエッジの可用性であり、エッジサービスは2028年までに世界中で利用可能になると予想されています。 エッジコンピューティングは、多くの場合、状況に固有の今日では、技術は、よりユビキタスになり、エッジ技術のためのより多くの抽象化と潜在的なユースケースをもたらし、インターネットが使用されている方法をシフトすることが期待されています。
これは、エッジコンピューティング用に特別に設計されたコンピューティング、ストレージ、ネットワークアプライアンス製品の より多くのマルチベンダーパートナーシップにより、エッジでの製品の相互運用性と柔軟性が向上します。 例には、エッジへの接続性を向上させるためのAWSとVerizonのパートナーシップが含まれています。
5GやWi-Fi6などのワイヤレス通信技術は、今後数年間でエッジの展開と利用にも影響を与え、車両の自律性やエッジへのワークロードの移行など、未検討の仮想化と自動化機能を可能にし、ワイヤレスネットワークをより柔軟で費用対効果の高いものにします。
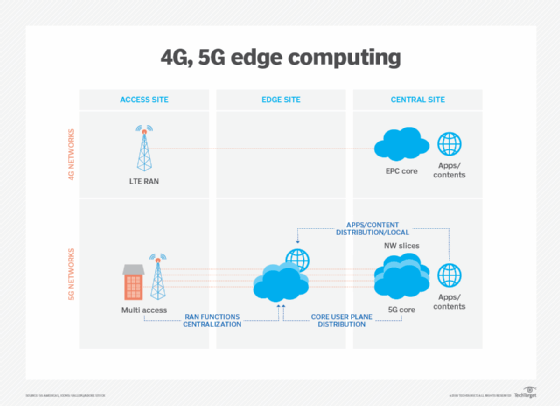
エッジコンピューティングは、IoTの上昇と、そのようなデバイスが生成するデータの突然の供給過剰で注目を集めました。 しかし、IoT技術はまだ初期段階にあるため、IoTデバイスの進化は、エッジコンピューティングの将来の発展にも影響を与えます。 このような将来の選択肢の一例は、マイクロモジュラーデータセンター(Mmdc)の開発です。 MMDCは基本的にボックス内のデータセンターであり、完全なデータセンターを小さなモバイルシステム内に配置し、都市や地域などのデータに近い場所に展開し、データにエッジを配置することなく、コンピューティングをデータに近づけることができます。