Edge computing er en distribueret informationsteknologi (IT) arkitektur, hvor klientdata behandles i periferien af netværket, så tæt på den oprindelige kilde som muligt.
Data er livsnerven i moderne forretning, der giver værdifuld forretningsindsigt og understøtter realtidskontrol over kritiske forretningsprocesser og operationer. Dagens virksomheder er oversvømmet i et hav af data, og enorme mængder data kan rutinemæssigt indsamles fra sensorer og IoT-enheder, der opererer i realtid fra fjerntliggende steder og uvurderlige driftsmiljøer næsten overalt i verden.
men denne virtuelle strøm af data ændrer også den måde, virksomheder håndterer computing på. Det traditionelle computerparadigme bygget på et centraliseret datacenter og dagligdags internet er ikke velegnet til at flytte uendeligt voksende floder af virkelige data. Båndbreddebegrænsninger, latensproblemer og uforudsigelige netværksforstyrrelser kan alle konspirere for at forringe en sådan indsats. Virksomheder reagerer på disse dataudfordringer ved hjælp af edge computing-arkitektur.
i enkleste termer flytter edge computing en del af lagrings-og beregningsressourcer ud af det centrale datacenter og tættere på selve datakilden. I stedet for at overføre rådata til et centralt datacenter til behandling og analyse, udføres dette arbejde i stedet, hvor dataene faktisk genereres-hvad enten det er en detailbutik, et fabriksgulv, et spredt værktøj eller på tværs af en smart by. Kun resultatet af det computerarbejde på kanten, såsom forretningsindsigt i realtid, forudsigelser om vedligeholdelse af udstyr eller andre Handlingsrettede svar, sendes tilbage til hoveddatacentret til gennemgang og andre menneskelige interaktioner.
således er edge computing omforme IT og business computing. Tag et omfattende kig på, hvad edge computing er, hvordan det virker, skyens indflydelse, edge use cases, afvejninger og implementeringsovervejelser.
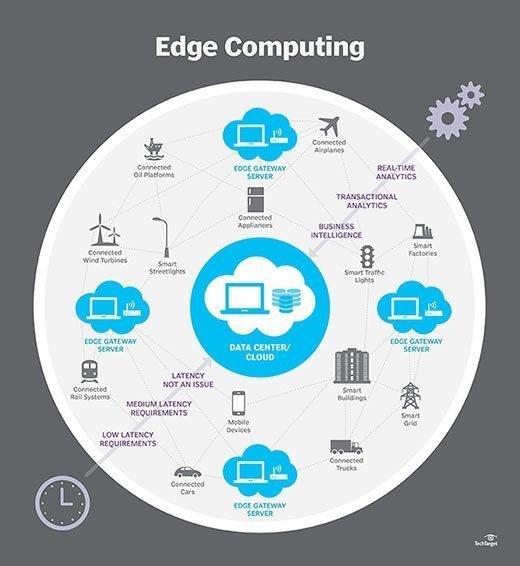
Hvordan fungerer edge computing?
Edge computing er alle et spørgsmål om placering. I traditionel enterprise computing produceres data på et klientendepunkt, såsom en brugers computer. Internettet, gennem virksomhedens LAN, hvor dataene gemmes og arbejdes på af en virksomhedsapplikation. Resultaterne af dette arbejde overføres derefter tilbage til klientens slutpunkt. Dette forbliver en gennemprøvet og tidstestet tilgang til klient-server computing til de fleste typiske forretningsapplikationer.
men antallet af enheder, der er forbundet til internettet, og mængden af data, der produceres af disse enheder og bruges af virksomheder, vokser alt for hurtigt til, at traditionelle datacenterinfrastrukturer kan rumme. Gartner forudsagde, at i 2025 vil 75% af virksomhedsgenererede data blive oprettet uden for centraliserede datacentre. Udsigten til at flytte så mange data i situationer, der ofte kan være tids – eller forstyrrelsesfølsomme, lægger en utrolig belastning på det globale internet, som i sig selv ofte er udsat for overbelastning og forstyrrelse.
så it-arkitekter har flyttet fokus fra det centrale datacenter til den logiske kant af infrastrukturen-taget lagrings-og computerressourcer fra datacentret og flyttet disse ressourcer til det punkt, hvor dataene genereres. Princippet er ligetil: hvis du ikke kan få dataene tættere på datacentret, skal du få datacentret tættere på dataene. Begrebet edge computing er ikke nyt, og det er forankret i årtier gamle ideer om fjerncomputing-såsom fjernkontorer og filialer-hvor det var mere pålideligt og effektivt at placere computerressourcer på det ønskede sted i stedet for at stole på en enkelt central placering.

Edge computing sætter opbevaring og servere, hvor dataene er, hvilket ofte kræver lidt mere end et delvist tandhjul til at fungere på det eksterne LAN for at indsamle og behandle dataene lokalt. I mange tilfælde anvendes computerudstyret i afskærmede eller hærdede kabinetter for at beskytte gearet mod ekstreme temperaturer, fugt og andre miljøforhold. Behandling involverer ofte normalisering og analyse af datastrømmen for at lede efter business intelligence, og kun resultaterne af analysen sendes tilbage til det primære datacenter.
ideen om business intelligence kan variere dramatisk. Nogle eksempler inkluderer detailmiljøer, hvor videoovervågning af udstillingslokalet kan kombineres med faktiske salgsdata for at bestemme den mest ønskelige produktkonfiguration eller forbrugernes efterspørgsel. Andre eksempler involverer forudsigelig analyse, der kan guide vedligeholdelse og reparation af udstyr, før der opstår faktiske mangler eller fejl. Stadig andre eksempler er ofte tilpasset forsyningsselskaber, såsom vandbehandling eller elproduktion, for at sikre, at udstyret fungerer korrekt og for at opretholde kvaliteten af output.
Edge vs. cloud vs. fog computing
Edge computing er tæt forbundet med begreberne cloud computing og fog computing. Selvom der er en vis overlapning mellem disse begreber, er de ikke det samme, og bør generelt ikke bruges om hverandre. Det er nyttigt at sammenligne begreberne og forstå deres forskelle.
en af de nemmeste måder at forstå forskellene mellem edge, cloud og fog computing er at fremhæve deres fælles tema: Alle tre koncepter vedrører distribueret computing og fokuserer på den fysiske implementering af beregne-og lagringsressourcer i forhold til de data, der produceres. Forskellen er et spørgsmål om, hvor disse ressourcer er placeret.
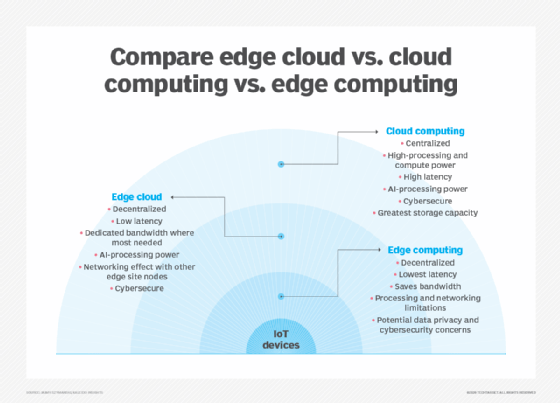
kant. Edge computing er implementeringen af computing og lagringsressourcer på det sted, hvor data produceres. Dette sætter ideelt beregning og opbevaring på samme punkt som datakilden ved netværkskanten. For eksempel kan et lille kabinet med flere servere og noget lager installeres oven på en vindmølle for at indsamle og behandle data produceret af sensorer i selve turbinen. Som et andet eksempel kan en jernbanestation placere en beskeden mængde beregning og opbevaring inden for stationen for at indsamle og behandle utallige spor-og jernbanetrafiksensordata. Resultaterne af en sådan behandling kan derefter sendes tilbage til et andet datacenter til menneskelig gennemgang, arkivering og flettes med andre dataresultater til bredere analyse.
Sky. Cloud computing er en enorm, meget skalerbar implementering af beregne-og lagringsressourcer på en af flere distribuerede Globale placeringer (regioner). Cloud-udbydere inkorporerer også et sortiment af færdigpakkede tjenester til IoT-operationer, hvilket gør skyen til en foretrukken centraliseret platform til IoT-implementeringer. Men selvom cloud computing tilbyder langt mere end nok ressourcer og tjenester til at tackle komplekse analyser, kan den nærmeste regionale skyfacilitet stadig være hundreder af miles fra det punkt, hvor data indsamles, og forbindelser er afhængige af den samme temperamentsfulde internetforbindelse, der understøtter traditionelle datacentre. I praksis er cloud computing et alternativ – eller nogle gange et supplement-til traditionelle datacentre. Skyen kan få centraliseret computing meget tættere på en datakilde, men ikke ved netværkskanten.
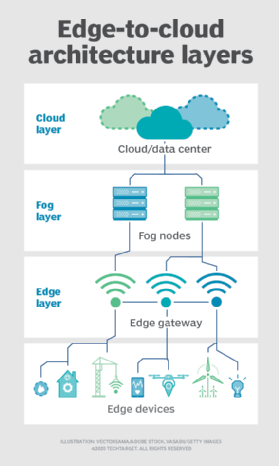
tåge. Men valget af implementering af beregning og opbevaring er ikke begrænset til skyen eller edge. Et cloud – datacenter kan være for langt væk, men edge-implementeringen kan simpelthen være for ressourcebegrænset eller fysisk spredt eller distribueret til at gøre streng edge computing praktisk. I dette tilfælde kan begrebet tåge computing hjælpe. Fog computing tager typisk et skridt tilbage og sætter beregne-og lagringsressourcer “inden for” dataene, men ikke nødvendigvis “på” dataene.Fog computing-miljøer kan producere forvirrende mængder sensor-eller IoT-data genereret på tværs af ekspansive fysiske områder, der bare er for store til at definere en kant. Eksempler inkluderer smarte bygninger, smarte byer eller endda smarte forsyningsnet. Overvej en smart by, hvor data kan bruges til at spore, analysere og optimere det offentlige transportsystem, kommunale forsyningsselskaber, bytjenester og guide langsigtet byplanlægning. En enkelt kant implementering er simpelthen ikke nok til at håndtere en sådan belastning, så fog computing kan betjene en række tåge node implementeringer inden for rammerne af miljøet for at indsamle, behandle og analysere data.Bemærk: Det er vigtigt at gentage, at fog computing og edge computing deler en næsten identisk definition og arkitektur, og udtrykkene bruges undertiden ombytteligt selv blandt teknologieksperter.
hvorfor betyder edge computing noget?
computeropgaver kræver passende arkitekturer, og den arkitektur, der passer til en type computeropgave, passer ikke nødvendigvis til alle typer computeropgaver. Edge computing er opstået som en levedygtig og vigtig arkitektur, der understøtter distribueret computing til at implementere beregne-og lagringsressourcer tættere på-ideelt på samme fysiske placering som-datakilden. Generelt er distribuerede computermodeller næppe nye, og begreberne fjernkontorer, filialer, datacenter colocation og cloud computing har en lang og dokumenteret track record.men decentralisering kan være udfordrende og kræve høje niveauer af overvågning og kontrol, der let overses, når man bevæger sig væk fra en traditionel centraliseret computermodel. Edge computing er blevet relevant, fordi det giver en effektiv løsning på nye netværksproblemer forbundet med at flytte enorme mængder data, som nutidens organisationer producerer og forbruger. Det er ikke kun et problem med beløb. Det er også et spørgsmål om tid; applikationer afhænger af behandling og svar, der i stigende grad er tidsfølsomme.
overvej stigningen i selvkørende biler. De vil afhænge af intelligente trafikstyringssignaler. Biler og trafikkontroller bliver nødt til at producere, analysere og udveksle data i realtid. Multiplicer dette krav med et stort antal autonome køretøjer, og omfanget af de potentielle problemer bliver tydeligere. Det kræver et hurtigt og responsivt netværk. Edge – og fog-computing adresserer tre vigtigste netværksbegrænsninger: båndbredde, latenstid og overbelastning eller pålidelighed.
- båndbredde. Båndbredde er mængden af data, som et netværk kan bære over tid, normalt udtrykt i bits per sekund. Alle netværk har en begrænset båndbredde, og grænserne er mere alvorlige for trådløs kommunikation. Dette betyder, at der er en endelig grænse for mængden af data-eller antallet af enheder-der kan kommunikere data på tværs af netværket. Selvom det er muligt at øge netværksbåndbredden for at rumme flere enheder og data, kan omkostningerne være betydelige, der er stadig (højere) endelige grænser, og det løser ikke andre problemer.
- Latency. Latency er den tid, der er nødvendig for at sende data mellem to punkter på et netværk. Selvom kommunikation ideelt set finder sted med lysets hastighed, kan store fysiske afstande kombineret med netværksbelastning eller strømafbrydelser forsinke databevægelsen på tværs af netværket. Dette forsinker alle analyser og beslutningsprocesser og reducerer et systems evne til at reagere i realtid. Det kostede endda liv i det autonome køretøjseksempel.
- overbelastning. Internettet er dybest set et globalt “netværk af netværk.”Selvom det har udviklet sig til at tilbyde gode generelle dataudvekslinger til de fleste daglige computeropgaver-såsom filudveksling eller grundlæggende streaming-kan mængden af data, der er involveret i titusindvis af enheder, overvælde Internettet og forårsage høje niveauer af overbelastning og tvinge tidskrævende dataudsendelser. I andre tilfælde kan netværksafbrydelser forværre overbelastning og endda afbryde kommunikationen til nogle internetbrugere helt – hvilket gør Internet of things ubrugelig under afbrydelser.ved at implementere servere og lagring, hvor dataene genereres, kan edge computing betjene mange enheder over et meget mindre og mere effektivt LAN, hvor rigelig båndbredde udelukkende bruges af lokale datagenererende enheder, hvilket gør latenstid og overbelastning næsten ikke-eksisterende. Lokal lagring indsamler og beskytter rådataene, mens lokale servere kan udføre vigtige kantanalyser-eller i det mindste forbehandle og reducere dataene-for at træffe beslutninger i realtid, før de sender resultater eller bare vigtige data til skyen eller det centrale datacenter.
Edge computing use cases og eksempler
i princippet bruges edge computing-teknikker til at indsamle, filtrere, behandle og analysere data “på plads” på eller nær netværkskanten. Det er et kraftfuldt middel til at bruge data, der ikke først kan flyttes til et centraliseret sted-normalt fordi den store mængde data gør sådanne bevægelser omkostningsbegrænsende, teknologisk upraktiske eller på anden måde kan krænke overholdelsesforpligtelser, såsom datasuverænitet. Denne definition har skabt utallige virkelige eksempler og brugssager:
- fremstilling. En industriel producent implementerede edge computing til at overvåge produktionen, hvilket muliggør analyse i realtid og maskinindlæring i kanten for at finde produktionsfejl og forbedre produktproduktionskvaliteten. Edge computing understøttede tilføjelsen af miljøsensorer i hele produktionsanlægget og gav indsigt i, hvordan hver produktkomponent samles og opbevares-og hvor længe komponenterne forbliver på lager. Producenten kan nu træffe hurtigere og mere nøjagtige forretningsbeslutninger vedrørende fabriksfaciliteten og fremstillingsoperationerne.
- landbrug. Overvej en virksomhed, der dyrker afgrøder indendørs uden sollys, jord eller pesticider. Processen reducerer væksttider med mere end 60%. Brug af sensorer gør det muligt for virksomheden at spore vandforbrug, næringsstoftæthed og bestemme optimal høst. Data indsamles og analyseres for at finde virkningerne af miljøfaktorer og løbende forbedre afgrødedyrkningsalgoritmerne og sikre, at afgrøder høstes i topform.
- netværk optimering. Edge computing kan hjælpe med at optimere netværksydelsen ved at måle ydeevnen for brugere på tværs af internettet og derefter anvende analyser til at bestemme den mest pålidelige netværkssti med lav latenstid for hver brugers trafik. I virkeligheden bruges edge computing til at” styre ” trafik på tværs af netværket for optimal tidsfølsom trafikydelse.
- sikkerhed på arbejdspladsen. Edge computing kan kombinere og analysere data fra kameraer på stedet, medarbejdersikkerhedsanordninger og forskellige andre sensorer for at hjælpe virksomheder med at overvåge arbejdspladsforholdene eller sikre, at medarbejderne følger etablerede sikkerhedsprotokoller-især når arbejdspladsen er fjern eller usædvanlig farlig, såsom byggepladser eller olierigge.
- forbedret sundhedspleje. Sundhedsindustrien har dramatisk udvidet mængden af patientdata indsamlet fra enheder, sensorer og andet medicinsk udstyr. Den enorme datavolumen kræver edge computing for at anvende automatisering og maskinlæring for at få adgang til dataene, ignorere “normale” data og identificere problemdata, så klinikere kan tage øjeblikkelig handling for at hjælpe patienter med at undgå sundhedshændelser i realtid.
- transport. Autonome køretøjer kræver og producerer alt fra 5 TB til 20 TB om dagen, indsamling af oplysninger om placering, hastighed, køretøjets tilstand, vejforhold, trafikforhold og andre køretøjer. Og dataene skal aggregeres og analyseres i realtid, mens køretøjet er i bevægelse. Dette kræver betydelig indbygget computing-hvert autonomt køretøj bliver en ” kant.”Derudover kan dataene hjælpe myndigheder og virksomheder med at styre køretøjsflåder baseret på faktiske forhold på jorden.
- detailhandel. Detailvirksomheder kan også producere enorme datamængder fra overvågning, lagersporing, salgsdata og andre forretningsoplysninger i realtid. Edge computing kan hjælpe med at analysere disse forskellige data og identificere forretningsmuligheder, såsom en effektiv endcap eller kampagne, forudsige salg og optimere leverandørbestilling osv. Da detailvirksomheder kan variere dramatisk i lokale miljøer, kan edge computing være en effektiv løsning til lokal behandling i hver butik.
fordele ved edge computing
Edge computing adresserer vitale infrastrukturudfordringer-såsom båndbreddebegrænsninger, overskydende latenstid og netværksbelastning-men der er flere potentielle yderligere fordele ved edge computing, der kan gøre tilgangen tiltalende i andre situationer.
autonomi. Edge computing er nyttig, hvor forbindelsen er upålidelig, eller båndbredden er begrænset på grund af stedets miljømæssige egenskaber. Eksempler inkluderer olierigge, skibe til søs, fjerntliggende gårde eller andre fjerntliggende steder, såsom en regnskov eller ørken. Edge computing udfører beregningsarbejdet på stedet-nogle gange på selve edge-enheden-såsom vandkvalitetssensorer på vandrensere i fjerntliggende landsbyer og kan kun gemme data til transmission til et centralt punkt, når der er forbindelse. Ved at behandle data lokalt kan mængden af data, der skal sendes, reduceres kraftigt, hvilket kræver langt mindre båndbredde eller tilslutningstid, end det ellers ville være nødvendigt.
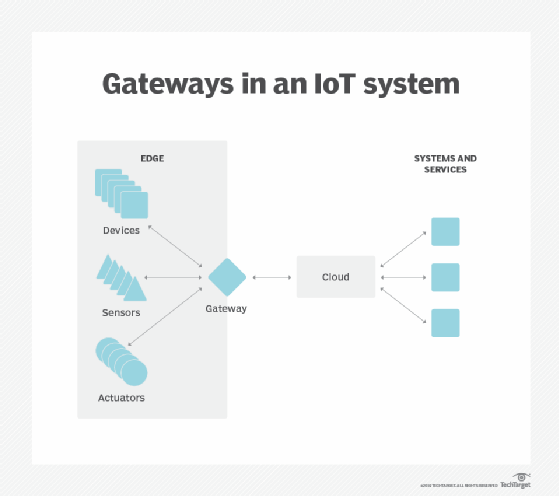
Edge-enheder omfatter en bred vifte af enhedstyper, herunder sensorer, aktuatorer og andre endepunkter samt IoT-porte. datasuverænitet. Flytning af enorme mængder data er ikke kun et teknisk problem. Datas rejse på tværs af nationale og regionale grænser kan udgøre yderligere problemer for datasikkerhed, privatliv og andre juridiske spørgsmål. Edge computing kan bruges til at holde data tæt på kilden og inden for rammerne af gældende datasuverænitetslove, såsom Den Europæiske Unions GDPR, der definerer, hvordan data skal opbevares, behandles og eksponeres. Dette kan gøre det muligt at behandle rådata lokalt, skjule eller sikre følsomme data, før du sender noget til skyen eller det primære datacenter, som kan være i andre jurisdiktioner.
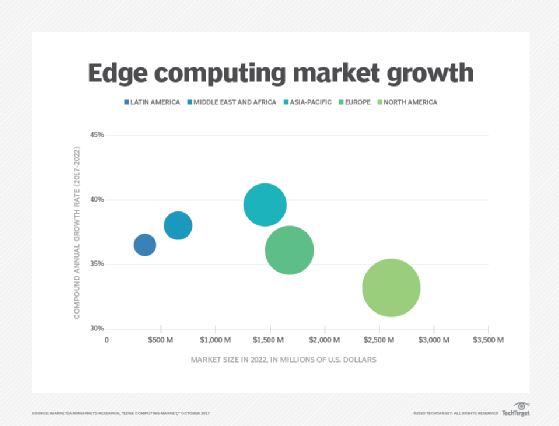
forskning viser, at bevægelsen mod edge computing kun vil stige i løbet af de næste par år. Edge sikkerhed. Endelig giver edge computing en ekstra mulighed for at implementere og sikre datasikkerhed. Selvom skyudbydere har IoT-tjenester og specialiserer sig i kompleks analyse, forbliver virksomheder bekymrede over sikkerheden og sikkerheden ved data, når de forlader kanten og rejser tilbage til skyen eller datacentret. Ved at implementere computing at the edge kan alle data, der krydser netværket tilbage til skyen eller datacentret, sikres gennem kryptering, og selve edge-implementeringen kan hærdes mod hackere og andre ondsindede aktiviteter-selv når sikkerheden på IoT-enheder forbliver begrænset.
udfordringer ved edge computing
selvom edge computing har potentialet til at give overbevisende fordele på tværs af en lang række brugssager, er teknologien langt fra idiotsikker. Ud over de traditionelle problemer med netværksbegrænsninger er der flere vigtige overvejelser, der kan påvirke vedtagelsen af edge computing:
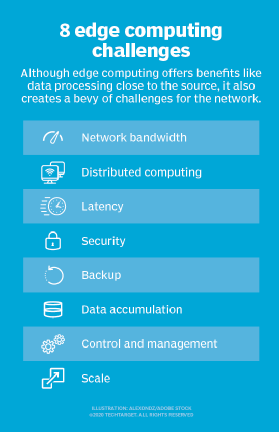
- begrænset kapacitet. En del af den lokke, som cloud computing bringer til edge-eller fog-computing, er mangfoldigheden og omfanget af ressourcerne og tjenesterne. Implementering af en infrastruktur ved kanten kan være effektiv, men omfanget og formålet med edge-implementeringen skal være klart defineret-selv en omfattende edge computing-implementering tjener et specifikt formål i en forudbestemt skala ved hjælp af begrænsede ressourcer og få tjenester.
- forbindelse. Edge computing overvinder typiske netværksbegrænsninger, men selv den mest tilgivende edge-implementering kræver et minimumsniveau af forbindelse. Det er vigtigt at designe en edge-implementering, der rummer dårlig eller uregelmæssig forbindelse og overveje, hvad der sker ved kanten, når forbindelsen går tabt. Autonomi, AI og yndefuld fejlplanlægning i kølvandet på forbindelsesproblemer er afgørende for en vellykket edge computing.
- sikkerhed. IoT-enheder er notorisk usikre, så det er vigtigt at designe en edge computing-implementering, der vil understrege korrekt enhedsstyring, såsom politikdrevet konfigurationshåndtering, samt sikkerhed i computing-og lagringsressourcerne-herunder faktorer som programrettelse og opdateringer-med særlig opmærksomhed på kryptering i dataene i hvile og under flyvning. IoT-tjenester fra store skyudbydere inkluderer sikker kommunikation, men dette er ikke automatisk, når man bygger et edge-sted fra bunden.
- data livscyklus. Det flerårige problem med dagens dataglut er, at så meget af disse data er unødvendigt. Overvej en medicinsk overvågningsenhed – det er bare problemdataene, der er kritiske, og der er ikke noget punkt i at holde dage med normale patientdata. De fleste af de data, der er involveret i realtidsanalyse, er kortsigtede data, der ikke opbevares på lang sigt. En virksomhed skal beslutte, hvilke data der skal opbevares, og hvad der skal kasseres, når analyser er udført. Og de data, der opbevares, skal beskyttes i overensstemmelse med forretnings-og lovgivningsmæssige politikker.
Edge computing implementering
Edge computing er en ligetil ide, der kan se let ud på papir, men at udvikle en sammenhængende strategi og implementere en lydinstallation ved kanten kan være en udfordrende øvelse.
det første vigtige element i enhver vellykket teknologiudrulning er oprettelsen af en meningsfuld forretnings-og teknisk kantstrategi. En sådan strategi handler ikke om at vælge leverandører eller udstyr. I stedet overvejer en edge-strategi behovet for edge computing. At forstå “hvorfor” kræver en klar forståelse af de tekniske og forretningsmæssige problemer, som organisationen forsøger at løse, såsom at overvinde netværksbegrænsninger og observere datasuverænitet.

et edge datacenter kræver omhyggelig planlægning og migrationsstrategier på forhånd. sådanne strategier kan starte med en diskussion af, hvad kanten betyder, hvor den findes for virksomheden, og hvordan den skal gavne organisationen. Edge-strategier bør også være i overensstemmelse med eksisterende forretningsplaner og teknologiske køreplaner. For eksempel, hvis virksomheden søger at reducere sit centraliserede datacenterfodaftryk, kan edge og andre distribuerede computerteknologier muligvis tilpasse sig godt.
da projektet bevæger sig tættere på implementeringen, er det vigtigt at evaluere udstyrs-og programmelindstillingerne omhyggeligt. Der er mange leverandører i edge computing plads, herunder Adlink teknologi, Cisco,
, Dell EMC og HPE. Hvert produktudbud skal evalueres for omkostninger, ydeevne, funktioner, interoperabilitet og support. Fra et programmelperspektiv skal værktøjer give omfattende synlighed og kontrol over fjernkantmiljøet. den faktiske implementering af et edge computing-initiativ kan variere dramatisk i omfang og skala, lige fra noget lokalt computerudstyr i et kamphærdet kabinet oven på et værktøj til et stort udvalg af sensorer, der fodrer en netværksforbindelse med høj båndbredde og lav latenstid til den offentlige sky. Ingen to kantinstallationer er ens. Det er disse variationer, der gør edge-strategi og planlægning så kritisk for edge-projektets succes.
en edge-implementering kræver omfattende overvågning. Husk, at det kan være svært-eller endda umuligt-at få IT-personale til det fysiske edge-sted, så edge-implementeringer skal arkitekteres for at give modstandsdygtighed, fejltolerance og selvhelbredende evner. Overvågningsværktøjer skal give et klart overblik over fjerninstallationen, muliggøre nem klargøring og konfiguration, tilbyde omfattende alarmering og rapportering og opretholde sikkerheden for installationen og dens data. Edge overvågning involverer ofte en række målinger og KPI ‘ er, såsom Site tilgængelighed eller oppetid, netværk ydeevne, lagerkapacitet og udnyttelse, og beregne ressourcer.og ingen edge implementering ville være komplet uden en omhyggelig overvejelse af edge vedligeholdelse:
- sikkerhed. Fysiske og logiske sikkerhedsforanstaltninger er vigtige og bør omfatte værktøjer, der lægger vægt på sårbarhedsstyring og detektering og forebyggelse af indtrængen. Sikkerhed skal udvides til sensor-og IoT-enheder, da enhver enhed er et netværkselement, der kan tilgås eller hackes-og præsenterer et forvirrende antal mulige angrebsflader.
- forbindelse. Forbindelse er et andet problem, og der skal træffes bestemmelser om adgang til kontrol og rapportering, selv når forbindelsen til de faktiske data ikke er tilgængelig. Nogle edge-implementeringer bruger en sekundær forbindelse til sikkerhedskopiering og kontrol.
- Ledelse. De fjerntliggende og ofte ugæstfrie placeringer af edge-implementeringer gør fjernforsyning og styring vigtig. IT-ledere skal være i stand til at se, hvad der sker ved kanten og være i stand til at kontrollere implementeringen, når det er nødvendigt.
- fysisk vedligeholdelse. Krav til fysisk vedligeholdelse kan ikke overses. IoT-enheder har ofte begrænset levetid med rutinemæssige batteri-og enhedsudskiftninger. Gearet svigter og kræver i sidste ende vedligeholdelse og udskiftning. Praktisk stedlogistik skal inkluderes i vedligeholdelse.
Edge computing, IoT og 5G muligheder
Edge computing fortsætter med at udvikle sig ved hjælp af nye teknologier og praksis for at forbedre dets evner og ydeevne. Måske er den mest bemærkelsesværdige tendens edge-tilgængelighed, og edge-tjenester forventes at blive tilgængelige over hele verden inden 2028. Hvor edge computing ofte er situationsspecifik i dag, forventes teknologien at blive mere allestedsnærværende og ændre den måde, hvorpå internettet bruges, hvilket bringer flere abstraktions-og potentielle brugssager til edge-teknologi.
dette kan ses i udbredelsen af computer -, lagrings-og netværksapparatprodukter, der er specielt designet til edge computing. Flere multivendor partnerskaber vil muliggøre bedre produkt interoperabilitet og fleksibilitet på kanten. Et eksempel inkluderer et partnerskab mellem AV og Veronica for at bringe bedre forbindelse til kanten.
trådløse kommunikationsteknologier, såsom 5G og trådløs internetadgang 6, vil også påvirke edge-implementeringer og-udnyttelse i de kommende år, hvilket muliggør virtualiserings-og automatiseringsfunktioner, der endnu ikke er udforsket, såsom bedre køretøjsautonomi og arbejdsbyrde-migrationer til edge, samtidig med at Trådløse netværk bliver mere fleksible og omkostningseffektive.
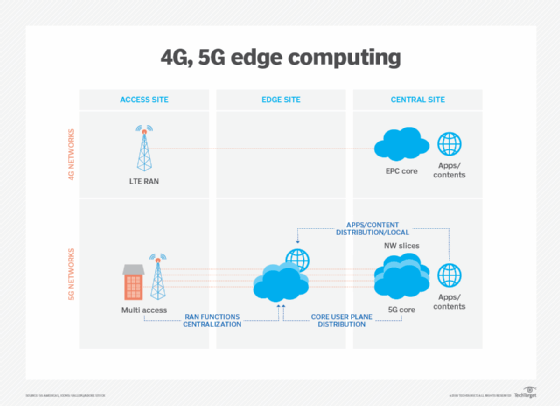
dette diagram viser detaljeret om, hvordan 5g giver betydelige fremskridt for edge computing og core netværk over 4G og LTE kapaciteter. Edge computing fik besked med stigningen i IoT og den pludselige overflod af data, som sådanne enheder producerer. Men med IoT-teknologier, der stadig er i relativ barndom, vil udviklingen af IoT-enheder også have indflydelse på den fremtidige udvikling af edge computing. Et eksempel på sådanne fremtidige alternativer er udviklingen af mikromodulære datacentre (MMDC ‘ er). MMDC er dybest set et datacenter i en kasse, der sætter et komplet datacenter i et lille mobilsystem, der kan implementeres tættere på data-såsom på tværs af en by eller en region-for at få computing meget tættere på data uden at sætte kanten på de rigtige data.